【手撕系列】手撕Transformer
Categories: Code
目录
- 概览
- 一、从零构建Transformer模型
- 二、使用从零构建的Transformer模型完成中英翻译demo
- 三、PyTorch封装的Transformer用法
- 四、使用PyTorch封装的Transformer模型完成中英翻译demo
- 参考链接
本文代码放在:https://github.com/WKQ9411/transformer-from-scratch,如果对您有所帮助,欢迎star!🌟
概览
Transformer 模型的核心思想是利用注意力机制来捕捉输入序列中的全局依赖关系,取代传统的循环神经网络(RNN)和长短期记忆网络(LSTM),其整体结构如下图:
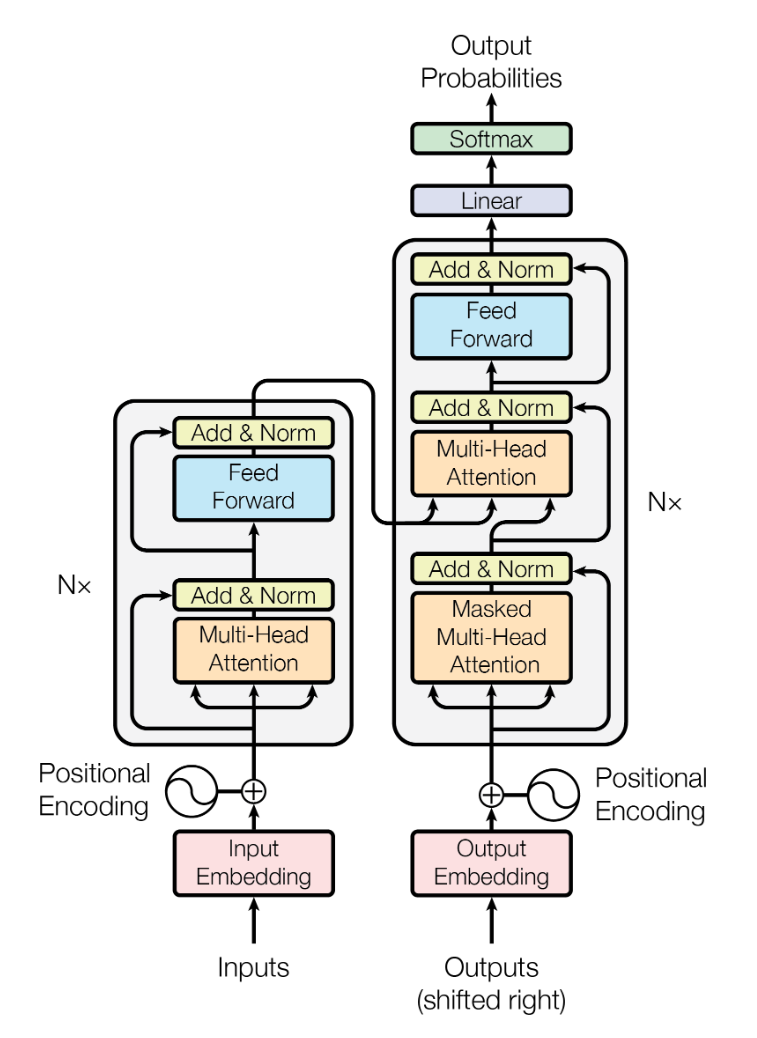
本文主要包括以下内容:
- 从零构建Transformer模型
- 使用从零构建的Transformer模型完成中英翻译demo
- PyTorch封装的Transformer用法
- 使用PyTorch封装的Transformer模型完成中英翻译demo
一、从零构建Transformer模型
(一)模型的输入和输出
在实现机器翻译任务时,Transformer模型的输入是下方的Inputs和Outputs。模型的输出是右上方的Outputs Probabilities,如下图所示:
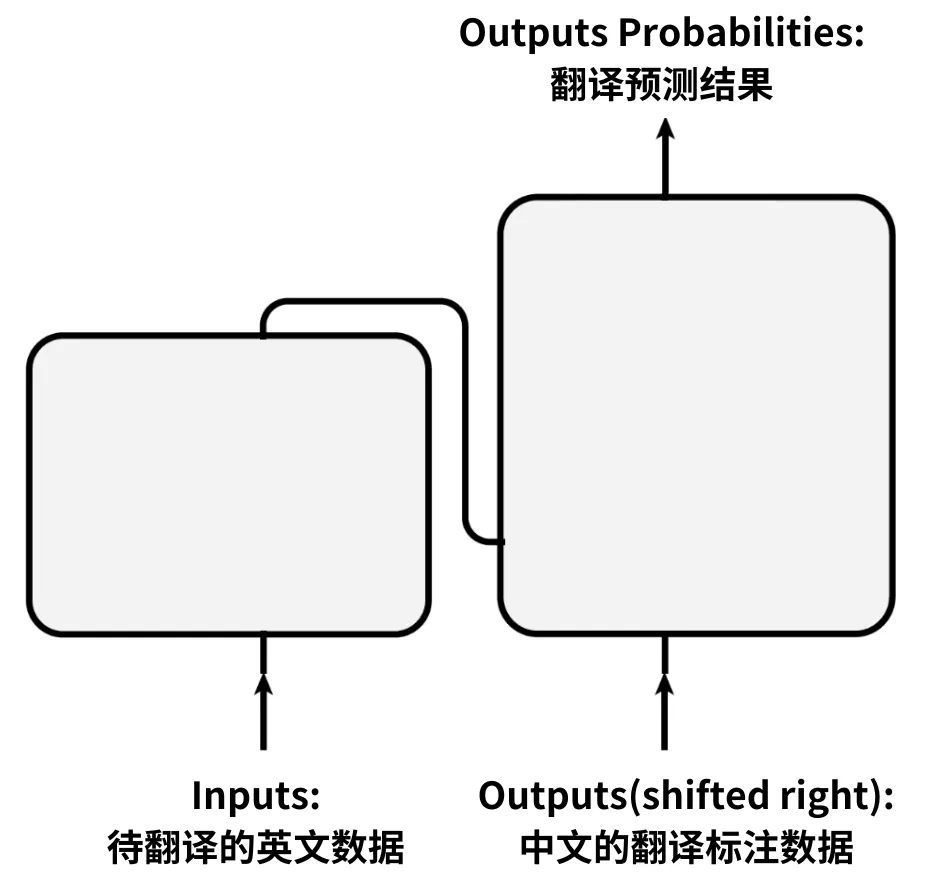
例如,在进行英译汉机器翻译任务时:
输入包括了两个部分:
- 待翻译的英文数据
- 中文的翻译标注数据
它们分别从下方的Inputs和Outputs进入模型。经过模型的处理和计算,模型的翻译预测结果,会从右上方的Outputs Probabilities位置输出。下图中输出为“你干什么?”,代表模型的预测结果,这表示模型的预测和标注数据“你好吗?”可能存在偏差。
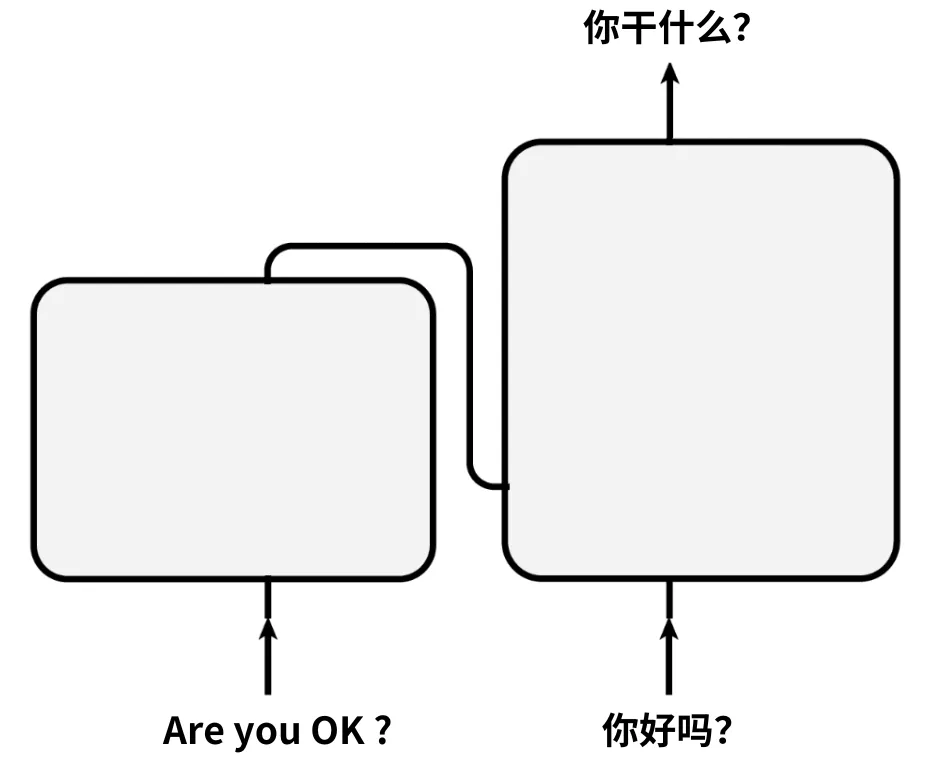
当英文句子“Are you OK ?”和中文标注“你好吗?”,进入模型后,会被Transformer中的第一个组件,词向量层,进行处理。单词序列会被转为单词向量的序列:
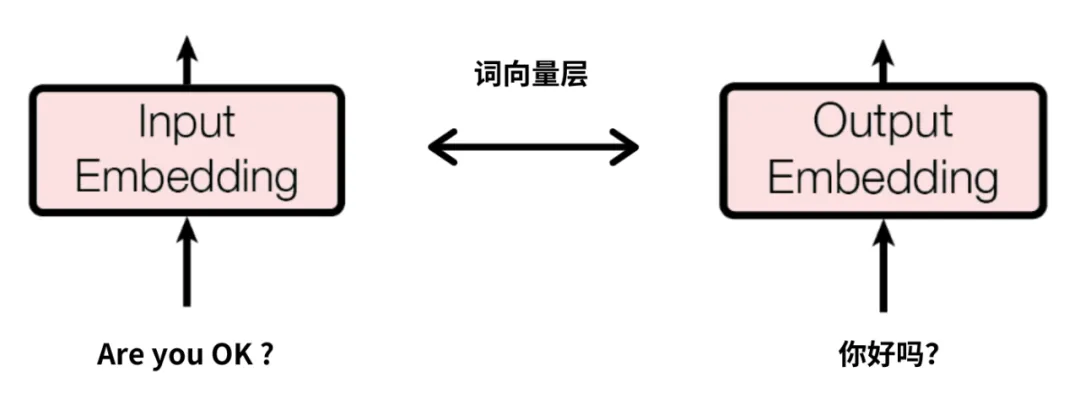
假设每个单词用4维的向量表示,那么,四个词的句子“Are you OK ?”,就会被转换为4*4的词向量矩阵,每行对应一个单词。

同理,中文标注“你/好吗/?”也会进行类似的处理,它被转换为了的3*4的词向量矩阵。

具体过程是:
- “你好吗?”首先经过分词器进行分词,分解成“你”、“好吗”、“?”三个单词,即序列长度为 seq_len=3 ,当然,根据分词器的不同,也可能会分成“你”、“好”、“吗”、“?”四个单词,分出的每个单词,我们称为 token;
- 然后我们会建立一个字典,将每个单词映射为一个唯一的整数,比如“你”对应0,“好吗”对应1,“?”对应2,这个数字在后面我们称为 token_id,这样“你好吗?”就可以用 token_id 表示为 [0, 1, 2];
- 最后,每一个 token_id 会被 Embedding 层转换为连续的向量,这个向量被称为嵌入,我们以 d_model 来表示嵌入的维度。
- 因此,词向量矩阵的 形状为 (seq_len, d_model)。
(二)位置编码
1.原理部分
得到Input和Output的词向量后,Transformer会对这些向量进行“位置编码”,目的是,将 位置信息 “附加”到原始的信息上。
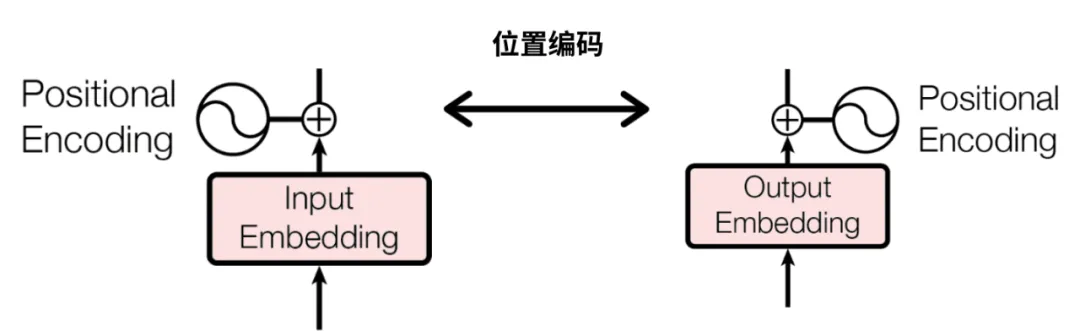
在位置编码前,“Are you OK ?”,对应的4×4的词向量矩阵,其中每行表示一个单词
如果将这个矩阵,直接输入至模型,模型是感受不到不同词语之间的顺序的。位置编码会用正弦函数和余弦函数的计算来实现。总的来说,要给 单词向量矩阵中的每个元素,都进行编码。
位置编码具体公式如下(公式中的 $d$ 即 $d_{model}$ ):
\[\begin{aligned} PE_{(pos,2i)} & = \sin\left(\frac{pos}{10000^{2i/d} }\right) \\ PE_{(pos,2i+1)} & = \cos\left(\frac{pos}{10000^{2i/d} }\right) \end{aligned}\]首先回顾一下三角函数:
比如在$y=\sin(\omega x)$中,$\omega$是角频率,$x$是自变量,周期$T=2\pi/\omega$。在位置编码公式中,$\textcolor{red}{pos}$表示序列中某个单词的 位置索引,可以理解为三角函数的自变量$x$;$\textcolor{red}{\frac{1}{10000^{2i/d} }}$实际上充当了 不同的角频率,其中$\textcolor{red}{i}$用于索引embedding维度的奇偶,即$2i$和$2i+1$分别表示偶数位和奇数位的embedding索引,$i$越大,则角频率越小,即周期越长;$\textcolor{red}{d}$表示embedding的总维度数,即$d_{model}$。也就是说,对于embedding维度,偶数索引应用位置编码的 sin 函数,奇数索引应用位置编码的 cos 函数。
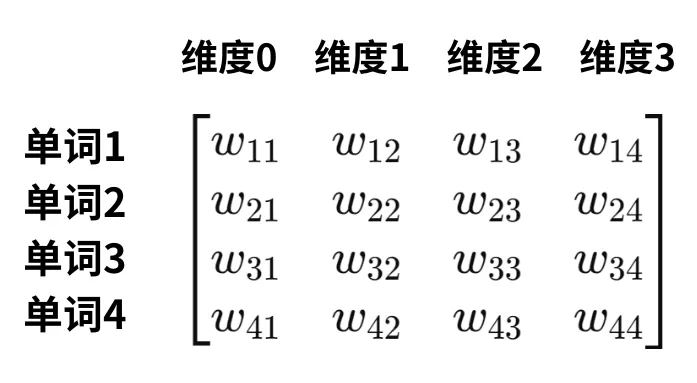
例如“Are you OK ?”中的4个单词的 $pos$ :Are对应了0;you对应了1;OK对应了2;?对应了3,下图的矩阵便是单词向量矩阵每个元素的位置编码,包含了4行,对应4个单词;每行有4列,对应4个维度。从纵向来看,相同的维度具有相同的角频率,即$\omega$相同,位置$pos$则作为角频率为$\omega$的三角函数的自变量。从横向来看,偶数索引的维度用正弦sin计算;奇数索引的维度用cos计算。
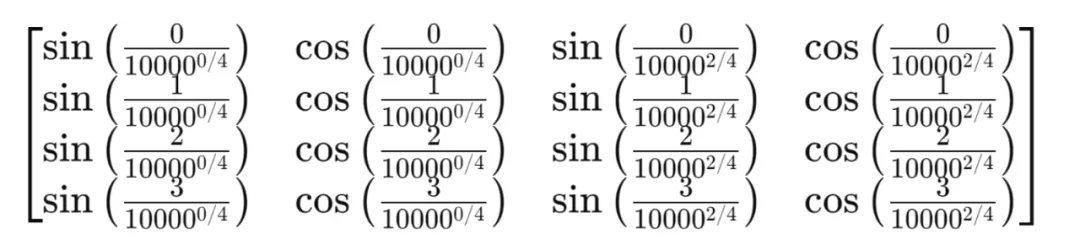
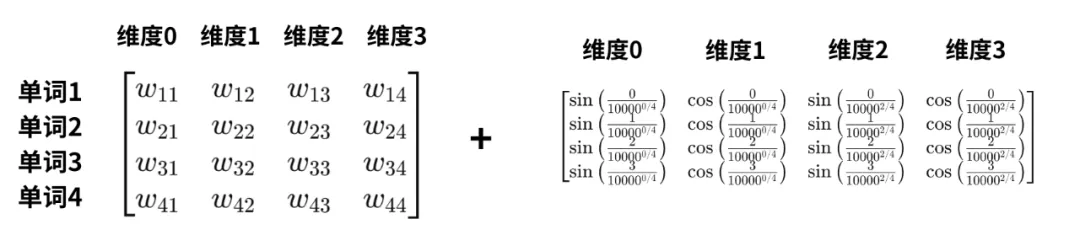
最终,将这个位置编码矩阵,直接加到原始的词向量矩阵中:
让我们来可视化一下不同维度的角频率是怎样的。假设$d$是 64,则 角频率的曲线($y=\frac{1}{10000^{2i/64} }$)如下所示,由于$i$只能从 0 取到一半的 64,即 32,因此角频率的值在 0-1 之间,最大值为 1,最小值为 1/10000:
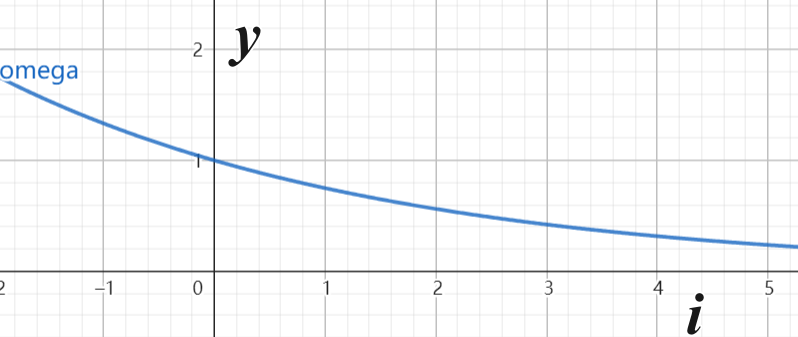
思考: 为什么这样的位置编码是唯一的? 不同维度的编码肯定会存在周期的最小公倍数,从而使位置编码出现一样的值?
