【论文解读】DeepSeek-V3
Categories: Paper
目录
概览
DeepSeek-V3是一个包含671B参数量的大型混合专家(Mixture-of-Experts,MoE)模型,其中每个token的激活参数为37B。其基本架构主要包括:
- 多头潜在注意力(Multi-head Latent Attention,MLA)——用于高效推理
- 混合专家模型架构(DeepSeekMoE)——用于高效训练
除了基本架构之外,主要使用了两种策略来进一步提升模型性能:
- 无辅助损失负载均衡策略(auxiliary-loss-free strategy for load balancing)
- 多token预测(multi-token prediction,MTP)
为了实现高效训练,支持FP8混合精度训练,并对训练框架进行了全面优化,提出了DualPipe算法实现流水线高效并行处理。训练阶段主要包括:
- 在14.8T高质量且多样的tokens上进行预训练阶段(pre-training)
- 两阶段的上下文长度扩展,第一阶段扩展至32K,第二阶段扩展至128K
- 后训练阶段(post-training),包括监督微调(Supervised Fine-Tuning,SFT)和强化学习(Reinforcement Learning,RL)
一、模型架构