位置编码的原理类似下图,可以看到每个维度(每一列)其实都是有周期的,并且周期是不同的。维度0到维度3变化率逐渐变慢,并且可以看出,当序列长度为16时,4个维度的编码刚好一个周期,因此 这样的编码仅对于长度小于16的序列是唯一的。
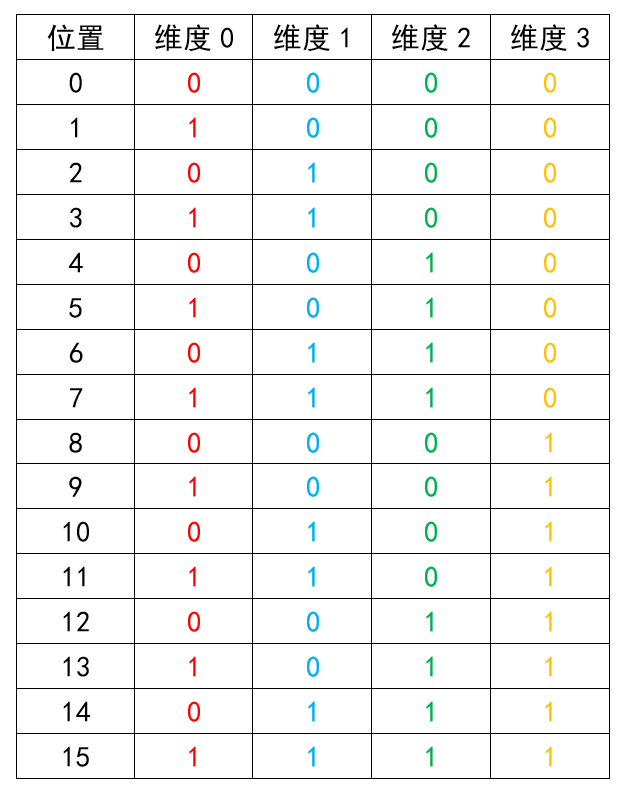
因此,Transformer原文中的位置编码,理论上当序列长度极大时,存在编码重复的情况。然而,实际中几乎不会出现这样的情况,基于以下几点:
- 在位置编码中,频率的选择是基于$\frac{1}{10000^{2i/d_{model} }}$,这些频率变化得非常缓慢,导致周期的最小公倍数变得非常大,从而减少了重复的可能性。 理论上$i$最高可以取值为$d_{model}/2$,此时$\omega$最小,即变化率最慢,周期最长,为$2\pi/\omega=2\pi*10000\approx62,831.85$。
- 位置编码采用的频率并不是简单的整数倍数关系,因此周期的最小公倍数也会变得非常大。这样,序列必须非常长才可能遇到重复的位置编码。
2.代码部分
位置编码类的实现需说明一点:
原文中提到:In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of $P_{drop}=0.1$。即输入加上位置编码后,应用了dropout,且整个模型的基础dropout都设置为0.1。
以下代码在实现位置编码时,没有加上这一dropout,而是在:(四)4.完整的Transformer 中才加入的。详细的注释均在代码中:
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=500):
"""
为序列加入位置编码
Args:
d_model: 序列矩阵的embedding的维度
max_len: 位置编码矩阵的最大序列长度, 这个长度可以比实际序列长度长, 相加时只要截取实际序列的长度即可
"""
super(PositionalEncoding, self).__init__()
self.d_model = d_model
pe = torch.zeros(max_len, d_model) # 创建一个(max_len, d_model)的全零矩阵, 用于保存位置编码值
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 创建一个(max_len, 1)的矩阵, 表示位置索引
# 创建一个(d_model/2,)的矩阵, 用于储存每个维度的频率因子(每两列的频率因子是相同的, 因此一共有d_model/2个频率因子)
# torch.arange(0, d_model, 2).float()相当于生成位置编码公式中的索引i
# 使用log和exp分开计算能够确保在数值范围内进行线性缩放, 从而避免浮点数溢出或精度丢失
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 计算位置编码
# 对于维度的偶数列
pe[:, 0::2] = torch.sin(position * div_term) # 由广播机制:(max_len, 1)*(d_model/2,)->(max_len, d_model/2)
# 对于维度的奇数列
pe[:, 1::2] = torch.cos(position * div_term)
# 增加一个batch维度, 使其能够与输入张量相加
pe = pe.unsqueeze(0) # (max_len, d_model)->(1, max_len, d_model)
# 将位置编码矩阵注册为模型的缓冲区, 这样它将不会被认为是模型的参数
# 缓冲区会随着模型一起保存和加载
self.register_buffer('pe', pe)
def forward(self, x):
"""
input: (batch_size, seq_len, d_model)
output: (batch_size, seq_len, d_model)
"""
# 原文3.4节中提到, 为了使得单词嵌入表示相对大一些, 乘sqrt(d_model), 以确保嵌入向量的值不会被位置编码淹没。
x = x * math.sqrt(self.d_model)
# 将位置编码添加到输入张量上
# 位置编码依据max_len生成, 而输入序列长度的seq_len应小于等于max_len
# 通常会将输入序列补全或截断到统一长度, 让这个长度等于max_len即可
x = x + self.pe[:, :x.size(1), :]
return x
位置编码类的使用和可视化
# 示例用法
d_model = 512 # 例如,模型的维度
pe = PositionalEncoding(d_model)
# 创建一个随机张量,形状为 (batch_size, seq_len, d_model)
x = torch.randn(32, 50, d_model)
# 添加位置编码
x = pe(x)
print(x.shape) # 应该输出 torch.Size([32, 50, 512])
# 获取位置编码矩阵
pe_matrix = pe.pe[0]
# 绘制位置编码矩阵
plt.figure(figsize=(12, 6))
plt.imshow(pe_matrix.detach().numpy(), aspect='auto', cmap='viridis')
plt.colorbar()
plt.title('Positional Encoding Matrix')
plt.xlabel('Embedding Dimension')
plt.ylabel('Position')
plt.show()
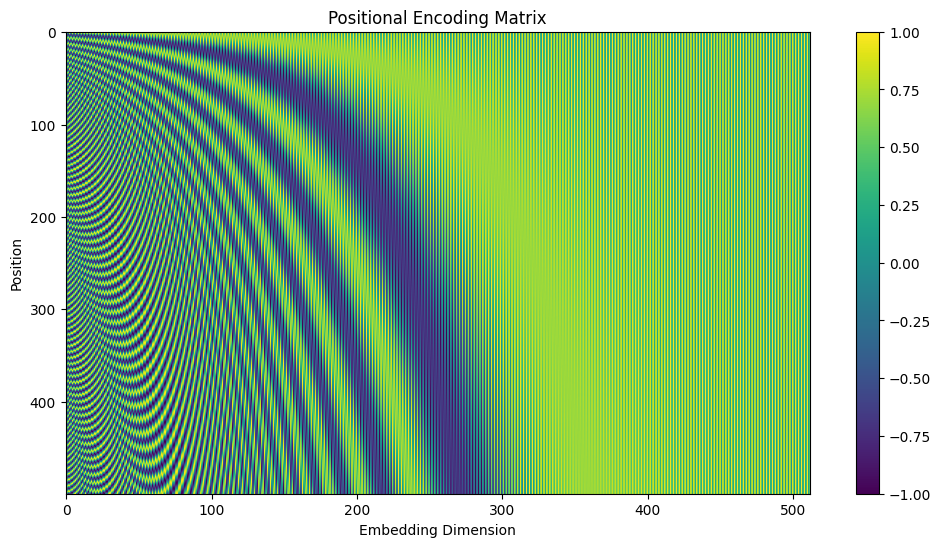
可视化结果如下:
(三)注意力机制
1.原理部分
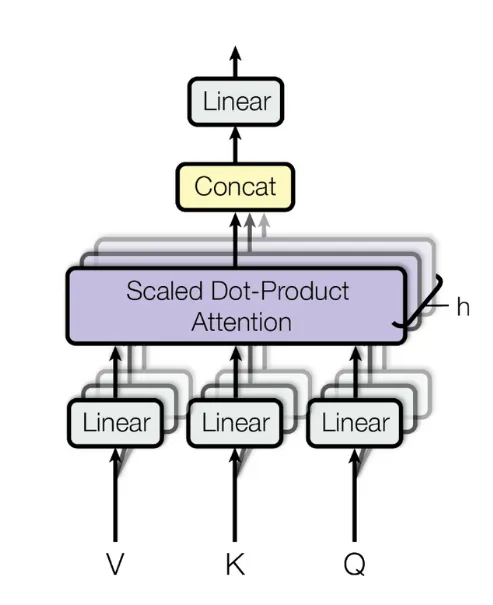
多头自注意力机制,英文是Muti-Head Self-Attention,是Transformer最核心的部分。其中“自注意力机制”,会分别使用Q、K、V三个线性层(Linear)对输入数据进行特征变换。
假设输入序列矩阵形状为 $n\times512$,其中 $n$ 是序列的 token 长度,512是 Embedding 的向量维度,若我们使用8个注意力头,那么8个头中的每一个头都只采用初始 Embedding 的向量长度 512 的 8 分之一来运算各自的 Attention,即通过把 Embedding 向量与$W^{Q}$,$W^{K}$,$W^{V}$三矩阵分别相乘之后,得到的向量长度为 64 维的向量。
当然,每次 Embedding 向量乘的$W^{Q}$,$W^{K}$,$W^{V}$这三矩阵,都是不同的,所以,严谨地说,应该用 $W_{i}^{Q}$,$W_{i}^{K}$,$W_{i}^{V}$( i = 8,即 head 数 )来表达。即一个 $n\times512$ 的序列矩阵转换成了8个 $n\times64$ 的。
所以,这相当于把 Embedding 向量作线性变换的同时,顺便把它“切”成了 8 份来运行。当然,这样的“切”并不是直接在一个长度为 512 的向量上等分 8 份,而是通过与$W^{Q}$,$W^{K}$,$W^{V}$三个矩阵分别相乘,线性变换而来的。【平分会切断完整的Embedding信息,而通过线性变换来降维,每一个头都的信息都来自于原Embedding的所有维,每一个头都从细分的语义子空间中去捕捉相关性】
(1)单头注意力的过程
- 将一个输入序列中其中一个 token 的 Embedding 向量线性变换出来的$Q_{i}$向量(下图图例中为$Q_{2}$)与同一序列中其他所有 token 的 Embedding 向量线性变换出来的$K_{i}$向量进行比较,计算两者之间的语义关联度得分(即原始论文中所说的点积相似度);
- 将这些语义关联度得分转换为权重值,权重数值的大小在 0~1 之间,数值接近 1 代表权重高,即语义逻辑很紧密。数值接近 0 代表权重低,语义逻辑无关。所有权重数值的总和为 1,即 Softmax 归一化;
- 然后,把 Softmax 后的权重值与每个 token 的 Embedding 向量线性变换出来的$V_i$做加权和,最终生成结果$Z_i$(图例中为$Z_2$)
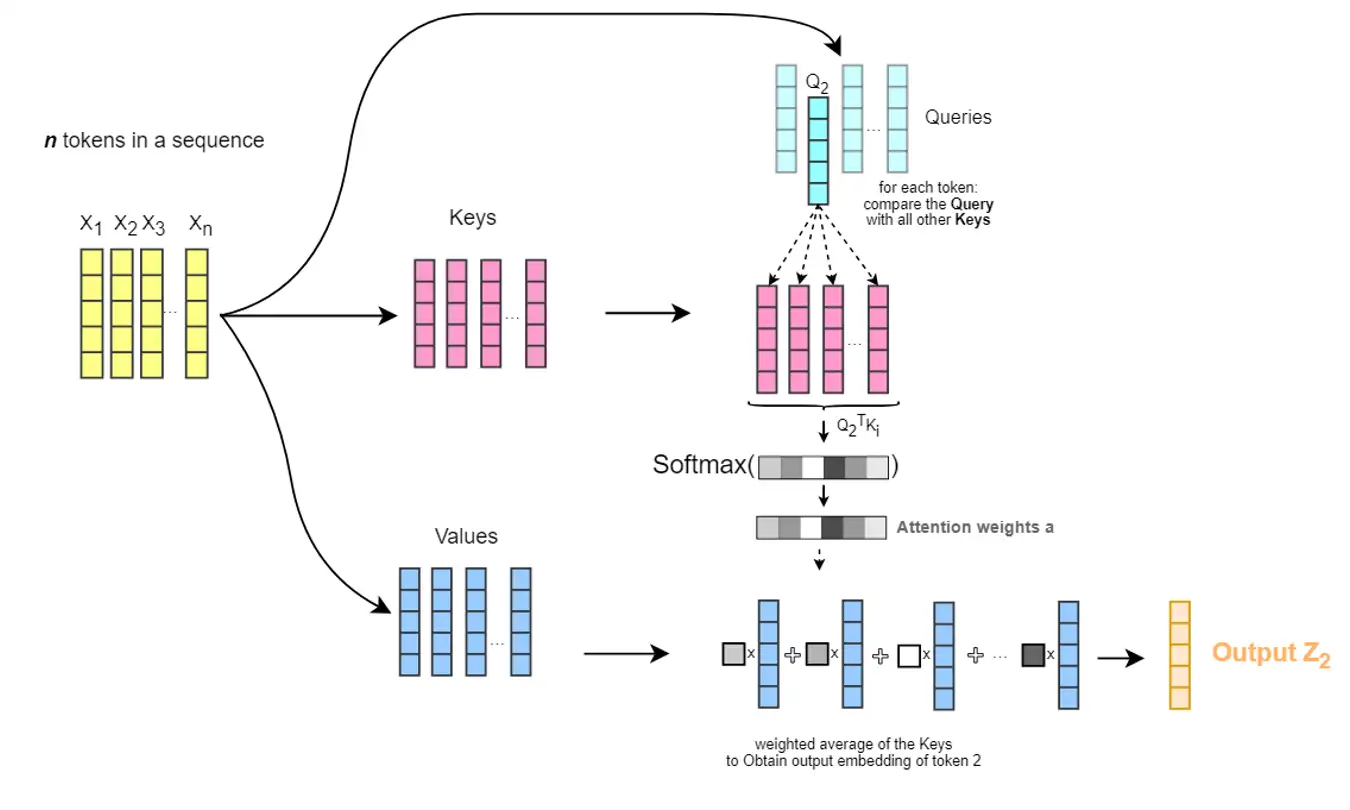
注意力计算表达式为:
\[\text{Attention}\left(Q,K,V\right)=\text{Softmax}\left(\frac{QK^T}{\sqrt{d_k} }\right)V\]$d_{k}$为$K$矩阵的维度,$Q$与$K$使用同样的维度,在这里,若$d_{model}$为 512,则$d_{k}=d_{model}/h=64$,$d_{model}$为整个 Transformer 模型中所有子层和 Embedding 层的统一的输出维度。$h$为 head 数,默认为 8。
(2)多头注意力的过程
Attention 机制(下图中左侧部分为 Attention 机制的架构图)实际上是被分配到了 8 个头 head 之中去分别运行了。每一个头在各自运行之后,再通过 Concat 把得到的结果链接起来,然后再做一次线性变换,变回初始的形状。
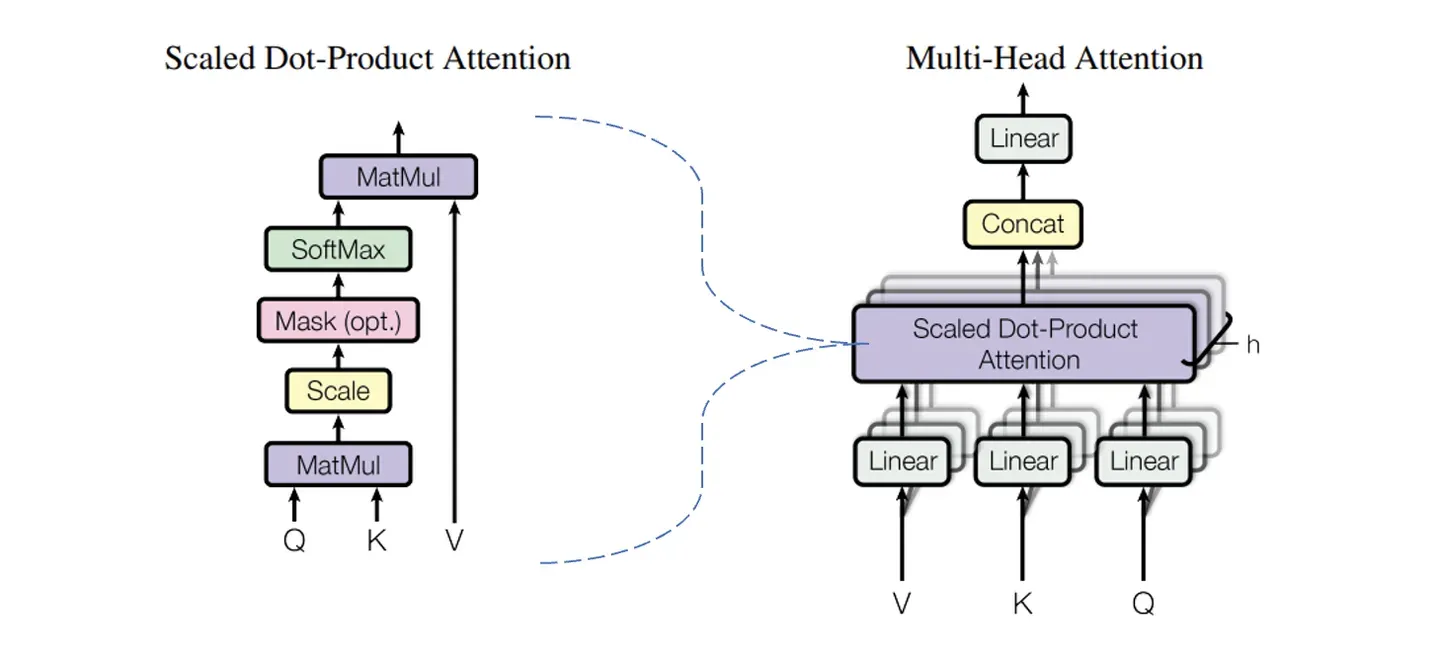
一个完整的 Embedding 被有机分割成 8 个子语义逻辑的“小Embedding”后进行运算,在运算完之后,便需要把 8 个被 Attention 变换后的“小Embedding”再有机组合成完整的 Embedding。分出 8个头 head 时,并非直接在物理层面上八等分切割 512 长度的 Embedding 到 64 长度,而是 通过线性变换得来的 8 个具有独立语义逻辑的子空间“小Embedding”。所以在 Multi-Head 运行结束后,首先将每个头的结果 Concat ,而后我们需要 通过$W^{O}$矩阵再做一次线性变换,即再把 8 个小的语义逻辑子空间有机地整合成一个总体的 Embedding。
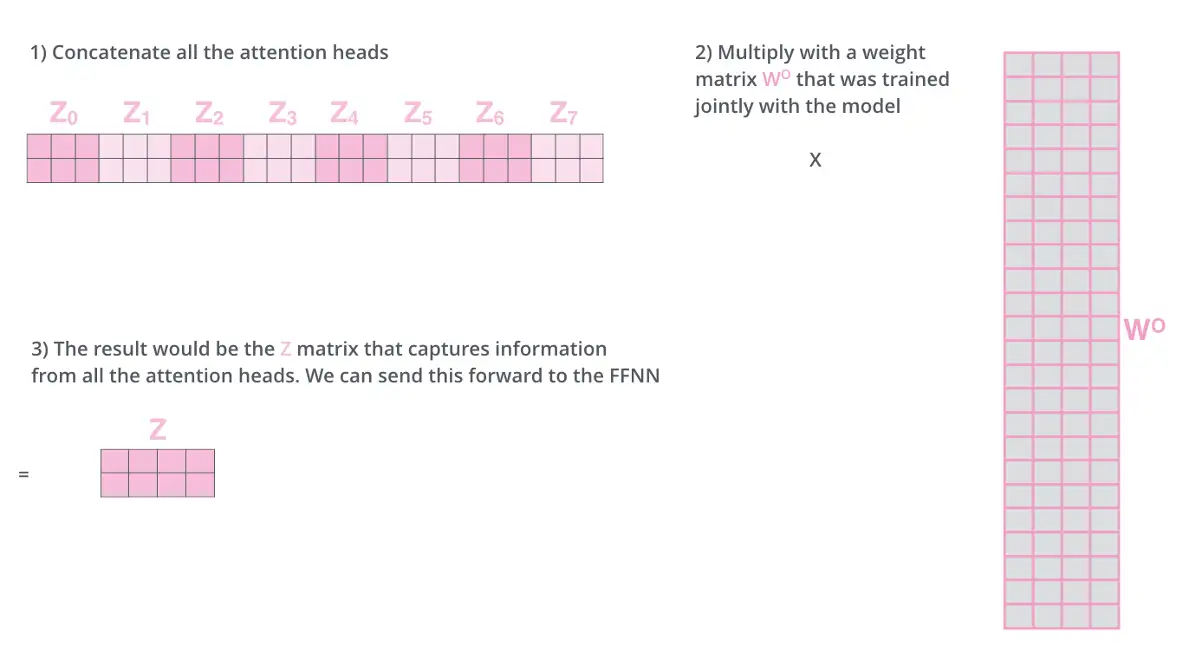
公式表达:
\[\mathrm{MultiHead}(Q,K,V)=\mathrm{Concat}(\mathrm{head}_1,...,\mathrm{head}_\mathrm{h})W^O \tag{①}\] \[\mathrm{where~head_i}=\mathrm{Attention}(QW_i^Q,KW_i^K,VW_i^V) \tag{②}\] \[\text{Attention}\left(Q,K,V\right)=\text{Softmax}\left(\frac{QK^T}{\sqrt{d_k} }\right)V \tag{③}\]其中,$W_i^Q\in\mathbb{R}^{d_{model}\times d_k},W_i^K\in\mathbb{R}^{d_{model}\times d_k},W_i^V\in\mathbb{R}^{d_{model}\times d_v}$,用于将原始序列矩阵$n \times d_{model}$映射为$n \times d_k$或$n \times d_v$;$W^{O}\in\mathbb{R}^{hd_{v}\times d_{\mathrm{model} }}$用于将拼接的多头转换为输出维度。
【注1】:$d_{model}$为整个 Transformer 模型中所有子层和 Embedding 层的输出维度,$d_{model} = 512$,$d_{k} = d_{q} = d_{model}/h = 64$,$d_{k}$与$d_{v}$在模型的执行阶段不用必须相等,可以取不同的值,$h$为 head 数,$h$默认为 8。
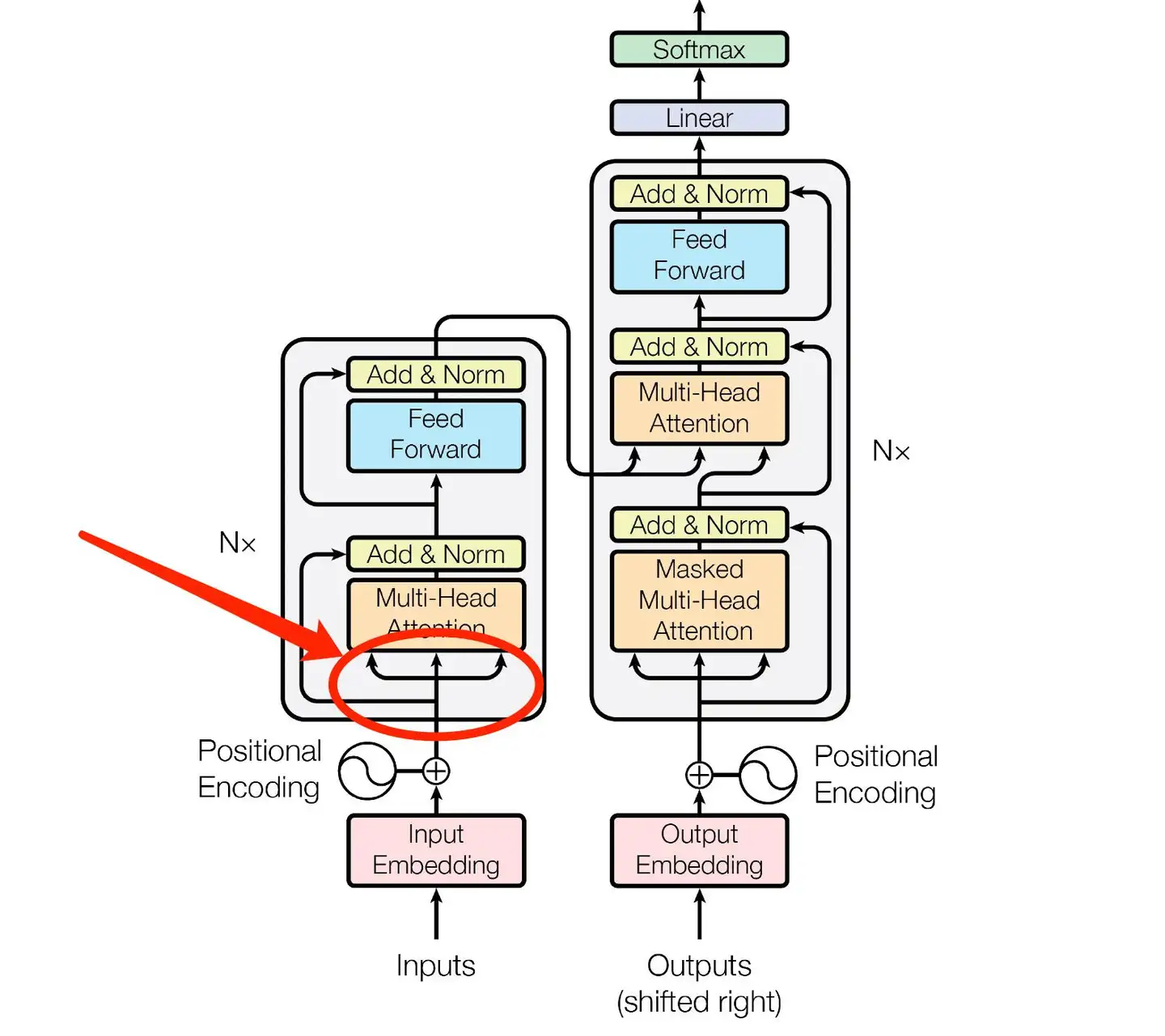
【注2】:①②③公式中的$Q$、$K$、$V$容易混淆,①②中的$Q$、$K$、$V$是一种名义上的称呼,如下图中红圈部分,他们实际上都是序列矩阵$X$本身。当然,这里说的是自注意力,如果对于交叉注意力,他们则是属于不同的序列矩阵。因此②实际可以写为$\mathrm{head_i}=\mathrm{Attention}(XW_i^Q,XW_i^K,XW_i^V)$。而③中的$Q$、$K$、$V$,是$X$经过$W_i^Q,W_i^K,W_i^V$线性变换后的。
🔥让我们走一个完整的例子:
- 首先定义参数,假设序列的长度为$n$;Embedding为$d_{model}$,即序列矩阵$X$的形状为$n\times d_{model}$;注意力头数为$h$,则$d_k=d_q=d_{model}/h$【因为二者相等,后面都用$d_k$来表示】;$d_v$可以等于$d_k$、$d_q$,也可以不等于。
-
每个头都有一个$W_i^Q\in\mathbb{R}^{d_{model}\times d_k},W_i^K\in\mathbb{R}^{d_{model}\times d_k}$的矩阵将$X$线性变换为$Q_i,K_i$,即:
\[\begin{aligned} Q_i=X{\times}W_i^Q,~(Q_i\in\mathbb{R}^{n\times d_k},X\in\mathbb{R}^{n\times d_{model} },W_i^Q\in\mathbb{R}^{d_{model}\times d_k}) \\ K_i=X{\times}W_i^K,~(K_i\in\mathbb{R}^{n\times d_k},X\in\mathbb{R}^{n\times d_{model} },W_i^K\in\mathbb{R}^{d_{model}\times d_k}) \end{aligned}\] - 将$Q_i$与$K_i^T$做点积,并进行 scale 和 softmax,即$softmax\left(\frac{Q_iK_i^T}{\sqrt{d_k} }\right)$,计算得到的相似度矩阵形状是$n\times n$。
-
类似第2步,$V_i$由下式而来:
\[V_i=X{\times}W_i^V,~(V_i\in\mathbb{R}^{n\times d_v},X\in\mathbb{R}^{n\times d_{model} },W_i^V\in\mathbb{R}^{d_{model}\times d_v})\]将第3步得到的相似度矩阵与$V_i$相乘,即得到 Attention 的结果,假设其为$Z_i$:
\[Z_i=\text{Softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_k} }\right)V_i,~(Z_i\in\mathbb{R}^{n\times d_v})\]这里便得到了一个头的输出结果$Z_i$。
- 以上2-4每个头都做一遍,产生$h$个$Z_i$,将他们拼接起来,得到$Z_{concat}\in\mathbb{R}^{n\times{hd_v} }$,然后使用$W^{O}\in\mathbb{R}^{hd_{v}\times d_{\mathrm{model} }}$将$Z_{concat}$变换成最终结果$Z\in\mathbb{R}^{n\times d_{model} }$,该输出形状与输入$X$形状相同。
- 一般情况下,$d_k$与$d_v$可设置为相同的,而$d_k$又由$d_{model}/h$得到,因此封装好后,只要设定注意力头数就好了。
2.代码部分
思考: 在代码实现上,为什么初始化时,qkv的linear是(d_model, d_model),而不是(d_model, d_k)?
多头的具体实现
这里通过如下过程来解释。假设有$h$个头,那么每个头有:
\[\begin{aligned} Q_1 & = XW_1^Q \\ Q_2 & = XW_2^Q \\ & \quad \vdots \\ Q_h &= XW_h^Q \end{aligned}\]其中$Q_i\in\mathbb{R}^{n\times d_k},X\in\mathbb{R}^{n\times d_{model} },W_i^Q\in\mathbb{R}^{d_{model}\times d_k}$,那么就有:
\[Q= \begin{bmatrix} Q_1\\Q_2\\\vdots\\Q_h \end{bmatrix}= X\begin{bmatrix} W_1^Q\\W_2^Q\\\vdots\\W_h^Q \end{bmatrix}=XW^Q\]其中 $Q\in\mathbb{R}^{n\times{(h\times d_k)} }\Rightarrow Q\in\mathbb{R}^{n\times d_{model} }, W^Q\in\mathbb{R}^{d_{model}\times{(h\times d_k)} }\Rightarrow W^Q\in\mathbb{R}^{d_{model}\times d_{model} }$,因此在代码实现上,直接定义了(d_model,d_model)的linear,一次性做了所有头的转换。
MultiheadAttention类的实现:
【注1】:q 的 seq_len 与 k, v 的 seq_len 可以不同。首先我们把 输入到编码器的序列定义为 source,即源序列;把 输入到解码器的序列定义为 target,即目标序列。对自注意力而言,q, k, v 都来自同一个序列,比如在编码器层中,q, k, v 都来自 source,因此他们的长度都是 src_seq_len,在解码器层中,q,k,v 都来自 target,因此他们的长度都是 tgt_seq_len。而在编码器-解码器层中,实现的是交叉注意力,q 来自 target,k, v 来自 source, 因此 q 的长度是 tgt_seq_len,而 k, v 的长度是 src_seq_len。
【注2】:在自然语言处理任务中,不同的句子或段落长度不同。为了在一个批次中处理不同长度的输入序列,通常会将所有序列填充到相同的长度。 填充掩码确保了模型只关注实际的有效序列部分,忽略填充部分。因此对于相同序列长度任务,可以不用填充,而如果对于不同长度序列任务,输入序列的 seq_len 应是统一填充后的长度。关于掩码的具体理解,将会在后面展开。
# 多头自注意力
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads" # 确保num_heads能整除d_model
self.d_model = d_model
self.d_k = d_model // num_heads # 这里简单起见,我们只考虑 d_v = d_k = d_q = d_model / num_heads,因此只定义d_k
self.h = num_heads
# 这里定义的 linear 参数是 (d_model, d_model)
self.q_linear = nn.Linear(d_model, d_model) # W_Q
self.k_linear = nn.Linear(d_model, d_model) # W_K
self.v_linear = nn.Linear(d_model, d_model) # W_V
self.o_linear = nn.Linear(d_model, d_model) # W_O
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
"""
input:
q, k, v: (batch_size, seq_len, d_model)
对于自注意力, 如果输入序列为 x, 那么 q=x, k=x, v=x
对于交叉注意力, 如果序列 x_1 对序列 x_2 做 query, 则 q=x_1, k=x_2, v=x_2
mask: (batch_size, 1, 1, seq_len)或(batch_size, 1, seq_len, seq_len)
mask有多种形式, 可以使用0、1来mask, 也可以使用True、False来mask, 根据具体代码执行mask
output:
seq: (batch_size, seq_len, d_model)
attention: (batch_size, h, len_q, len_k) 每个头均有一个注意力权重矩阵
对于自注意力, len_q = len_k = len_v = seq_len
对于交叉注意力, len_q = tgt_seq_len , len_k = len_v = src_seq_len
"""
batch_size = q.size(0)
# 将原始序列变换为QKV矩阵
# 以 q 的变换为例。序列 q=x 经过 q_linear 变换后,形状仍然为(batch_size, seq_len, d_model)
# 使用.view方法用于改变张量形状。这里变换成了(batch_size, seq_len, num_heads, d_k),即把 d_model 拆成了 num_heads*d_k
# 使用.transpose方法,将形状进一步变为(batch_size, num_heads, seq_len, d_k)
q = self.q_linear(q).view(batch_size, -1, self.h, self.d_k).transpose(1, 2) # (batch_size, seq_len, d_model)->(batch_size, num_heads, seq_len, d_k)
k = self.k_linear(k).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
v = self.v_linear(v).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
# 每个头并行计算相似度得分,相似度矩阵形状为(batch_size, num_heads, len_q, len_k)
# 即每个头都形成了(len_q, len_k)的 scores,scores 的第一行,意思是第一个位置的 q 对所有位置的 k 的得分,因此后续的 softmax 是按 scores 的行来做的
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
# 这里我们假设mask中为0的地方是需要遮蔽的地方
scores = scores.masked_fill(mask == 0, -1e9) # 通过把掩码的位置设置为一个较大的负数,让掩码位置的softmax趋近于零
attention = F.softmax(scores, dim=-1)
attention = self.dropout(attention) # 得到所有batch的每个头的相似度矩阵
# 相似度矩阵与v相乘得到输出
output = torch.matmul(attention, v) # (batch_size, num_heads, seq_len, d_k)
# 首先将output变为(batch_size, seq_len, num_heads, d_k)
# .contiguous用于确保张量在内存中是连续的
# 将张量形状变为(batch_size, seq_len, d_model),相当于把所有头的结果拼接了起来,即 d_k*num_heads 拼成了 d_model
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
output = self.o_linear(output) # 使用w_o进行线性变换
# 最终传出输出和每个头的attention,attention根据需要可用于后续的可视化
return output, attention
使用和可视化
# 示例用法
mha = MultiHeadAttention(d_model=512, num_heads=8)
x = torch.randn(32, 10, d_model) # 序列矩阵
output, attention = mha(x, x, x)
print(output.shape)
print(attention.shape)
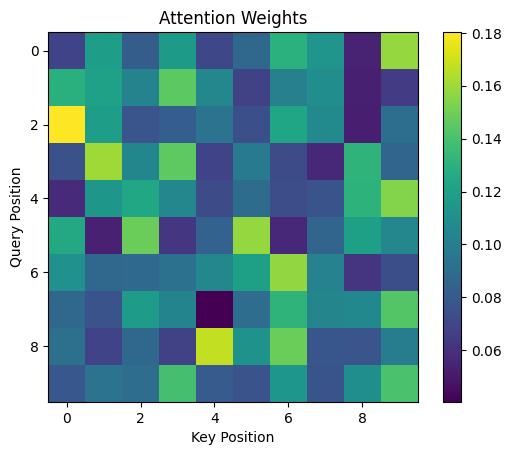
# 可视化第0个batch的第0个头的attention
head_attention = attention[0, 0].detach().numpy() # 提取第 0 个 batch 的第 0 个头
# 绘制热力图
plt.imshow(head_attention, cmap='viridis')
plt.colorbar()
plt.title('Attention Weights')
plt.xlabel('Key Position')
plt.ylabel('Query Position')
plt.show()
```输出结果如下:```python
torch.Size([32, 10, 512])
torch.Size([32, 8, 10, 10])
可视化结果如下:(因为是随机生成的,每次结果不一样)
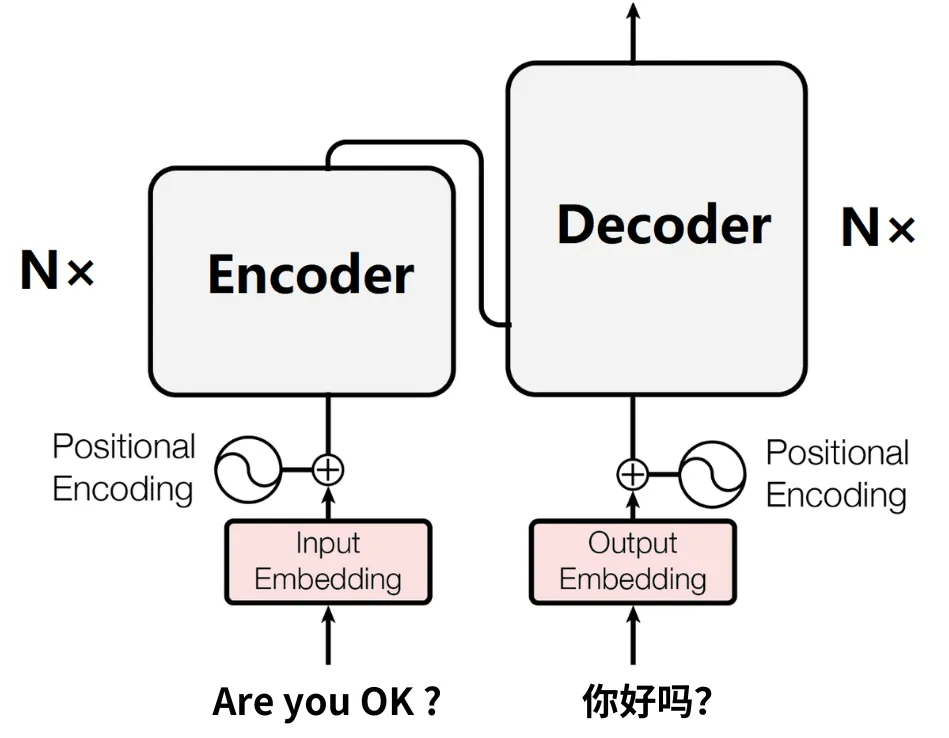
(四)编码器-解码器结构
经过位置编码后的“英文的待译数据”和“中文的标注数据”会分别从下方,进入左侧的编码器Encoder和右侧的解码器Decoder。
“英文的待译数据”和“中文的标注数据”,输入到编码器和解码器中后,会经过3个计算过程:
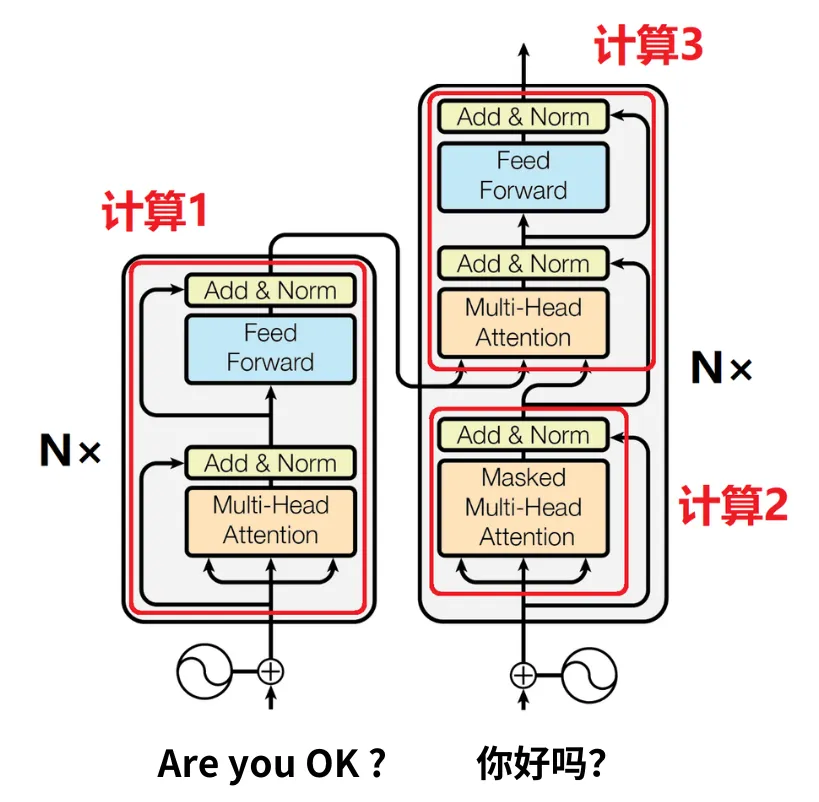
计算1:多头自注意力。编码器会基于自注意力机制和前馈神经网络对“英文的待译数据”进行编码。
计算2,掩码多头自注意力。解码器会基于 带有掩码 的自注意力机制对“中文的标注数据”进行编码。
计算3,编码器-解码器多头注意力。“待译英文的编码结果”和“标注中文的编码结果”会进入到解码器的第2个注意力层,也就是 “编码器-解码器注意力层”,这里$Q$来自于前一个解码器层,$K,V$来自于编码器的输出。这个层会对两组数据一起解码,得到解码器的最终输出。
其他一些层的实现:
1.前馈神经网络和层归一化
FeedForward 模块是一个简单的前馈神经网络,通常紧跟在多头注意力机制之后。它由两个线性层和一个激活函数组成,中间包含一个丢弃层(Dropout)以防止过拟合。
在前馈神经网络中,每个神经元处理的是$d_{model}$维度,即每个时间步独立地应用相同的前馈网络,这种处理方式意味着前馈神经网络在处理某个位置时,并不会直接使用来自其他位置的信息。因此,原文中的表述是:position-wise fully connected fee-forward network,这就是 position-wise 的含义。
代码实现:
# 前馈神经网络
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout=0.1):
super().__init__()
# d_ff 默认设置为 2048,更多的中间层节点数可以增加网络的容量,使其能够学习更复杂的函数映射。
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
"""
input: (batch_size, seq_len, d_model)
output: (batch_size, seq_len, d_model)
"""
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
return x
NormLayer 模块是一个层归一化层,用于对输入进行归一化处理。层归一化通过对每个样本的所有特征进行归一化,使得每个样本的特征具有相同的均值和标准差,对于一个(n, d_model)的序列,层归一化在每个位置对所有的d_model进行归一化。
层归一化的公式是:$\mathrm{LayerNorm}(x)=\gamma\cdot\frac{x-\mu}{\sqrt{\sigma^2+\epsilon} }+\beta$
- $x$是输入张量。
- $\mu$是$x$的均值。
- $\sigma^2$是$x$的方差。
- $\epsilon$是一个很小的数,防止除零错误。
- $\gamma$和$\beta$是可训练的参数,分别用于缩放和平移,恢复模型的表达能力。
# 层归一化, 也可以使用PyTorch内置的层归一化nn.LayerNorm
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-6):
super(LayerNorm, self).__init__()
self.a = nn.Parameter(torch.ones(d_model))
self.b = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
# LayerNorm是对d_model而言的
mean = x.mean(-1, keepdim=True) # (batch_size, seq_len, 1)
std = x.std(-1, keepdim=True) # (batch_size, seq_len, 1)
return self.a * (x - mean) / (std + self.eps) + self.b
2.EncoderLayer和Encoder
EncoderLayer类是Encoder的基本组成单元。原文中 Encoder 包括6个EncoderLayer,每个EncoderLayer包括两个子层:多头注意力层和前馈神经网络层。每个子层都使用了残差连接和层归一化。
每个子层的输出为:$\text{LayerNorm}(x+\text{Sublayer}(x))$,即先进行了add操作,再进行层归一化操作。同时,原文中提到:We apply dropout to the output of each sub-layer, before it is added to the sub-layer input and normalized,即子层输出还经过了dropout。
【PyTorch封装的Transformer中,提供了norm_first参数,也可以选择先norm再sublayer】
【所有涉及到mask的部分将在后面进行讨论】
# 编码器层
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff=2048, dropout=0.1):
"""
每个EncoderLayer包括两个子层: 多头注意力层和前馈神经网络层。每个子层都使用了残差连接和层归一化。
"""
super().__init__()
self.norm_1 = LayerNorm(d_model)
self.norm_2 = LayerNorm(d_model)
self.attn = MultiHeadAttention(d_model, num_heads, dropout=dropout)
self.ff = FeedForward(d_model, d_ff=d_ff, dropout=dropout)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x, src_mask=None):
"""
原文中使用: LayerNorm(x + SubLayer(x))
也有部分实现使用: x + SubLayer(LayerNorm(x))
这里我们使用原文的实现
input: (batch_size, seq_len, d_model)
output: (batch_size, seq_len, d_model)
"""
output, _ = self.attn(x, x, x, mask=src_mask)
x = self.norm_1(x + self.dropout_1(output)) # 多头自注意力子层
x = self.norm_2(x + self.dropout_2(self.ff(x))) # 前馈神经网络子层
return x
# 编码器
class Encoder(nn.Module):
"""
编码器由多个编码器层堆叠而成。
"""
def __init__(self, num_layers, d_model, num_heads, d_ff=2048, dropout=0.1):
"""
在原始论文的图 1 和描述中, 作者提到每个子层(Multi-Head Attention 和 Feed-Forward Network)之后会进行 Layer Normalization。
但是,论文并没有明确提到在整个编码器或解码器之后进行额外的 Layer Normalization。
许多后续的实现,通常会在编码器和解码器的堆叠之后再进行一次 Layer Normalization。
"""
super().__init__()
self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, src_mask=None):
"""
input: (batch_size, seq_len, d_model)
output: (batch_size, seq_len, d_model)
"""
for layer in self.layers:
x = layer(x, src_mask)
return self.norm(x)
3.DecoderLayer和Decoder
Decoder是 Transformer 模型中的解码器部分。解码器的主要作用是生成输出序列,例如在机器翻译任务中,解码器负责生成目标语言的句子。除了在Encoder中使用的两个子层外,还使用了编码器-解码器注意力层。第一个自注意力层输出的结果作为 q,Encoder的输出 enc_output 作为 k 和 v。
# 解码器层
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff=2048, dropout=0.1):
"""
每个DecoderLayer包括三个子层: 自注意力层、编码器-解码器注意力层和前馈神经网络层。每个子层都使用了残差连接和层归一化。
"""
super().__init__()
self.norm_1 = nn.LayerNorm(d_model)
self.norm_2 = nn.LayerNorm(d_model)
self.norm_3 = nn.LayerNorm(d_model)
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout=dropout)
self.enc_dec_attn = MultiHeadAttention(d_model, num_heads, dropout=dropout)
self.ff = FeedForward(d_model, d_ff=d_ff, dropout=dropout)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
self.dropout_3 = nn.Dropout(dropout)
def forward(self, x, enc_output, memory_mask=None, tgt_mask=None):
"""
input: (batch_size, seq_len, d_model)
output: (batch_size, seq_len, d_model)
"""
output_1, _ = self.self_attn(x, x, x, mask=tgt_mask)
x = self.norm_1(x + self.dropout_1(output_1)) # 第一个子层:多头自注意力层
output_2, _ = self.enc_dec_attn(x, enc_output, enc_output, mask=memory_mask) # k, v来自编码器输出
x = self.norm_2(x + self.dropout_2(output_2)) # 第二个子层:编码器-解码器注意力层
x = self.norm_3(x + self.dropout_3(self.ff(x))) # 第三个子层:前馈神经网络层
return x
# 解码器
class Decoder(nn.Module):
"""
解码器由多个解码器层堆叠而成。
"""
def __init__(self, num_layers, d_model, num_heads, d_ff=2048, dropout=0.1):
super().__init__()
self.layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, enc_output, memory_mask=None, tgt_mask=None):
"""
input: (batch_size, seq_len, d_model)
output: (batch_size, seq_len, d_model)
"""
for layer in self.layers:
x = layer(x, enc_output, memory_mask, tgt_mask)
return self.norm(x)
4.完整的Transformer
# 完整Transformer模型
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_layers=6, num_heads=8, d_ff=2048, dropout=0.1, max_len=500):
super().__init__()
# src_vocab_size和tgt_vocab_size分别是源序列和目标序列的词典大小
self.src_embedding = nn.Embedding(src_vocab_size, d_model) # 定义嵌入层,用于将序列转换为维度为d_model的嵌入向量
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_len) # 位置编码层
self.encoder = Encoder(num_layers, d_model, num_heads, d_ff, dropout)
self.decoder = Decoder(num_layers, d_model, num_heads, d_ff, dropout)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
"""
src和tgt为token_id
src: (batch_size, src_seq_len)
tgt: (batch_size, tgt_seq_len)
在 Transformer 模型中, 输入序列通常已经经过填充(padding)处理。
填充是为了使所有输入序列的长度一致,从而可以将它们放入一个批次中进行处理。
"""
src = self.dropout(self.positional_encoding(self.src_embedding(src))) # 位置编码后使用了dropout,原文在Regularization中有提到
tgt = self.dropout(self.positional_encoding(self.tgt_embedding(tgt)))
enc_output = self.encoder(src, src_mask)
dec_output = self.decoder(tgt, enc_output, memory_mask, tgt_mask)
# 在训练过程中,logits 通常会通过 CrossEntropyLoss 来计算损失,而 CrossEntropyLoss 会在内部应用 softmax
# 因此这里可以不用softmax,在推理阶段,可以在output后手动加入softmax
output = self.fc_out(dec_output)
return output
(五)理解mask
在 Transformer 模型中,掩码(mask)在编码器和解码器中都有重要的作用,用于处理填充令牌和控制注意力机制的范围。
根据mask应用 位置 的不同,可以分为:
- src_mask:应用于编码器多头自注意力的mask,对应源序列src
- tgt_mask:应用于解码器多头自注意力的mask,对应目标序列tgt
- memory_mask:应用于编码器-解码器交叉注意力的mask
根据mask实现 功能 的不同,可以分为:
- padding_mask:由于输入序列的长度可能不同,较短的序列会用填充令牌填充到相同的长度。为了避免在注意力计算中将填充令牌视为有效的输入,使用填充掩码来屏蔽这些填充令牌。具体的做法:把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过
Softmax后,这些位置的概率就会接近0。 - sequence_mask:也就是causal_mask,用于控制解码器中的自注意力机制,确保解码器在预测下一个词时只能看到当前词及其之前的词,而不能看到未来的词。具体的做法:产生一个下三角矩阵,上三角的部分全mask掉。把这个矩阵作用在注意力权重矩阵上,就可以达到目的。
在机器翻译任务中,源序列通常是直接给出的,因此src_mask和memory_mask都使用padding_mask即可,目标序列由于需要根据前面的输出来预测后续的输出,因此tgt_mask同时需要使用padding_mask和sequence_mask。
🔥看以下示例:
假设一个源序列为src="1234<PAD><PAD>",对应的目标序列为tgt="abcd<PAD>",这里通过<PAD>分别将序列长度补为6和5,即src和tgt的长度是不同的。我们分别看src_mask、tgt_mask、memory_mask是如何实现的。
1.src_mask
src_mask对应的是src序列,仅通过padding_mask来实现,其score矩阵如下图所示:
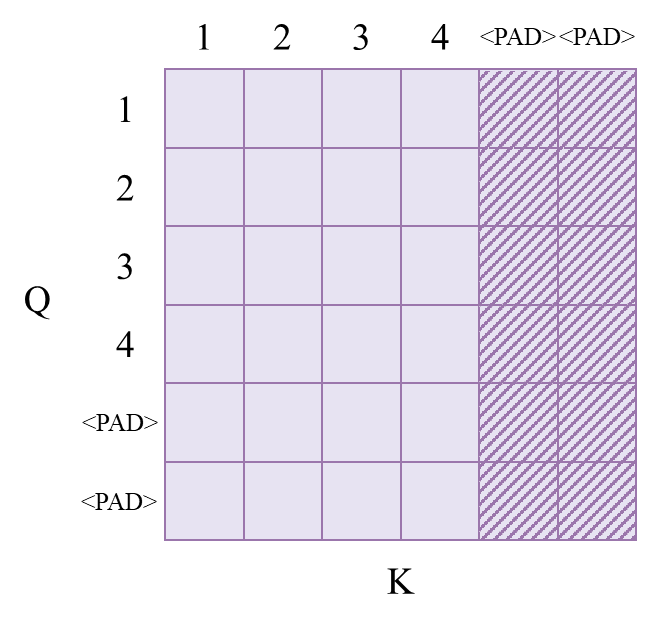
思考:由于是自注意力,Q和K的长度是一样的,补全的
<PAD>的部分也是一样的,为什么只对K的方向进行padding mask,而不也对Q的方向进行padding mask(如下图)?(即为什么padding_mask只作用在score矩阵的纵向?)
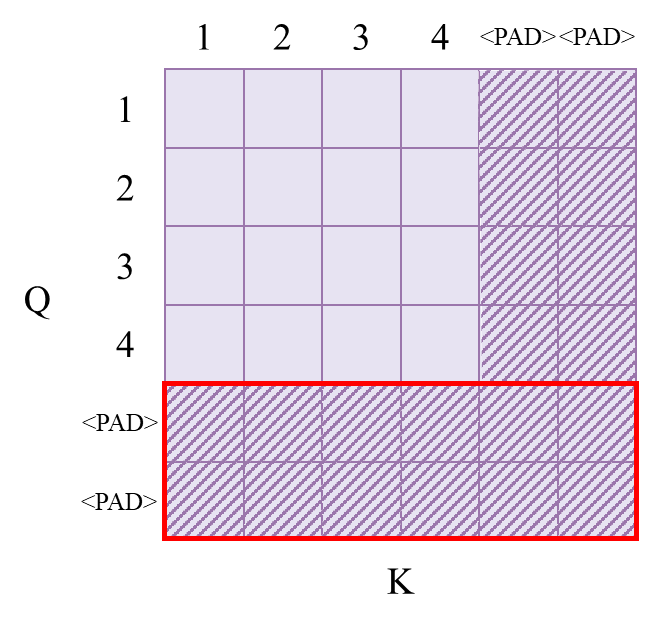
mask的作用是使得被mask的部分变为负无穷大,从而使得 score矩阵在经过横向的softmax之后,被mask的部分概率为0。在transformer实现中,一些代码是将mask的部分设置为一个绝对值很大的负数,这样在经过softmax计算后,红框的部分会成为等概率。还有一些代码将mask的部分设置为-inf,这样经过横向的softmax后,红框部分的softmax分母会计算为0,导致计算出错。
此外,Q中的<PAD>其实也是可以对所有的K计算分数的,只不过在后续的计算输出中,Q的<PAD>的部分会被截取掉。如下图所示,红框表示有效token的计算过程,绿框表示填充<PAD>的计算过程。最左边的是注意力权重矩阵,被mask的部分权重为0,中间的是V矩阵,最右边的是计算得到的新序列矩阵X。X的有效token均来自于V矩阵有效token的组合,X的<PAD>位置也由V的有效token组合而来,但其组合权重是无意义的,且在最终输出里,我们会去掉X里<PAD>的部分。
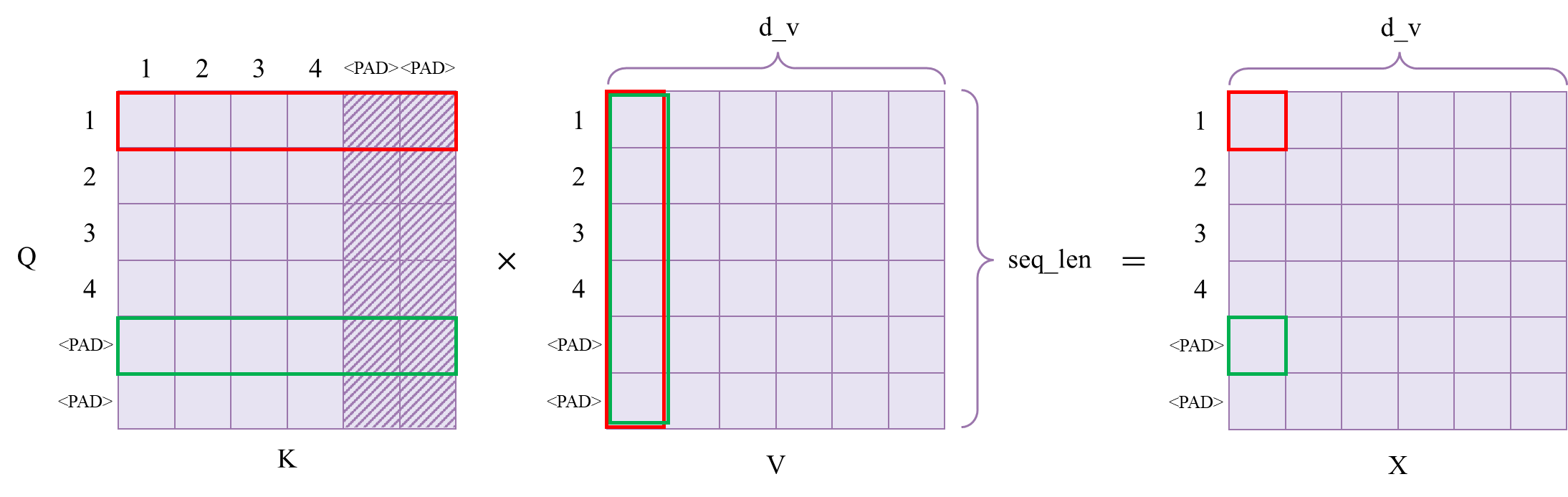
综上,padding_mask只在K的方向进行mask即可。在PyTorch的nn.Transformer的实现中,有一些输入参数的关键字名为:src_key_padding_mask、tgt_key_pdding_mask、memory_key_padding_mask,这就是为什么这些关键字命名中都带有key的原因。关于PyTorch的nn.Transformer的mask参数,后面会讲到。
关于src_mask的形状:
对于 (batch_size, src_len)的src序列输入,后面我们会构造出(batch_size, src_len)的初始mask,由于在多头注意力中,相似度矩阵为 (batch_size, head, src_len, src_len),因此后续需要将初始mask变为(batch_size, 1, 1, src_len),mask会在第二、第三个维度自动进行广播。第二维度会广播为head,第三维度会广播为src_len。
2.memory_mask
memory_mask是应用在编码器-解码器注意力中的,其Q来自于目标序列tgt,K、V来自于编码器源序列src在编码器的输出。对于机器翻译任务,源序列一般都是已经给定的,解码器可以直接看到源序列的全部,因此memory_mask也只使用padding_mask。类似于src_mask,只不过其Q和K的长度可能不同,如下图所示:
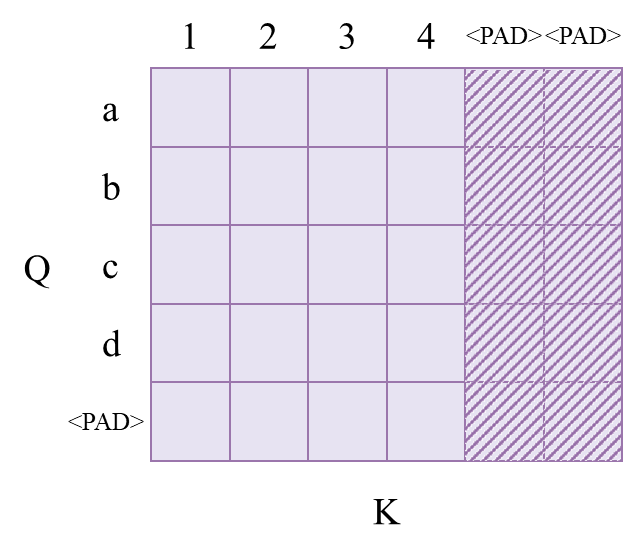
关于memory_mask的形状:
后面我们会构造出 (batch_size, src_len)的初始mask,在编码器-解码器注意力中,相似度矩阵为(batch_size, head, tgt_len, src_len),因此后续需要将初始mask变为 (batch_size, 1, 1, src_len),mask会在第二、第三个维度自动进行广播。第二维度会广播为head,第三维度会广播为tgt_len。
3.tgt_mask
tgt_mask由padding_mask和sequence_mask共同组成。其中,padding_mask和上面相似,只不过具体的mask是由tgt序列确定。如下图所示:
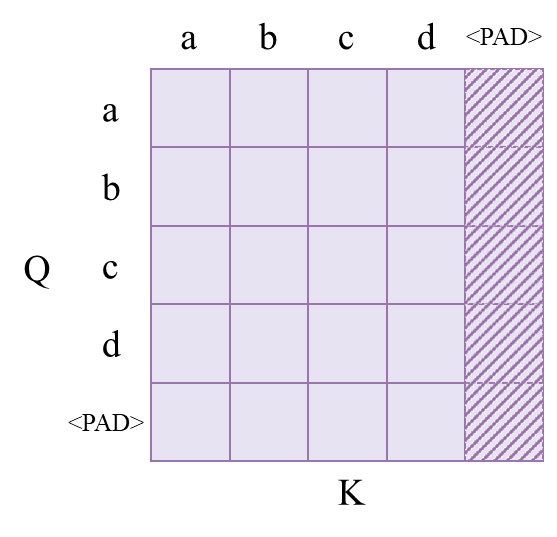
sequence_mask则由下图所示:
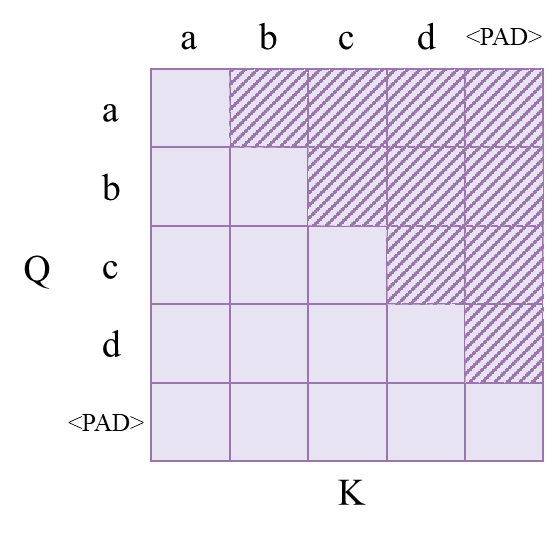
可见Q的每一个位置的字符只对之前已经出现过的字符计算注意力。把sequence_mask与padding_mask相结合,就得到下面的效果:
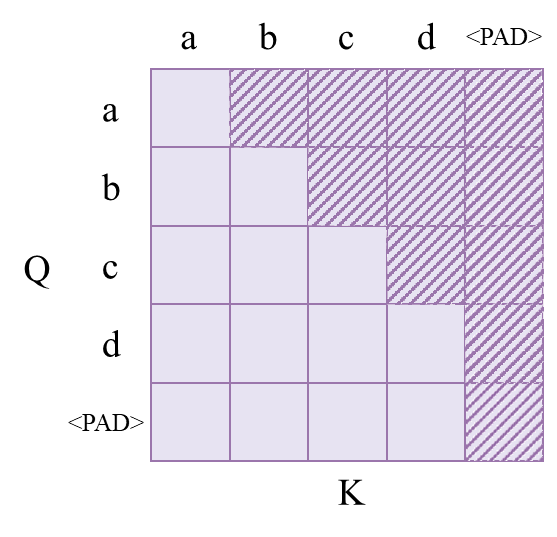
关于tgt_mask的形状:
padding_mask:跟上面介绍的一样,我们首先会构造出 (batch_size, tgt_len)的初始mask,然后将维度扩充为(batch_size, 1, 1, tgt_len)
sequence_mask:和padding_mask不同,我们构造的初始sequence_mask会是 (tgt_len, tgt_len)的形状,这是因为对一个batch的样本,构造的上三角(或下三角)矩阵是一样的。然后我们会将其维度扩充为(1, 1, tgt_len, tgt_len)
为了使padding_mask和sequence_mask能够结合起来,我们需要进一步把padding_mask和sequence_mask均复制为 (batch_size, 1, tgt_len, tgt_len),这样就与sequence_mask的形状一样了,而后就能将二者结合。
4.代码实现
首先,我们分别构造初始padding_mask和初始sequence_mask:(根据不同的transformer实现,mask的定义可能不同,例如,有些mask是由0和1构成的,有些是由bool值构成的,有些1代表mask掉,有些0代表mask掉,有些True代表mask掉,有些False代表mask掉。本文的实现采用数值mask,0代表mask掉,当然,下面的函数我们可以通过设置参数,构建不同类型的mask)
# 填充掩码
def make_padding_mask(seq, pad_id, return_int=True, true_to_mask=False):
"""
构造padding mask, 参数设置根据不同的Transformer实现来确定
Args:
seq: 需要构造mask的序列(batch, seq_len), 该序列使还未进行Embedding, 里面放的是token_id
pad_id: 用于填充的特殊字符<PAD>所对应的token_id, 根据不同代码设置
return_int: 是否返回int形式的mask, 默认为True
true_to_mask: 默认为False, 对于bool mask: True代表在True的位置遮蔽, False代表在False的位置遮蔽。对于int mask: True代表在1的位置遮蔽, False代表在0的位置遮蔽
Returns:
mask: (batch, seq_len), 不同的Transformer实现需输入的形状也不同, 根据需要进行后续更改
"""
mask = (seq == pad_id) # (batch, seq_len), 在<PAD>的位置上生成True, 真实序列的位置为False
if true_to_mask is False:
mask = ~mask
if return_int:
mask = mask.int()
return mask
# 因果掩码
def make_sequence_mask(seq, return_int=True, true_to_mask=False):
"""
构造sequence mask, 参数设置根据不同的Transformer实现来确定
Args:
seq: 需要构造mask的序列(batch, seq_len), 该序列使还未进行Embedding, 里面放的是token_id
return_int: 是否返回int形式的mask, 默认为True
true_to_mask: 默认为False, 对于bool mask: True代表在True的位置遮蔽, False代表在False的位置遮蔽。对于int mask: True代表在1的位置遮蔽, False代表在0的位置遮蔽
Returns:
mask: (seq_len, seq_len), 不同的Transformer实现需输入的形状也不同, 根据需要进行后续更改
"""
_, seq_len = seq.shape
mask = torch.tril(torch.ones(seq_len, seq_len)) # (seq_len, seq_len), 下三角为1, 上三角为0
mask = 1 - mask
mask = mask.bool()
if true_to_mask is False:
mask = ~mask
if return_int:
mask = mask.int()
return mask
我们创建一个序列矩阵,batch_size为2,每个样本中1代表有效的token,0代表<PAD>的token,可见一个batch里的不同样本所填充的<PAD>数量可以是不同的,但填充后的长度相同。如下所示:
# 示例
seq = torch.tensor([[1,1,1,1,1,1,1,1,1,1,1,0], [1,1,1,1,1,1,1,1,1,1,0,0]]) # (batch_size, src_seq_len=12)
# 比较四种不同的padding_mask
print(make_padding_mask(seq=seq, pad_id=0, return_int=True, true_to_mask=False))
print(make_padding_mask(seq=seq, pad_id=0, return_int=True, true_to_mask=True))
print(make_padding_mask(seq=seq, pad_id=0, return_int=False, true_to_mask=False))
print(make_padding_mask(seq=seq, pad_id=0, return_int=False, true_to_mask=True))
# 展示sequence_mask
print(make_sequence_mask(seq=seq, return_int=True, true_to_mask=False))
输出为:
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]], dtype=torch.int32)
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]], dtype=torch.int32)
tensor([[ True, True, True, True, True, True, True, True, True, True,
True, False],
[ True, True, True, True, True, True, True, True, True, True,
False, False]])
tensor([[False, False, False, False, False, False, False, False, False, False,
False, True],
[False, False, False, False, False, False, False, False, False, False,
True, True]])
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int32)
我们可以进一步构造src_mask、memory_mask、tgt_mask:
# 进一步分别构造src_mask、memory_mask、tgt_mask
def make_src_mask(src, pad_id, return_int=True, true_to_mask=False):
"""构造src_mask
Args:
src: 源序列(batch_size, src_len)
pad_id: 补全符号的token_id
return_int: 是否返回int形式的mask, 默认为True
true_to_mask: 默认为False, 对于bool mask: True代表在True的位置遮蔽, False代表在False的位置遮蔽。对于int mask: True代表在1的位置遮蔽, False代表在0的位置遮蔽
Returns:
src_mask: (batch_size, 1, 1, src_len)
"""
padding_mask = make_padding_mask(src, pad_id, return_int=return_int, true_to_mask=true_to_mask)
padding_mask = padding_mask.unsqueeze(1)
padding_mask = padding_mask.unsqueeze(2)
return padding_mask
def make_memory_mask(src, pad_id, return_int=True, true_to_mask=False):
"""构造memory_mask
Args:
src: 源序列(batch_size, src_len)
pad_id: 补全符号的token_id
return_int: 是否返回int形式的mask, 默认为True
true_to_mask: 默认为False, 对于bool mask: True代表在True的位置遮蔽, False代表在False的位置遮蔽。对于int mask: True代表在1的位置遮蔽, False代表在0的位置遮蔽
Returns:
memory_mask: (batch_size, 1, 1, src_len)
"""
padding_mask = make_padding_mask(src, pad_id, return_int=return_int, true_to_mask=true_to_mask)
padding_mask = padding_mask.unsqueeze(1)
padding_mask = padding_mask.unsqueeze(2)
return padding_mask
def make_tgt_mask(tgt, pad_id, return_int=True, true_to_mask=False):
"""构造tgt_mask
Args:
tgt: 目标序列(batch_size, tgt_len)
pad_id: 补全符号的token_id
return_int: 是否返回int形式的mask, 默认为True
true_to_mask: 默认为False, 对于bool mask: True代表在True的位置遮蔽, False代表在False的位置遮蔽。对于int mask: True代表在1的位置遮蔽, False代表在0的位置遮蔽
Returns:
tgt_mask: (batch_size, 1, tgt_len, tgt_len)
"""
padding_mask = make_padding_mask(tgt, pad_id, return_int=return_int, true_to_mask=true_to_mask) # (batch_size, tgt_len)
padding_mask = padding_mask.unsqueeze(1)
padding_mask = padding_mask.unsqueeze(2) # (batch_size, 1, 1, tgt_len)
padding_mask = padding_mask.repeat(1, 1, tgt.size(1), 1) # (batch_size, 1, tgt_len, tgt_len)
sequence_mask = make_sequence_mask(tgt, return_int=True, true_to_mask=False) # (tgt_len, tgt_len)
sequence_mask = sequence_mask.unsqueeze(0)
sequence_mask = sequence_mask.unsqueeze(1) # (1, 1, tgt_len, tgt_len)
sequence_mask = sequence_mask.repeat(tgt.size(0), 1, 1, 1) # (batch_size, 1, tgt_len, tgt_len)
# 合并两个mask
if true_to_mask is False: # 根据不同类型的mask, 使用"与"或"或"的方式进行合并
mask = padding_mask & sequence_mask
else:
mask = padding_mask | sequence_mask
return mask
构造一个简单的源序列及目标序列,结果如下:
# 示例
src = torch.tensor([[1,1,1,1,1,1,1,1,1,0,0,0],
[1,1,1,1,1,1,1,0,0,0,0,0]])
tgt = torch.tensor([[1,1,1,1,1,1,1,0,0,0,0],
[1,1,1,1,1,0,0,0,0,0,0]])
src_mask = make_src_mask(src, pad_id=0)
print('src_mask:')
print(src_mask)
print(src_mask.shape)
memory_mask = make_memory_mask(src, pad_id=0) # memory_mask和src_mask这里是一样的, 但在transformer内部会广播成不同的维度
print('memory_mask:')
print(memory_mask)
print(memory_mask.shape)
tgt_mask = make_tgt_mask(tgt, pad_id=0)
print('tgt_mask:')
print(tgt_mask)
print(tgt_mask.shape)
输出结果为:
src_mask:
tensor([[[[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]],
[[[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]]]], dtype=torch.int32)
torch.Size([2, 1, 1, 12])
memory_mask:
tensor([[[[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]],
[[[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]]]], dtype=torch.int32)
torch.Size([2, 1, 1, 12])
tgt_mask:
tensor([[[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]]],
[[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]]]], dtype=torch.int32)
torch.Size([2, 1, 11, 11])
到这里,整个transformer模型构建完毕,接下来使用构建的模型进行中英翻译demo。
二、使用从零构建的Transformer模型完成中英翻译demo
(一)数据集介绍及预处理
由于算力有限,我们只实现一个简单的demo用于了解transformer在机器翻译任务中的训练与预测流程。这里我们使用一个较小的中英翻译数据集:
使用中英翻译数据集:

该数据集有将近3万个中英文本对,如下所示:
其数据格式为English + TAB + The Other Language + TAB + Attribution

可以发现这个数据集中有很多的繁体字,为了方便后续构造词典,我们使用opencc库将繁体字转换为简体字,并将数据集保存为dataset.json。
首先导入后续需要用到的相关库,其中torchtext需注意版本需要与pytorch相匹配:
from torchtext.data.metrics import bleu_score # torchtext已停止更新,不影响使用,torchtext0.18版本对应PyTorch2.3版本,更高的pytorch版本导入torchtext将报错
import json
import opencc # 使用的数据集是繁体字,用该库转换为简体字
from torchtext.data.utils import get_tokenizer # 用于英文分词
import jieba # 用于中文分词
from tqdm import tqdm
from collections import Counter # 用于统计词频
import os
```读取原始数据集,并将其保存为json文件,文件的每一行为一个字典:`{'enlish': ......, 'chinese': ......}````python
# 创建 OpenCC 转换器实例
converter = opencc.OpenCC('t2s') # 't2s'表示从繁体到简体
# 将该数据集保存为json格式
dataset = []
with open('./data/cmn-eng/cmn.txt', 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
line = line.split('\t')
en = line[0]
cn = line[1]
cn = converter.convert(cn)
dataset.append({'english': en, 'chinese': cn})
# 将每个字典逐行写入 JSON 文件
with open('./data/cmn-eng/dataset.json', 'w', encoding='utf-8') as json_file:
for item in dataset:
json.dump(item, json_file, ensure_ascii=False)
json_file.write('\n')
保存的json文件如下:
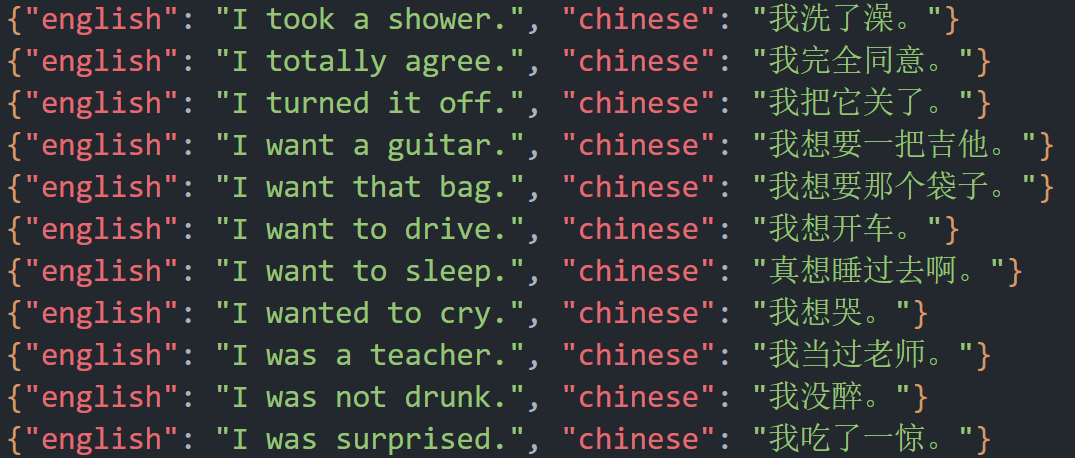
(二)分词并构造词典
为了完成机器翻译任务,首先要对语料进行分词,将其分成一个个小的单词,即token,而后把所有出现的token构造成一个词典,并为每个token分配一个独有的token_id,这样就能一对一的在token和token_id间进行转换。
对于英文,我们使用torchtext的get_tokenizer构造分词器en_tokenizer,通常一个单词就是一个token。而对于中文,通常可以将进行 词语级别和字符级别 的分词,例如,对于“我喜欢打球。”词语级别的分词可能会产生结果:[“我”“喜欢”“打球”“。”],而字符级别的分词则产生结果:[“我”“喜”“欢”“打”“球”“。”]。如果需进行词语级别的分词,我们可以使用jieba库实现,这种方法会构造较大的词典,训练较慢。由于我们使用的数据量很少,因此采用字符级别的分词,这种方法构造的词典较小,但可能会造成语义的不连贯。
中英文的分词器构造如下:
# 英文分词示例
en_tokenizer = get_tokenizer('basic_english')
text = "Hello! How are you doing today?"
tokens = en_tokenizer(text)
print(tokens)
# 词语级分词【构造的词典很大,训练可能较慢】
# def cn_tokenizer(text):
# return jieba.lcut(text)
# 字符级分词【构造的词典较小,但可能导致语义不连贯】
def cn_tokenizer(text):
return list(text)
text = "你好!你今天好吗?"
tokens = cn_tokenizer(text)
print(tokens)
输出为:
['hello', '!', 'how', 'are', 'you', 'doing', 'today', '?']
['你', '好', '!', '你', '今', '天', '好', '吗', '?']
接下来,我们对dataset.json中的所有中英文分别进行分词,并统计每个token在整个数据集中出现的次数,在此基础上分别构造由token到token_id和由token_id到token的词典。有些时候,对于出现频率很低的token,可以不放入词典,以加快训练,当模型遇到未见过的单词时,以特殊token<unk>代替。这里由于我们的数据集较小,词频较低的token也很多,为简单起见,数据集中的所有token我们都放进词典。代码如下:
# ----------------------------------------------------------------
# 读取dataset
dataset = []
with open('./data/cmn-eng/dataset.json', 'r', encoding='utf-8') as f:
for line in f:
dataset.append(json.loads(line))
# ----------------------------------------------------------------
# 构建词典
en_max_len = 0
cn_max_len = 0
en_vocab = []
cn_vocab = []
for data in tqdm(dataset, desc='Building Vocabulary'):
en_text = data['english']
cn_text = data['chinese']
en_tokens = en_tokenizer(en_text)
cn_tokens = cn_tokenizer(cn_text)
en_max_len = max(en_max_len, len(en_tokens))
cn_max_len = max(cn_max_len, len(cn_tokens))
en_vocab.extend(en_tokens)
cn_vocab.extend(cn_tokens)
en_counter = dict(Counter(en_vocab))
cn_counter = dict(Counter(cn_vocab))
# 保存词频统计
with open('./data/cmn-eng/en_counter.json', 'w', encoding='utf-8') as f:
json.dump(en_counter, f, ensure_ascii=False, indent=4)
with open('./data/cmn-eng/cn_counter.json', 'w', encoding='utf-8') as f:
json.dump(cn_counter, f, ensure_ascii=False, indent=4)
# 为简单起见,将数据集所有的token都添加到词典中,不考虑词频和未知token
# 定义特殊字符
start_token = '<sos>'
end_token = '<eos>'
pad_token = '<pad>'
special_tokens = [start_token, end_token, pad_token]
en_vocab = special_tokens + list(en_counter.keys())
cn_vocab = special_tokens + list(cn_counter.keys())
# 构建词典
en_dict_token2id = {token: i for i, token in enumerate(en_vocab)}
en_dict_id2token = {i: token for i, token in enumerate(en_vocab)}
cn_dict_token2id = {token: i for i, token in enumerate(cn_vocab)}
cn_dict_id2token = {i: token for i, token in enumerate(cn_vocab)}
# 分别保存token到token_id和token_id到token的词典
with open('./data/cmn-eng/en_dict_token2id.json', 'w') as f:
json.dump(en_dict_token2id, f, ensure_ascii=False, indent=4)
with open('./data/cmn-eng/cn_dict_token2id.json', 'w') as f:
json.dump(cn_dict_token2id, f, ensure_ascii=False, indent=4)
with open('./data/cmn-eng/en_dict_id2token.json', 'w') as f:
json.dump(en_dict_id2token, f, ensure_ascii=False, indent=4)
with open('./data/cmn-eng/cn_dict_id2token.json', 'w') as f:
json.dump(cn_dict_id2token, f, ensure_ascii=False, indent=4)
# 计算词典大小
en_vocab_size = len(en_vocab)
cn_vocab_size = len(cn_vocab)
print(f'英文字典大小为:{en_vocab_size}')
print(f'英文最长序列长度为:{en_max_len}')
print(f'中文字典大小为:{cn_vocab_size}')
print(f'中文最长序列长度为:{cn_max_len}')
输出为:
Building Vocabulary: 100%|██████████| 29909/29909 [00:00<00:00, 89633.87it/s]
英文字典大小为:7192
英文最长序列长度为:38
中文字典大小为:2839
中文最长序列长度为:44
输出结果显示,英文的token共计7192个,中文的token共计2839个,在所有英文句子中,最长的token序列长度为38,在所有中文句子中,最长的token序列长度为38。cn_counter.json和en_counter.json分别保存了中英文token在数据集中出现的次数,由于我们不对低频词做专门的处理,这里仅作为一个参考。中文词频统计如下:
英文词频统计如下:
在构造的词典中,特殊字符<sos> <eos> <pad>所对应的token_id分别为0、1、2,中英文分别都构造了由token到token_id和由token_id到token的词典,即cn_dict_id2token.json cn_dict_token2id.json en_dict_id2token.json en_dict_token2id.json,以中文为例,保存的id to token词典如下所示:
token to id词典如下:
(三)构造token与token_id转换函数
接下来我们封装两个函数,分别为text2id和id2text。前者首先将给定的文本进行分词,然后在首尾分别添加<sos>和<eos>作为开始与结束的标志,并用<pad>将文本序列填充到特定长度,最后将分词后的每个token 转换为token_id,返回一个装满token_id的列表。这里我们将英文序列填充为45,中文序列填充为50,以提现源序列和目标序列的长度可以不同。后者则接收一个填满token_id的列表,将其转换为去掉特殊字符的文本。
具体实现如下:
# 由token转换为token_id
def text2id(text, language, dict=None, dict_path='./data/cmn-eng', en_max_len=45, cn_max_len=50):
"""将一段文本转换为该词典下对应的token_id, 并根据max_len补全pad, 这里将中文填充为50, 英文填充为45
Args:
text : 输入文本
language : 语言, 中文或英文
dict : 词典, 如果为None, 则从dict_path中加载词典
dict_path : 词典路径
Returns:
list : 列表, 里面是每个token的token_id
"""
if language == 'cn':
token = cn_tokenizer(text)
max_len = cn_max_len
if language == 'en':
token = en_tokenizer(text)
max_len = en_max_len
if dict is None:
with open(f'{dict_path}/{language}_dict_token2id.json', 'r') as f:
dict = json.load(f)
token_id = [dict[t] for t in token]
token_id = [dict['<sos>']] + token_id + [dict['<eos>']]
if len(token_id) < max_len:
token_id += [dict['<pad>']] * (max_len - len(token_id))
return token_id
# 由token_id转换为token
def id2text(token_id, language, dict=None, dict_path='./data/cmn-eng'):
"""将一个列表中的token_id转换为对应的文本, 并去掉<sos>、<eos>、<pad>
Args:
token_id : 装有token_id的列表
language : 语言, 中文或英文
dict : 词典, 如果为None, 则从dict_path中加载词典
dict_path : 词典路径
Returns:
str : 文本
"""
if dict is None:
with open(f'{dict_path}/{language}_dict_id2token.json', 'r') as f:
dict = json.load(f)
dict = {int(k): v for k, v in dict.items()} # 词典保存为json后,键会变成字符串, 转换为int
token = [dict[i] for i in token_id if i not in [0, 1, 2]]
if language == 'cn':
return ''.join(token)
if language == 'en':
text = ''
CAP = False # 调整是否大写
# 调整英文单词、符号之间空格的有无
for i, t in enumerate(token):
if i == 0:
text += t.capitalize() # 首字母大写
else:
if t in ",.!?;:)}]'\"":
text += t
if t in ".?!":
CAP = True
else:
if CAP:
t = t.capitalize()
CAP = False
text += ' ' + t
return text
# 示例,由于未加入unk,必须使用词典里有的单词
# 中文token转token_id
cn_text = '你好吗?我很好!谢谢,不客气。'
cn_token_id = text2id(cn_text, 'cn', cn_dict_token2id)
print(cn_token_id) # <sos>、<eos>、<pad>的token_id分别为0、1、2
print('length:', len(cn_token_id))
# 英文token转token_id
en_text = 'How are you? I am fine! Thank you, you are welcome.'
en_token_id = text2id(en_text, 'en', en_dict_token2id)
print(en_token_id)
print('length:', len(en_token_id))
# 中文token_id转token
print(id2text(cn_token_id, 'cn', cn_dict_id2token))
# 英文token_id转token
print(id2text(en_token_id, 'en', en_dict_id2token))
输出为:
[0, 5, 6, 34, 32, 18, 96, 6, 12, 53, 53, 130, 22, 701, 72, 4, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
length: 50
[0, 101, 235, 74, 19, 11, 136, 113, 7, 214, 74, 249, 74, 235, 81, 4, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
length: 45
你好吗?我很好!谢谢,不客气。
How are you? I am fine! Thank you, you are welcome.
(四)构建DataLoader
接下来主要是训练流程搭建,首先构造一个TranslateDataset类,该数据集读取了原始dataset并把所有中英文本全部转换成了token_id,在此基础上我们构建DataLoader如下:
from torch.utils.data import random_split, DataLoader, Dataset
import numpy as np
class TranslateDataset(Dataset):
def __init__(self, dataset, en_dict_token2id, cn_dict_token2id):
"""构建中英翻译数据集
Args:
dataset : [{'english': '...', 'chinese': '...'}, ...]
en_dict_token2id : 英语字典, token到token_id的映射
cn_dict_token2id : 中文字典, token到token_id的映射
"""
self.dataset = dataset
self.en_token_id_data = []
self.cn_token_id_data = []
for data in self.dataset:
self.en_token_id_data.append(text2id(data['english'], language='en', dict=en_dict_token2id))
self.cn_token_id_data.append(text2id(data['chinese'], language='cn', dict=cn_dict_token2id))
self.en_token_id_data = np.array(self.en_token_id_data) # (total_data_size, en_seq_len)
self.cn_token_id_data = np.array(self.cn_token_id_data) # (total_data_size, cn_seq_len)
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
return self.en_token_id_data[index, :], self.cn_token_id_data[index, :]
# 构建数据集
translate_dataset = TranslateDataset(dataset, en_dict_token2id, cn_dict_token2id)
# 划分数据集
val_size = 1000 # 只选用1000个数据验证
train_size = len(dataset) - val_size
# 分割数据集
train_dataset, val_dataset = random_split(translate_dataset, [train_size, val_size])
# 构建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=True)
(五)构建模型
现在可以初始化一个第一部分手撕的Transformer模型:
# 构建transformer模型
# 由于数据集较小,这里我们构建一个小型transformer
transformer = Transformer(
src_vocab_size=en_vocab_size, # 7192
tgt_vocab_size=cn_vocab_size, # 2839
d_model=256,
num_layers=3,
num_heads=8,
d_ff=1024,
dropout=0.1,
max_len=100 # max_len可以取大一些,实际计算时只会根据序列长度取相应尺度的位置编码
)
test_src = torch.randint(0, en_vocab_size, (32, 45)) # 在词典范围内生成随机数
test_tgt = torch.randint(0, cn_vocab_size, (32, 50))
test_out = transformer(test_src, test_tgt)
print(test_out.shape)
trainable_params = sum(p.numel() for p in transformer.parameters() if p.requires_grad)
print(f"Total number of trainable parameters: {trainable_params}")
输出以下信息:
torch.Size([32, 50, 2839])
Total number of trainable parameters: 8828183
(六)训练
我们仅使用简单的训练策略进行训练,学习率设置为0.001,每3个epcoh变为原来的0.8,共训练10个epoch,batch_size在DataLoader中设置为了32。
每个训练循环中,首先获取一个btach的源序列src和目标序列tgt。由于训练的目的是预测tgt序列的下一个字符,因此,我们将tgt[:, :-1]作为解码器的输入,tgt[:, 1:]作为预测标签,训练的目的就是让每一个位置的字符在编码器输出和只看到自身前面已有字符的情况下,预测下一个字符。
例如:
原tgt为:<sos> a b c d e <eos> <pad> <pad>
那么解码器的输入tgt[:, :-1]为:<sos> a b c d e <eos> <pad>
解码器的输出标签tgt[:, 1:]为:a b c d e <eos> <pad> <pad>
假设预测输出为:a' b' c' d' e' <eos> <pad> <pad>,该预测输出需要与真实值进行交叉熵计算损失,为避免<pad>对有效token的影响,计算损失时<pad>位置不参与,因此实际需要计算的是:a b c d e <eos> 与 a' b' c' d' e' <eos>的对应字符位置损失。
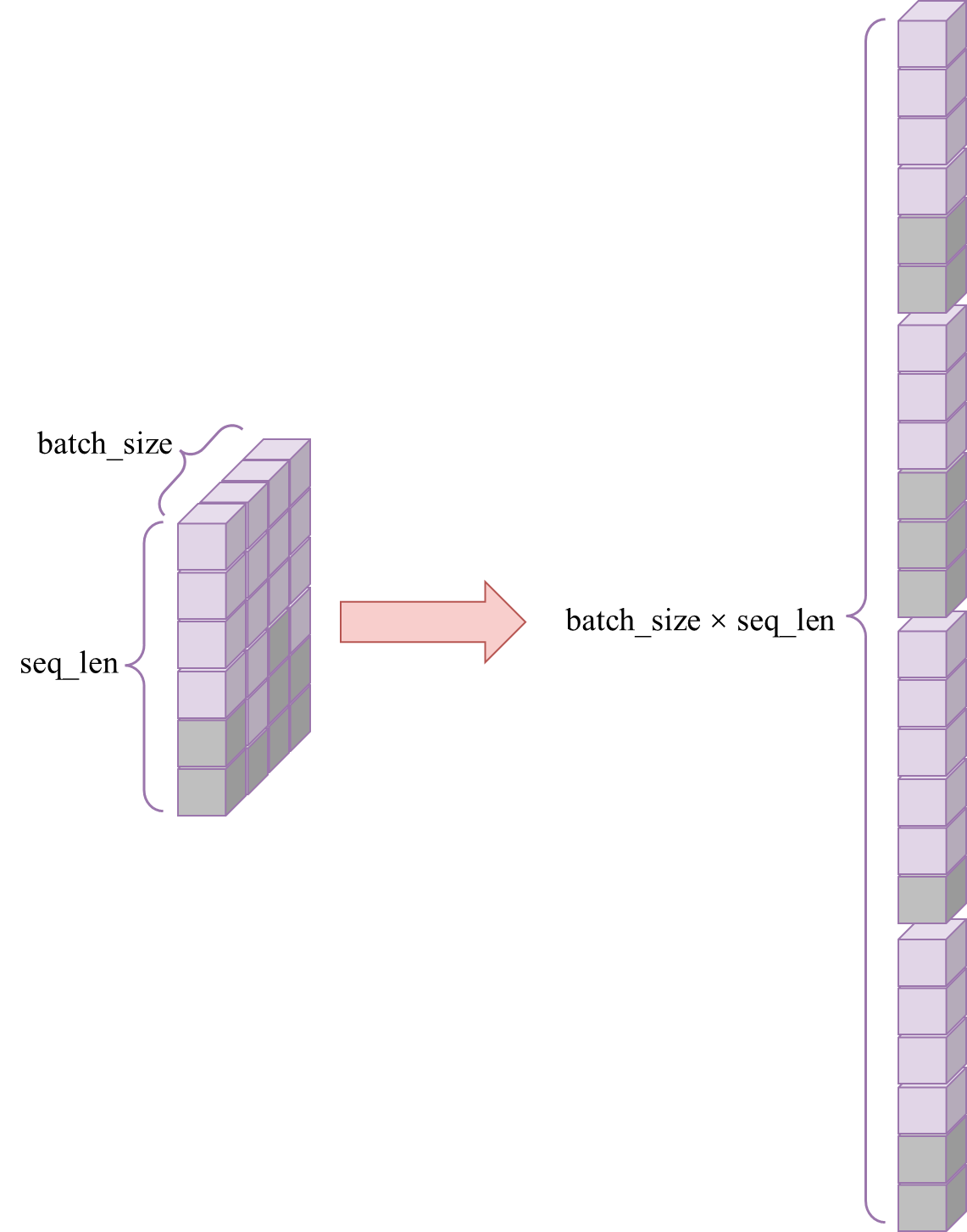
在计算损失时,模型输出的形状为(batch_size, seq_len, cn_vocab_size),首先要将其形状变换为(batch_size × seq_len, cn_vocab_size),这样,每一行代理表每个位置的预测logits,如下图所示:
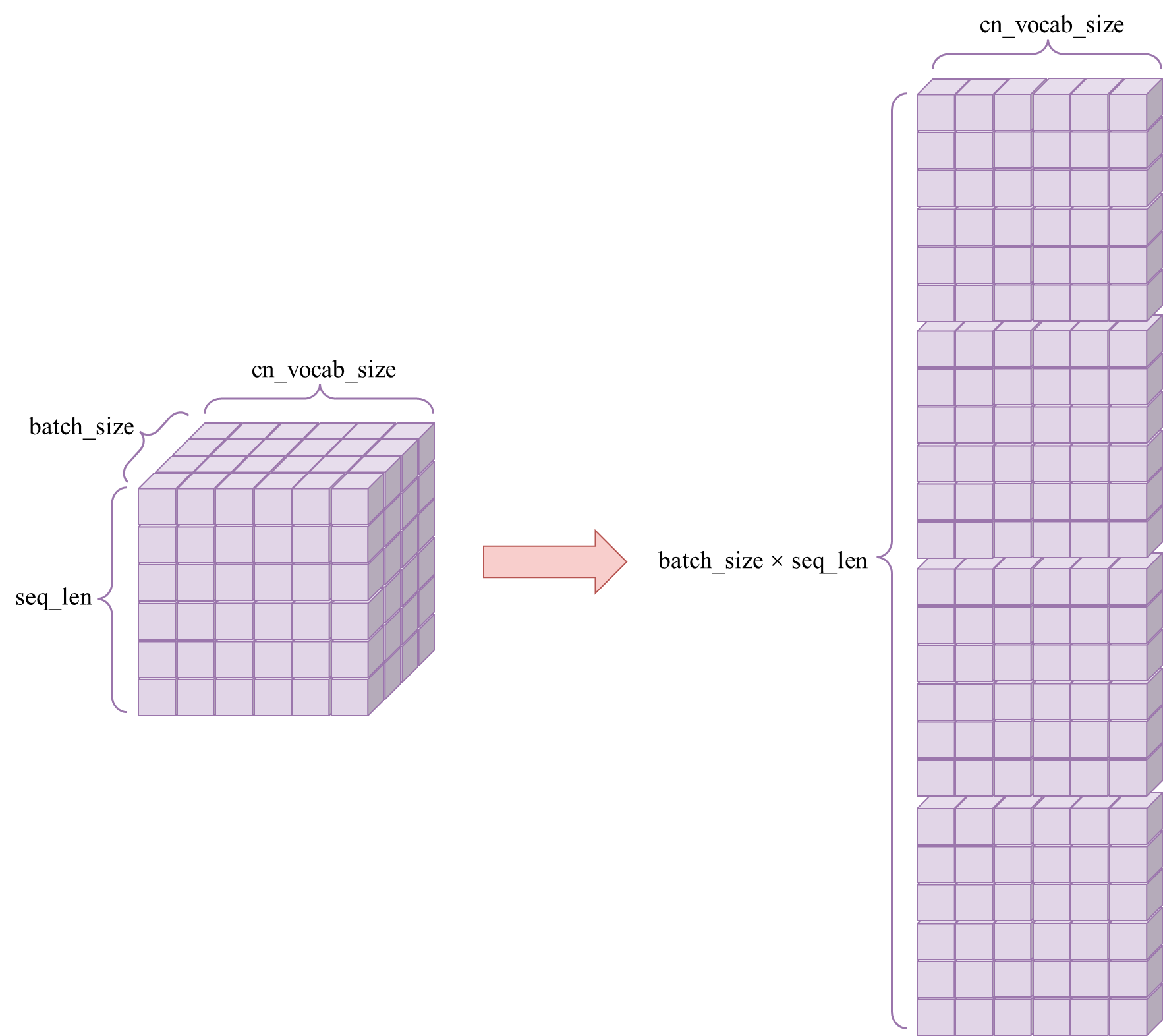
对于真实标签tgt[:, 1:],也要将其由形状(batch_size, seq_len)变为(batch_size × seq_len, ),如下图所示,其中,灰色部分代表真实标签中<pad>的部分,这一部分是不用参与损失计算的,在pytorch中可以通过为损失函数添加ignore_index参数来实现:
最后,将得到的每个位置的预测logits与每个位置的真实label进行损失计算:
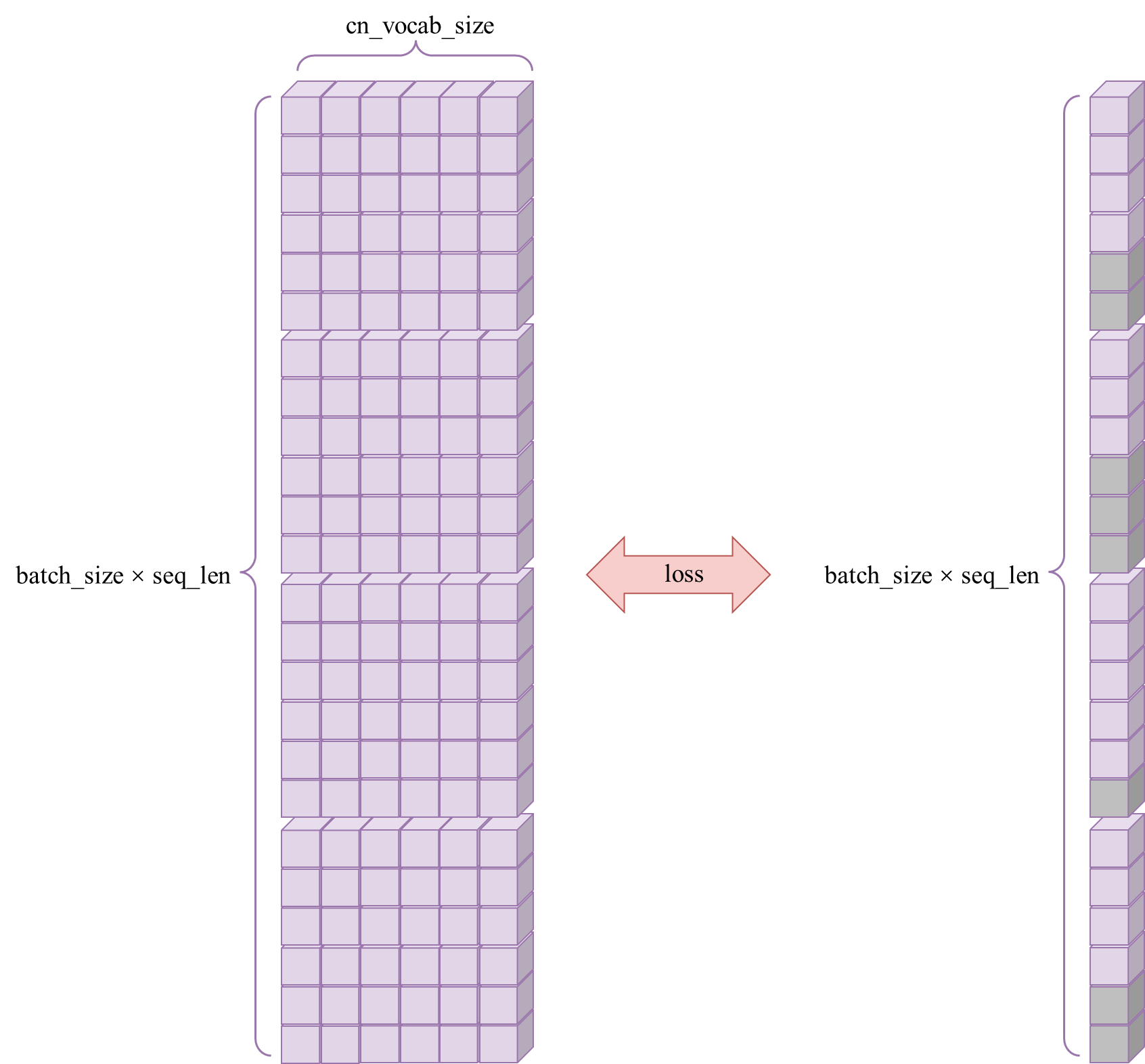
以上过程也进一步解释了为什么我们在构造padding_mask时只用对列,也就是K上进行,因为行,也就是Q上的<pad>部分在计算损失时会忽略掉,并不影响最终预测效果。
训练过程代码如下,其中,#############部分用于将训练过程中的mask和训练中的翻译效果可视化出来,可以将这部分注释掉:
# 定义参数
num_epochs = 10
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transformer = transformer.to(device)
loss_func = torch.nn.CrossEntropyLoss(ignore_index=2) # 计算损失时,忽略掉pad_id部分的计算
optimizer = torch.optim.AdamW(transformer.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.8) # 每隔固定数量的epoch将学习率减少一个固定的比例
train_loss_curve = []
val_loss_curve = []
lr_curve = []
# 训练和验证
for epoch in range(num_epochs):
print(f'Epoch: {epoch+1}/{num_epochs}')
transformer.train()
loss_sum = 0.0
# 训练----------------------------------------------------
for step, (src, tgt) in tqdm(enumerate(train_loader), total=len(train_loader)):
# src: (batch_size, 45)
# tgt: (batch_size, 50)
####################################################
if step % (len(train_loader)-1) == 0 and step != 0:
print(id2text(src[0].tolist(), 'en', en_dict_id2token))
print(id2text(tgt[0].tolist(), 'cn', cn_dict_id2token))
####################################################
# 构造mask
src_mask = make_src_mask(src=src, pad_id=2)
memory_mask = make_memory_mask(src=src, pad_id=2)
tgt_mask = make_tgt_mask(tgt=tgt[:, :-1], pad_id=2)
####################################################
# mask可视化
if epoch == 0 and step == 0:
# print(src_mask.shape)
# print(src_mask)
# print(memory_mask.shape)
# print(memory_mask)
# print(tgt_mask.shape)
# print(tgt_mask)
plt.imshow(src_mask.squeeze().numpy(), cmap='viridis', interpolation='nearest') # (batch_size, seq_len)
plt.colorbar()
plt.title('src_mask')
plt.show()
plt.imshow(memory_mask.squeeze().numpy(), cmap='viridis', interpolation='nearest') # (batch_size, seq_len)
plt.colorbar()
plt.title('memory_mask')
plt.show()
plt.imshow(tgt_mask[0].squeeze().numpy(), cmap='viridis', interpolation='nearest') # 取了batch中的第一个,(seq_len, seq_len)
plt.colorbar()
plt.title('tgt_mask')
plt.show()
####################################################
src = src.to(device).long()
tgt = tgt.to(device).long()
src_mask = src_mask.to(device)
memory_mask = memory_mask.to(device)
tgt_mask = tgt_mask.to(device)
# 训练时,是由输入的tgt预测下一个字符,因此输入为tgt[:, :-1],每一个位置的字符在看见前面已有字符的情况下预测下一个字符
# 例如,tgt为: <sos> a b c d e <eos> <pad> <pad>,那么输入为:<sos> a b c d e <eos> <pad>,真值为:a b c d e <eos> <pad> <pad>
# 假设预测输出为:a' b' c' d' e' <eos> <pad> <pad>,该预测输出需要与真实值进行交叉熵计算损失,为避免<pad>对有效token的影响,计算损失时<pad>位置不参与
# 因此实际需要计算的是:a b c d e <eos> 与 a' b' c' d' e' <eos>的对应字符位置损失
pred = transformer(src, tgt[:, :-1], src_mask=src_mask, memory_mask=memory_mask, tgt_mask=tgt_mask)
####################################################
# 查看训练时翻译效果
if step % (len(train_loader)-1) == 0 and step != 0:
test_pred = pred[0] # (seq_len, vocab_size)
test_pred = test_pred.argmax(dim=1) # (seq_len,)
test_pred = test_pred.tolist() # 转换成装了token_id的列表
if 1 in test_pred:
eos_index = test_pred.index(1) # 找到<eos>索引
test_pred = test_pred[:eos_index+1]
print(id2text(test_pred, 'cn', cn_dict_id2token))
print('pred_len:', len(test_pred))
####################################################
# 调整形状以计算损失
pred = pred.contiguous().view(-1, pred.shape[-1]) # (batch_size, seq_len, cn_vocab_size) -> (batch_size * seq_len, cn_vocab_size)
target = tgt[:, 1:].contiguous().view(-1) # (batch_size, seq_len) -> (batch_size * seq_len)
loss = loss_func(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item() # 当前epoch的累计损失
train_avg_loss = loss_sum / len(train_loader)
lr = optimizer.param_groups[0]['lr']
train_loss_curve.append(train_avg_loss)
lr_curve.append(lr)
scheduler.step()
# 验证----------------------------------------------------
transformer.eval()
loss_sum = 0.0
for step, (src, tgt) in enumerate(val_loader):
# 构造mask
src_mask = make_src_mask(src=src, pad_id=2)
memory_mask = make_memory_mask(src=src, pad_id=2)
tgt_mask = make_tgt_mask(tgt=tgt[:, :-1], pad_id=2)
src = src.to(device).long()
tgt = tgt.to(device).long()
src_mask = src_mask.to(device)
memory_mask = memory_mask.to(device)
tgt_mask = tgt_mask.to(device)
pred = transformer(src, tgt[:, :-1], src_mask=src_mask, memory_mask=memory_mask, tgt_mask=tgt_mask)
pred = pred.contiguous().view(-1, pred.shape[-1])
target = tgt[:, 1:].contiguous().view(-1)
loss = loss_func(pred, target)
loss_sum += loss.item()
val_avg_loss = loss_sum / len(val_loader)
val_loss_curve.append(val_avg_loss)
print(f'Train Loss: {train_avg_loss:.4f} | Val Loss: {val_avg_loss:.4f} | LR: {lr:.6f}')
# 保存模型
torch.save(transformer.state_dict(), 'transformer_from_scratch.pt')
# 绘制损失曲线
plt.figure()
plt.plot(train_loss_curve, label='Train Loss', color='blue')
plt.plot(val_loss_curve, label='Validation Loss', color='red')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss Curves')
plt.legend()
plt.show()
# 绘制学习率曲线
plt.figure()
plt.plot(lr_curve, label='Learning Rate', color='green')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Curve')
plt.legend()
plt.show()
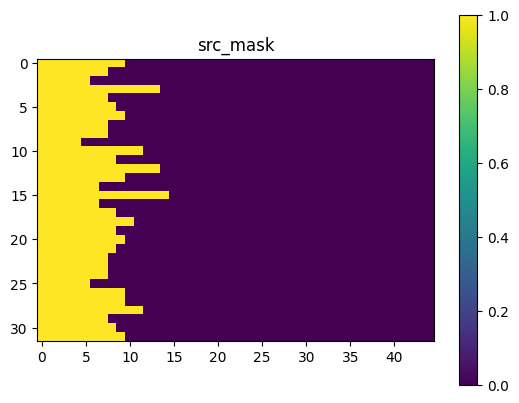
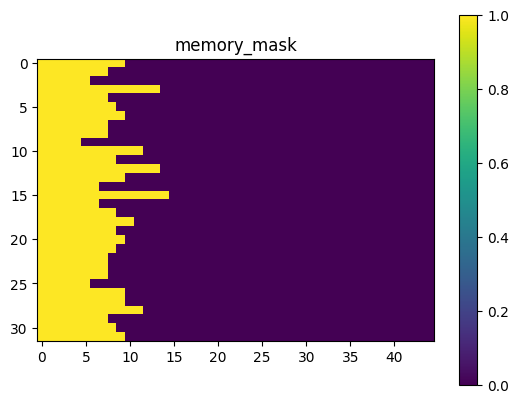
可视化的src_mask memory_mask tgt_mask效果如下,其中tgt_mask取的是batch中的索引为0的部分进行可视化:
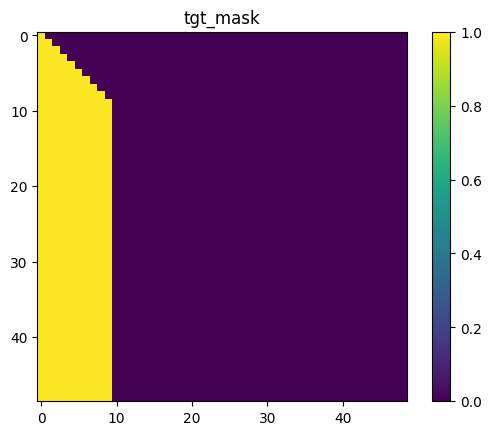
训练过程如下:
Epoch: 1/10
100%|██████████| 904/904 [00:48<00:00, 18.71it/s]
I don' t remember.
我不记得了。
我不记得很。
pred_len: 7
Train Loss: 3.4697 | Val Loss: 2.7571 | LR: 0.001000
Epoch: 2/10
100%|██████████| 904/904 [00:46<00:00, 19.32it/s]
Here' s your tea.
这是你的茶。
你里你的茶。
pred_len: 7
Train Loss: 2.5042 | Val Loss: 2.3599 | LR: 0.001000
Epoch: 3/10
100%|██████████| 904/904 [00:45<00:00, 19.71it/s]
I might' ve forgotten my keys.
我可能把钥匙忘了。
我可能把钥匙给了。
pred_len: 10
Train Loss: 2.0882 | Val Loss: 2.1522 | LR: 0.001000
Epoch: 4/10
100%|██████████| 904/904 [00:46<00:00, 19.42it/s]
His record is a new world record in the 100-meter dash.
他刷新了百米短跑的世界纪录。
他的在环一分花缺的头界。。。
pred_len: 15
Train Loss: 1.7308 | Val Loss: 1.9559 | LR: 0.000800
Epoch: 5/10
100%|██████████| 904/904 [00:46<00:00, 19.57it/s]
Let' s make some more.
我们做多一点。
让们再了的点。
pred_len: 8
Train Loss: 1.5353 | Val Loss: 1.9603 | LR: 0.000800
Epoch: 6/10
100%|██████████| 904/904 [00:44<00:00, 20.19it/s]
Please turn off the tv.
请把电视关掉。
请关电视机掉。
pred_len: 8
Train Loss: 1.3949 | Val Loss: 1.8633 | LR: 0.000800
Epoch: 7/10
100%|██████████| 904/904 [00:47<00:00, 19.21it/s]
We' d like another bottle of wine.
我们想再来一瓶葡萄酒。
我们要再来瓶瓶葡萄酒。
pred_len: 12
Train Loss: 1.1912 | Val Loss: 1.8061 | LR: 0.000640
Epoch: 8/10
100%|██████████| 904/904 [00:46<00:00, 19.32it/s]
May i have something to drink?
我可以喝点东西吗?
我可以喝点什西吗?
pred_len: 10
Train Loss: 1.0838 | Val Loss: 1.8375 | LR: 0.000640
Epoch: 9/10
100%|██████████| 904/904 [00:46<00:00, 19.32it/s]
The lights in the bathroom aren' t working.
洗手间的灯坏掉了。
灯手间后灯水了了。
pred_len: 10
Train Loss: 1.0089 | Val Loss: 1.8237 | LR: 0.000640
Epoch: 10/10
100%|██████████| 904/904 [00:45<00:00, 19.94it/s]
This airplane is capable of carrying 40 passengers at a time.
这架飞机一次可以携带40名乘客。
这架飞机有次乘能携带来0度乘客。
pred_len: 17
Train Loss: 0.8718 | Val Loss: 1.8316 | LR: 0.000512
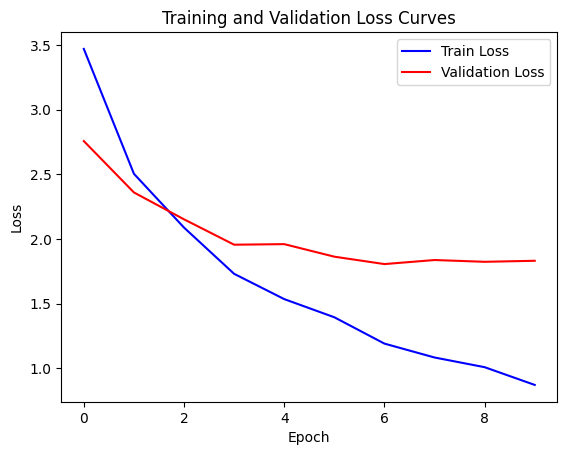
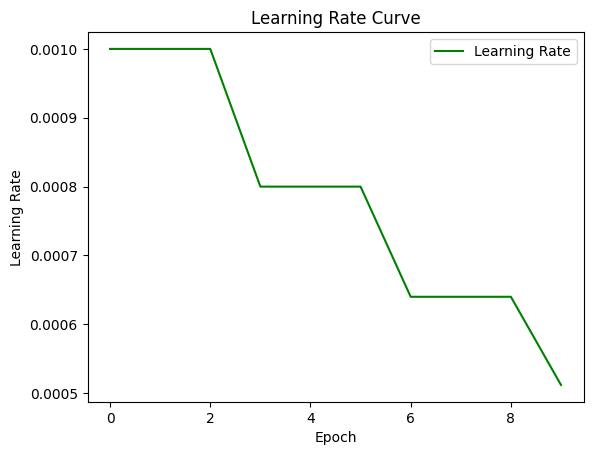
可以看出验证损失基本最低在1.8左右,训练损失在最后一个epoch可以达到0.8,这两个数值我们后面会和pytorch封装的nn.Transformer进行对比。
(七)预测
预测环节和训练环节稍有不同,在执行预测时,已知的是源序列src,目标序列tgt是没有的,需要进行初始化,然后进行自回归的生成。在预处理数据集时,我们将中文序列全部填充到了50,在训练时,解码器的输入和输出分别是tgt[:, :-1]和tgt[:, 1:],因此,实际进入到解码器的序列长度是49。因此,我们首先初始化一个长度为49的初始序列,其第一个token是<sos>,后面补48个<pad>。模型会根据编码器输出和初始化序列,预测<sos>的下一个字符。
例如:
第一步初始化的序列为:<sos> <pad> <pad> <pad> <pad> <pad> <pad>
此时模型预测的结果为:a <pad>' <pad>' <pad>' <pad>' <pad>' <pad>' 【由于<pad>不参与损失计算,预测输出的 <pad>' 实际没有上是没有意义的输出,并非实际的<pad>字符,这里仅用作表示】
取出第一步预测的a,构建第二步输入:<sos> a <pad> <pad> <pad> <pad> <pad>
此时模型预测的结果为:a b <pad>' <pad>' <pad>' <pad>' <pad>'
取出第二步预测的b,构建第三步输入:<sos> a b <pad> <pad> <pad> <pad>,直到预测到<eos>,代表预测结束
在实现中,由于在自回归时,使用的都是相同的编码器输出的memory,因此只需计算一次,在自回归过程中,也就是解码器部分的计算中反复使用。
具体代码如下:
# 没有条件训练可以跳过上一个单元格,加载训练好的模型:transformer_from_scratch.pt
# 加载模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transformer.load_state_dict(torch.load('transformer_from_scratch.pt', map_location=device))
transformer = transformer.to(device)
# 构造一个用于预测的函数
def predict(src):
"""
接收一个源序列,根据源序列,从<sos>开始生成目标序列
src: (batch_size, src_seq_len)
"""
transformer.eval()
# 初始化tgt,从<sos>开始,后面全部填充为<pad>
batch_size = src.size(0) # 获取batch_size
tgt = [cn_dict_token2id['<sos>']] + [cn_dict_token2id['<pad>']] * 48 # 目表序列填充的长度是50,训练时使用49,因此预测时初始化为49
tgt = torch.LongTensor(tgt).unsqueeze(0) # (1, tgt_seq_len)
tgt = tgt.repeat(batch_size, 1) # (batch_size, tgt_seq_len)
# 构造mask
src_mask = make_src_mask(src=src, pad_id=2)
memory_mask = make_memory_mask(src=src, pad_id=2)
# 选择设备
src = src.to(device).long()
src_mask = src_mask.to(device)
memory_mask = memory_mask.to(device)
# 将src的编码器输出存为变量,解码器计算时可以重复使用
src = transformer.positional_encoding(transformer.src_embedding(src))
memory = transformer.encoder(src, src_mask=src_mask)
for i in range(48): # 逐字符生成
tgt_temp = tgt # 赋值给tgt_temp,充当解码器输入,预测的输出更新tgt,而后再返回充当新一轮的解码器输入
# 构造mask
tgt_mask = make_tgt_mask(tgt=tgt_temp, pad_id=2)
tgt_temp = tgt_temp.to(device)
tgt_mask = tgt_mask.to(device)
tgt_temp = transformer.positional_encoding(transformer.tgt_embedding(tgt_temp))
tgt_temp = transformer.decoder(tgt_temp, enc_output=memory, memory_mask=memory_mask, tgt_mask=tgt_mask)
out = transformer.fc_out(tgt_temp) # (batch, tgt_seq_len, tgt_vocab_size)
# 当前预测是第i个词,故取出第i个
# 第一步输入为:<sos> <pad> <pad> <pad> <pad> <pad> <pad>
# 第一步预测为:a <pad>' <pad>' <pad>' <pad>' <pad>' <pad>' (由于<pad>不参与损失计算,预测输出<pad>'实际没有上是没有意义的输出,并非实际的<pad>字符)
# 取出第一步预测的a,构建第二步输入:<sos> a <pad> <pad> <pad> <pad> <pad>
# 第二步预测为:a b <pad>' <pad>' <pad>' <pad>' <pad>',取出第二步预测的b,构建第三步输入:<sos> a b <pad> <pad> <pad> <pad>,直到预测到<eos>结束
out = out[:, i, :] # (batch, tgt_seq_len, tgt_vocab_size) -> (batch, tgt_vocab_len)
# 将预测的logits映射到具体的toekn_id
out = out.argmax(dim=1).detach() # 在tgt_vocab_size维度上取最大值,得到预测的token_id -> (batch,)
# 将本轮预测的词加入到tgt中,用于下一轮预测
tgt[:, i+1] = out
# 如果预测的out为<eos>,说明预测结束,返回tgt
# 本函数仅用于单个字符串预测,因此检查一个序列是否产生<eos>
# 如果预测多个序列,需要添加逻辑用于跟踪所有序列是否均产生<eos>再退出
if out == 1:
return tgt
# 如果未能预测到<eos>,循环结束直接返回tgt
return tgt
现在我们可以做一个测试:
# 实测
english_text = 'This is the first part.'
# 将文本转换成token_id
english_token_id = text2id(english_text, 'en', en_dict_token2id)
print('English token id:', english_token_id)
# 预测
src = torch.tensor(english_token_id).unsqueeze(0) # (1, 45)
predict_token_id = predict(src).squeeze(0).tolist()
print('Predict token id:', predict_token_id)
# 将预测输出的token_id转换成文本
chinese_text = id2text(predict_token_id, 'cn', cn_dict_id2token)
print('Predict chinese text:', chinese_text)
输出结果为:
English token id: [0, 134, 184, 479, 176, 1497, 4, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
Predict token id: [0, 191, 58, 238, 14, 166, 1241, 254, 4, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
Predict chinese text: 这是第一个部分。
基本上简单句式都能翻译出差不多的效果,至此,我们中英翻译的demo部分完成。
三、PyTorch封装的Transformer用法
【注:PyTorch封装的Transformer需要自己实现位置编码和mask】
nn.Transoformer的初始化参数与我们自己手撕的基本一致,这里不重复介绍,要使用nn.Transformer着重要理解forward方法中的参数,尤其是各种涉及到mask的参数。
在nn.Transformer的forward方法中,主要有如下参数:
- src:输入到编码器的序列;对于非 batch 的输入,形状为$(S,E)$,对于 batch 输入,如果 batch_first 为 False,则形状为$(S,N,E)$,如果 batch_first 为 True,则形状为$(N,S,E)$
- tgt:输入到解码器的序列;对于非 batch 的输入,形状为$(T,E)$,对于 batch 输入,如果 batch_first 为 False,则形状为$(T,N,E)$,如果 batch_first 为 True,则形状为$(N,T,E)$
- src_mask:src序列的掩码(可选),形状为$(S,S)$或$(N\cdot num_heads,S,S)$
- tgt_mask:tgt序列的掩码(可选),形状为 $(T,T)$或$(N\cdot num_heads,T,T)$
- memory_mask:编码器输出序列的掩码(可选),形状为$(T,S)$
- src_key_padding_mask:对 src key 的 padding mask(可选),对于非 batch 的输入,形状为$(S)$,对于 batch 输入,形状为$(N,S)$
- tgt_key_pdding_mask:对 tgt key 的 padding mask(可选),对于非 batch 的输入,形状为$(T)$,对于 batch 输入,形状为$(N,T)$
- memory_key_padding_mask:对 memory key 的 padding mask(可选),对于非 batch 的输入,形状为$(S)$,对于 batch 输入,形状为$(N,S)$
【其中,$N$为 batch 大小,$S$为 source length,$T$为 target length,$E$为 embedding。可以这样理解:前三个mask可以理解为可以自由实现的任意mask,一般主要是用于传入sequence mask,后三个 mask 均为 padding mask,相当于将编码器、解码器、编码器-解码器的多头注意力所使用到的三种mask进行了区分,每种mask都划分为padding mask和sequence mask两种,相同位置的mask会在内部进行合并。】
【注:nn.Transformer 的mask在True的时候才遮蔽,False的时候不遮蔽!!!我们上面自己实现的mask是1不遮蔽,而0是遮蔽。】
简单来说,pytorch中所有(src/tgt/memory)_mask设计为用户自由传入的mask,而所有(src/tgt/memory)_key_padding_mask是专门用于传入padding mask的,当然你也可以将mask全部设计组合好,传入(src/tgt/memory)_mask,而不在(src/tgt/memory)_key_padding_mask中传入任何mask,不过既然pytorch这么封装了参数,我们就按照所设计的那样来传入。
如果和我们自己手撕的mask进行对比,那么对应关系为:
我们的src_mask=pytorch的src_key_padding_mask,均为padding mask;
我们的memory_mask=pytorch的memory_key_padding_mask,均为padding mask;
我们的tgt_mask=pytorch的tgt_key_padding_mask+tgt_mask,为padding mask和sequence mask的组合。
模型定义如下:
# nn.Transformer没有实现Embedding,PositionalEncoding和最后的Linear, 因此需要自己封装
class TorchTransformer(nn.Module):
def __init__(self,
src_vocab_size,
tgt_vocab_size,
d_model,
nhead,
num_encoder_layers,
num_decoder_layers,
dim_feedforward,
max_seq_length,
dropout=0.1):
super(TorchTransformer, self).__init__()
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout, batch_first=True)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, src, tgt, src_pad_mask, tgt_pad_mask, tgt_seq_mask): # tgt的padding mask和sequence mask可以分别传入,模型内会进行合并
src = self.dropout(self.positional_encoding(self.src_embedding(src))) # (batch,src_seq_len)->(batch,src_seq_len,d_model)
tgt = self.dropout(self.positional_encoding(self.tgt_embedding(tgt))) # (batch,tgt_seq_len)->(batch,tgt_seq_len,d_model)
# 编码器中的多头注意力使用src_key_padding_mask,传入的是src_pad_mask
# 解码器中的多头注意力使用tgt_key_padding_mask和tgt_mask,传入的是tgt_pad_mask和tgt_seq_mask,二者会进行合并
# 解码器中的交叉注意力使用memory_key_padding_mask,传入的是src_pad_mask
output = self.transformer(src, tgt, tgt_mask=tgt_seq_mask, src_key_padding_mask=src_pad_mask, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask)
output = self.fc_out(output)
return output
四、使用PyTorch封装的Transformer模型完成中英翻译demo
(一)构建模型
接下来我们使用第二部分相同的数据集来进行nn.Transformer的中英翻译demo。前面的数据准备部分不再重复,直接构建模型,为了进行区分,我们将此模型命名为torch_transformer:
# 整体流程与第二部分相同,不同的是传入的mask的部分,mask需要传入bool形式,True表示遮蔽
# 运行此部分代码需要第二部分的(一)至(四)的代码块已经运行过,部分变量已经在内存中
# 构建模型
torch_transformer = TorchTransformer(
src_vocab_size=en_vocab_size,
tgt_vocab_size=cn_vocab_size,
d_model=256,
nhead=8,
num_encoder_layers=3,
num_decoder_layers=3,
dim_feedforward=1024,
max_seq_length=100,
dropout=0.1
)
trainable_params = sum(p.numel() for p in torch_transformer.parameters() if p.requires_grad)
print(f"Total number of trainable parameters: {trainable_params}")
import torch.nn.init as init
# nn.Transformer默认的初始化方式是Xavier,在此数据集下,我们定义的学习率调度和迭代次数训练效果并不理想
# 我们这里将初始化方式改为pytorch默认的方式,能够得到较好的效果,这是个有趣的现象
def reset_to_default_init(module):
if isinstance(module, nn.Linear):
# PyTorch 默认初始化方式:Kaiming 均匀分布
init.kaiming_uniform_(module.weight, a=math.sqrt(5))
if module.bias is not None:
# PyTorch 默认的偏置初始化
fan_in, _ = init._calculate_fan_in_and_fan_out(module.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(module.bias, -bound, bound)
elif isinstance(module, nn.Embedding):
# 对于 nn.Embedding 使用默认的均匀分布初始化
init.uniform_(module.weight, -1.0, 1.0)
elif isinstance(module, nn.LayerNorm):
# PyTorch 默认方式:权重初始化为1,偏置初始化为0
if module.weight is not None:
init.constant_(module.weight, 1.0)
if module.bias is not None:
init.constant_(module.bias, 0.0)
torch_transformer.apply(reset_to_default_init)
输出为:
Total number of trainable parameters: 8828183
TorchTransformer(
(src_embedding): Embedding(7192, 256)
(tgt_embedding): Embedding(2839, 256)
(positional_encoding): PositionalEncoding()
(transformer): Transformer(
(encoder): TransformerEncoder(
(layers): ModuleList(
(0-2): 3 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=1024, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=1024, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(decoder): TransformerDecoder(
(layers): ModuleList(
(0-2): 3 x TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=1024, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=1024, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(fc_out): Linear(in_features=256, out_features=2839, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
这里我们将torch_transformer中的参数初始化方式进行了重新设置。
在nn.Transformer中,参数初始化方式默认为 xavier均匀分布 方式,如下图所示:

这里我发现了有趣的现象,如果使用nn.Transformer默认的 xavier均匀分布 方式进行参数初始化,在我们设置的学习参数下,训练损失在10个epoch后只能下降到2.几,虽然可能可以通过调整学习率调度来解决这一问题,但也为了和我们手撕模型进行对比,我们将nn.Transformer的参数初始化方式调整为pytorch模块默认的初始化方式。
nn.Transformer的参数初始化主要改变了其中nn.Linear的初始化方式,而nn.Linear原本的参数初始化方式如下:

因此,我们将模型中的所有nn.Linear恢复成原本的初始化方式:
import torch.nn.init as init
# nn.Transformer默认的初始化方式是Xavier,在此数据集下,我们定义的学习率调度和迭代次数训练效果并不理想
# 我们这里将初始化方式改为pytorch默认的方式,能够得到较好的效果,这是个有趣的现象
def reset_to_default_init(module):
if isinstance(module, nn.Linear):
# PyTorch 默认初始化方式:Kaiming 均匀分布
init.kaiming_uniform_(module.weight, a=math.sqrt(5))
if module.bias is not None:
# PyTorch 默认的偏置初始化
fan_in, _ = init._calculate_fan_in_and_fan_out(module.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(module.bias, -bound, bound)
torch_transformer.apply(reset_to_default_init)
输出为:
TorchTransformer(
(src_embedding): Embedding(7192, 256)
(tgt_embedding): Embedding(2839, 256)
(positional_encoding): PositionalEncoding()
(transformer): Transformer(
(encoder): TransformerEncoder(
(layers): ModuleList(
(0-2): 3 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=1024, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=1024, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(decoder): TransformerDecoder(
(layers): ModuleList(
(0-2): 3 x TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=1024, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=1024, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(fc_out): Linear(in_features=256, out_features=2839, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(二)训练
训练环节与第二部大体相同,只是构造mask时略有不同:
# 定义参数
num_epochs = 10
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch_transformer = torch_transformer.to(device)
loss_func = torch.nn.CrossEntropyLoss(ignore_index=2) # 计算损失时,忽略掉pad_id部分的计算
optimizer = torch.optim.AdamW(torch_transformer.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.8) # 每隔固定数量的epoch将学习率减少一个固定的比例
train_loss_curve = []
val_loss_curve = []
lr_curve = []
# 训练和验证
for epoch in range(num_epochs):
print(f'Epoch: {epoch+1}/{num_epochs}')
torch_transformer.train()
loss_sum = 0.0
# 训练----------------------------------------------------
for step, (src, tgt) in tqdm(enumerate(train_loader), total=len(train_loader)):
# src: (batch_size, 45)
# tgt: (batch_size, 50)
####################################################
if step % (len(train_loader)-1) == 0 and step != 0:
print(id2text(src[0].tolist(), 'en', en_dict_id2token))
print(id2text(tgt[0].tolist(), 'cn', cn_dict_id2token))
####################################################
# 构造mask 【此处构造适合nn.Transformer的mask】
src_pad_mask = make_padding_mask(src, pad_id=2, return_int=False, true_to_mask=True) # (batch_size, seq_len)
tgt_pad_mask = make_padding_mask(tgt[:, :-1], pad_id=2, return_int=False, true_to_mask=True) # (batch_size, seq_len)
tgt_seq_mask = make_sequence_mask(tgt[:, :-1], return_int=False, true_to_mask=True) # 需传入(T, T)或(N*num_heads, T, T)的形状,这里我们就传入(T, T),即(seq_len, seq_len)
####################################################
if epoch == 0 and step == 0:
# print(src_pad_mask.shape)
# print(src_pad_mask)
# print(tgt_pad_mask.shape)
# print(tgt_pad_mask)
# print(tgt_seq_mask.shape)
# print(tgt_seq_mask)
plt.imshow(src_pad_mask.numpy(), cmap='viridis', interpolation='nearest')
plt.colorbar() # 添加颜色条
plt.title('src_pad_mask')
plt.show()
plt.imshow(tgt_pad_mask.numpy(), cmap='viridis', interpolation='nearest')
plt.colorbar() # 添加颜色条
plt.title('tgt_pad_mask')
plt.show()
plt.imshow(tgt_seq_mask.numpy(), cmap='viridis', interpolation='nearest')
plt.colorbar() # 添加颜色条
plt.title('tgt_seq_mask')
plt.show()
####################################################
src = src.to(device).long()
tgt = tgt.to(device).long()
src_pad_mask = src_pad_mask.to(device)
tgt_pad_mask = tgt_pad_mask.to(device)
tgt_seq_mask = tgt_seq_mask.to(device)
# 训练时,是由输入的tgt预测下一个字符,因此输入为tgt[:, :-1],每一个位置的字符在看见前面已有字符的情况下预测下一个字符
# 例如,tgt为: <sos> a b c d e <eos> <pad> <pad>,那么输入为:<sos> a b c d e <eos> <pad>,真值为:a b c d e <eos> <pad> <pad>
# 假设预测输出为:a' b' c' d' e' <eos> <pad> <pad>,该预测输出需要与真实值进行交叉熵计算损失,为避免<pad>对有效token的影响,计算损失时<pad>位置不参与
# 因此实际需要计算的是:a b c d e <eos> 与 a' b' c' d' e' <eos>的对应字符位置损失
pred = torch_transformer(src, tgt[:, :-1], src_pad_mask, tgt_pad_mask, tgt_seq_mask)
####################################################
if step % (len(train_loader)-1) == 0 and step != 0:
test_pred = pred[0] # (seq_len, vocab_size)
test_pred = test_pred.argmax(dim=1) # (seq_len,)
test_pred = test_pred.tolist() # 转换成装了token_id的列表
if 1 in test_pred:
eos_index = test_pred.index(1) # 找到<eos>索引
test_pred = test_pred[:eos_index+1]
print(id2text(test_pred, 'cn', cn_dict_id2token))
print('pred_len:', len(test_pred))
####################################################
# 调整形状以计算损失
pred = pred.contiguous().view(-1, pred.shape[-1]) # (batch_size, seq_len, cn_vocab_size) -> (batch_size * seq_len, cn_vocab_size)
target = tgt[:, 1:].contiguous().view(-1) # (batch_size, seq_len) -> (batch_size * seq_len)
loss = loss_func(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item() # 当前epoch的累计损失
train_avg_loss = loss_sum / len(train_loader)
lr = optimizer.param_groups[0]['lr']
train_loss_curve.append(train_avg_loss)
lr_curve.append(lr)
scheduler.step()
# 验证----------------------------------------------------
torch_transformer.eval()
loss_sum = 0.0
for step, (src, tgt) in enumerate(val_loader):
# 构造mask 【此处构造适合nn.Transformer的mask】
src_pad_mask = make_padding_mask(src, pad_id=2, return_int=False, true_to_mask=True) # (batch_size, seq_len)
tgt_pad_mask = make_padding_mask(tgt[:, :-1], pad_id=2, return_int=False, true_to_mask=True) # (batch_size, seq_len)
tgt_seq_mask = make_sequence_mask(tgt[:, :-1], return_int=False, true_to_mask=True) # 需传入(T, T)或(N*num_heads, T, T)的形状,这里我们就传入(T, T),即(seq_len, seq_len)
src = src.to(device).long()
tgt = tgt.to(device).long()
src_pad_mask = src_pad_mask.to(device)
tgt_pad_mask = tgt_pad_mask.to(device)
tgt_seq_mask = tgt_seq_mask.to(device)
pred = torch_transformer(src, tgt[:, :-1], src_pad_mask, tgt_pad_mask, tgt_seq_mask)
pred = pred.contiguous().view(-1, pred.shape[-1])
target = tgt[:, 1:].contiguous().view(-1)
loss = loss_func(pred, target)
loss_sum += loss.item()
val_avg_loss = loss_sum / len(val_loader)
val_loss_curve.append(val_avg_loss)
print(f'Train Loss: {train_avg_loss:.4f} | Val Loss: {val_avg_loss:.4f} | LR: {lr:.6f}')
# 保存模型
torch.save(torch_transformer.state_dict(), 'transformer_from_torch.pt')
# 绘制损失曲线
plt.figure()
plt.plot(train_loss_curve, label='Train Loss', color='blue')
plt.plot(val_loss_curve, label='Validation Loss', color='red')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss Curves')
plt.legend()
plt.show()
# 绘制学习率曲线
plt.figure()
plt.plot(lr_curve, label='Learning Rate', color='green')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Curve')
plt.legend()
plt.show()
所构造的mask可视化如下:
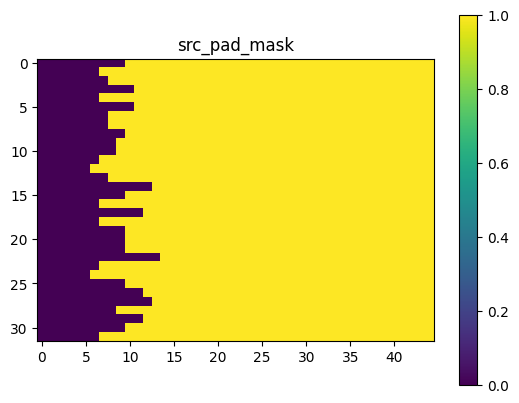
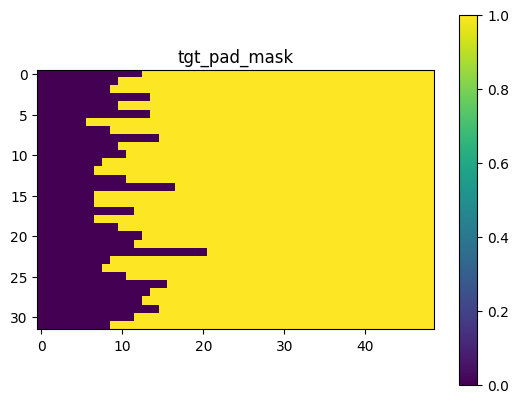
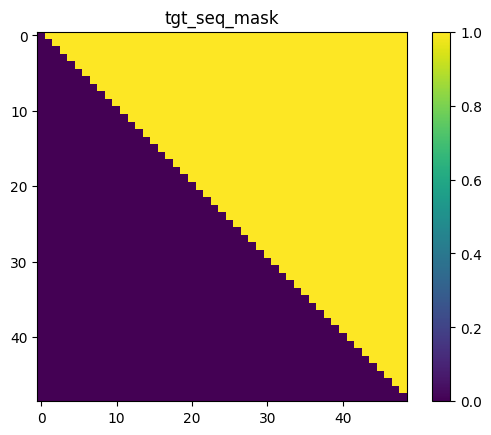
训练结果如下:
Epoch: 1/10
100%|██████████| 904/904 [00:45<00:00, 20.01it/s]
Skating is one of my hobbies.
滑冰是我的嗜好之一。
我他子我的。。人间个
pred_len: 11
Train Loss: 3.4991 | Val Loss: 2.7074 | LR: 0.001000
Epoch: 2/10
100%|██████████| 904/904 [00:42<00:00, 21.25it/s]
Tom doesn' t even talk to mary anymore.
汤姆甚至不和玛丽说话了。
汤姆不么不跟玛丽说话。。
pred_len: 13
Train Loss: 2.5295 | Val Loss: 2.2795 | LR: 0.001000
Epoch: 3/10
100%|██████████| 904/904 [00:44<00:00, 20.22it/s]
They killed time playing cards.
他们玩牌来杀时间。
他们打笑。玩。间玩
pred_len: 10
Train Loss: 2.1220 | Val Loss: 2.1049 | LR: 0.001000
Epoch: 4/10
100%|██████████| 904/904 [00:43<00:00, 20.60it/s]
This is not safe.
这不安全。
这不是全。
pred_len: 6
Train Loss: 1.7576 | Val Loss: 1.9168 | LR: 0.000800
Epoch: 5/10
100%|██████████| 904/904 [00:42<00:00, 21.16it/s]
Do you need help?
你需要帮助吗?
你需要帮忙吗?
pred_len: 8
Train Loss: 1.5634 | Val Loss: 1.8825 | LR: 0.000800
Epoch: 6/10
100%|██████████| 904/904 [00:43<00:00, 20.60it/s]
I asked tom to play the guitar.
我叫汤姆弹吉他。
我请汤姆。吉他。
pred_len: 9
Train Loss: 1.4200 | Val Loss: 1.8326 | LR: 0.000800
Epoch: 7/10
100%|██████████| 904/904 [00:42<00:00, 21.48it/s]
What do you want it for?
您要它干什么?
你要什做什么?
pred_len: 8
Train Loss: 1.2173 | Val Loss: 1.7646 | LR: 0.000640
Epoch: 8/10
100%|██████████| 904/904 [00:44<00:00, 20.22it/s]
I didn' t get the point of his speech.
我没有抓到他演讲的重点。
我没收收到他的讲的演。。
pred_len: 13
Train Loss: 1.1094 | Val Loss: 1.7611 | LR: 0.000640
Epoch: 9/10
100%|██████████| 904/904 [00:42<00:00, 21.12it/s]
This is only one of the things we found.
这只是我们发现的东西之一。
这只是我们找现的一西。一个
pred_len: 14
Train Loss: 1.0284 | Val Loss: 1.7942 | LR: 0.000640
Epoch: 10/10
100%|██████████| 904/904 [00:42<00:00, 21.48it/s]
I looked, but i didn' t see anything.
我看过了, 但是没看到什么东西。
我什了,, 但什没看到看么。西。
pred_len: 17
Train Loss: 0.8901 | Val Loss: 1.7749 | LR: 0.000512
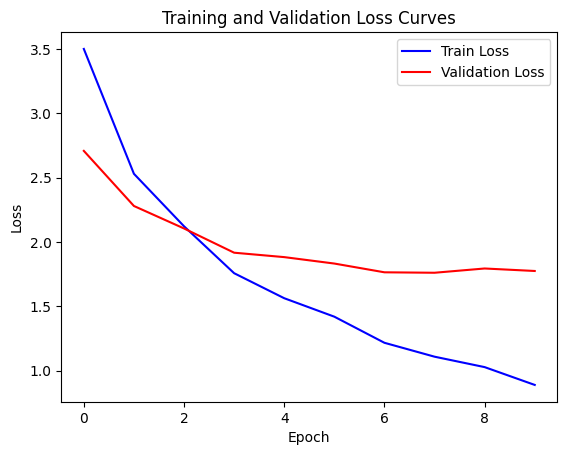
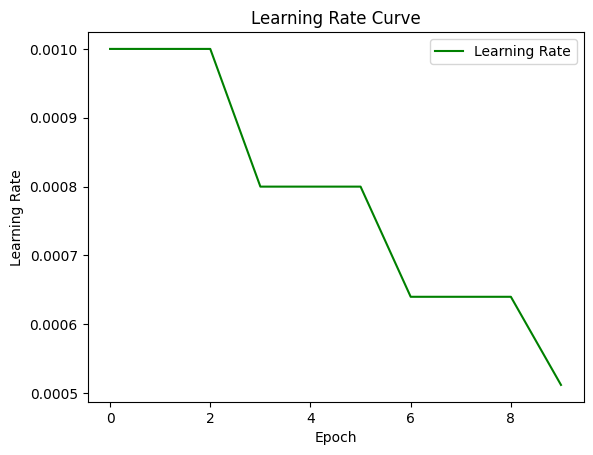
到此,封装的nn.Transformer也已训练完毕,经过10个epoch的训练,其训练损失和验证损失与第二部分大体一致,因此我们自己手撕的transformer和nn.Transformer在性能上基本相当,不过nn.Transformer当然会在封装中实现更多细节。
如果使用nn.Transformer默认的参数初始化方法,在此数据集和我们设置的训练条件下,收敛的速度会更慢,可见 参数初始化对模型训练也具有非常重要的影响,这一点后续进行研究。
(三)预测
预测部分也与第二部分基本一致,只做mask部分的修改:
# 没有条件训练可以跳过上一个单元格,加载训练好的模型:transformer_from_scratch.pt
# 加载模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch_transformer.load_state_dict(torch.load('transformer_from_torch.pt', map_location=device))
torch_transformer = torch_transformer.to(device)
# 构造一个用于预测的函数
def predict_torch(src):
"""
接收一个源序列,根据源序列,从<sos>开始生成目标序列
src: (batch_size, src_seq_len)
"""
torch_transformer.eval()
# 初始化tgt,从<sos>开始,后面全部填充为<pad>
batch_size = src.size(0) # 获取batch_size
tgt = [cn_dict_token2id['<sos>']] + [cn_dict_token2id['<pad>']] * 48 # 目表序列填充的长度是50,训练时使用49,因此预测时初始化为49
tgt = torch.LongTensor(tgt).unsqueeze(0) # (1, tgt_seq_len)
tgt = tgt.repeat(batch_size, 1) # (batch_size, tgt_seq_len)
# 构造mask 【这里只构造src_pad_mask,也就是第二部分的src_mask,实际上src_mask和memory_mask是构造时是相同的,只是内部实现时广播后的维度有区别】
src_pad_mask = make_padding_mask(src, pad_id=2, return_int=False, true_to_mask=True)
# 选择设备
src = src.to(device).long()
src_pad_mask = src_pad_mask.to(device)
# 将src的编码器输出存为变量,解码器计算时可以重复使用
src = torch_transformer.positional_encoding(torch_transformer.src_embedding(src))
# 【这里需使用nn.Transformer类内定义的encoder,后面有涉及到的也是一样,传入参数需参考官方文档,这里我们只用为关键字src和src_key_padding_mask传入值】
memory = torch_transformer.transformer.encoder(src=src, src_key_padding_mask=src_pad_mask)
for i in range(48): # 逐字符生成
tgt_temp = tgt # 赋值给tgt_temp,充当解码器输入,预测的输出更新tgt,而后再返回充当新一轮的解码器输入
# 构造mask 【这里构造tgt的mask,分别为tgt_pad_mask和tgt_seq_mask,二者会在模型内部合并。在第二部分中,我们是在模型外通过定义函数合并的】
tgt_pad_mask = make_padding_mask(tgt_temp, pad_id=2, return_int=False, true_to_mask=True)
tgt_seq_mask = make_sequence_mask(tgt_temp, return_int=False, true_to_mask=True)
tgt_temp = tgt_temp.to(device)
tgt_pad_mask = tgt_pad_mask.to(device)
tgt_seq_mask = tgt_seq_mask.to(device)
tgt_temp = torch_transformer.positional_encoding(torch_transformer.tgt_embedding(tgt_temp))
tgt_temp = torch_transformer.transformer.decoder(tgt=tgt_temp, memory=memory, tgt_mask=tgt_seq_mask, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask)
out = torch_transformer.fc_out(tgt_temp) # (batch, tgt_seq_len, tgt_vocab_size)
# 当前预测是第i个词,故取出第i个
# 第一步输入为:<sos> <pad> <pad> <pad> <pad> <pad> <pad>
# 第一步预测为:a <pad>' <pad>' <pad>' <pad>' <pad>' <pad>' (由于<pad>不参与损失计算,预测输出<pad>'实际没有上是没有意义的输出,并非实际的<pad>字符)
# 取出第一步预测的a,构建第二步输入:<sos> a <pad> <pad> <pad> <pad> <pad>
# 第二步预测为:a b <pad>' <pad>' <pad>' <pad>' <pad>',取出第二步预测的b,构建第三步输入:<sos> a b <pad> <pad> <pad> <pad>,直到预测到<eos>结束
out = out[:, i, :] # (batch, tgt_seq_len, tgt_vocab_size) -> (batch, tgt_vocab_len)
# 将预测的logits映射到具体的toekn_id
out = out.argmax(dim=1).detach() # 在tgt_vocab_size维度上取最大值,得到预测的token_id -> (batch,)
# 将本轮预测的词加入到tgt中,用于下一轮预测
tgt[:, i+1] = out
# 如果预测的out为<eos>,说明预测结束,返回tgt
# 本函数仅用于单个字符串预测,因此检查一个序列是否产生<eos>
# 如果预测多个序列,需要添加逻辑用于跟踪所有序列是否均产生<eos>再退出
if out == 1:
return tgt
# 如果未能预测到<eos>,循环结束直接返回tgt
return tgt
# 实测
english_text = 'This is the last part.'
# 将文本转换成token_id
english_token_id = text2id(english_text, 'en', en_dict_token2id)
print('English token id:', english_token_id)
# 预测
src = torch.tensor(english_token_id).unsqueeze(0) # (1, 45)
predict_token_id = predict_torch(src).squeeze(0).tolist()
print('Predict token id:', predict_token_id)
# 将预测输出的token_id转换成文本
chinese_text = id2text(predict_token_id, 'cn', cn_dict_id2token)
print('Predict chinese text:', chinese_text)
预测结果为:
English token id: [0, 134, 184, 479, 1105, 1497, 4, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
Predict token id: [0, 191, 58, 579, 1043, 9, 1241, 254, 4, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
Predict chinese text: 这是最终的部分。
至此,我们关于Transformer的手撕代码就完成了。
参考链接
- Attention Is All You Need
- Transformer模型详解,Attention is all you need
- “AI”科普丨Transformer架构图解最强教程!
- Pytorch nn.Transformer的mask理解
- 如何理解attention中的Q,K,V?
- The Annotated Transformer
- 【Transformer系列】深入浅出理解Positional Encoding位置编码-CSDN博客
- 手撕Transformer!!从每一模块原理讲解到代码实现【超详细!】
- Transformer — PyTorch 2.3 documentation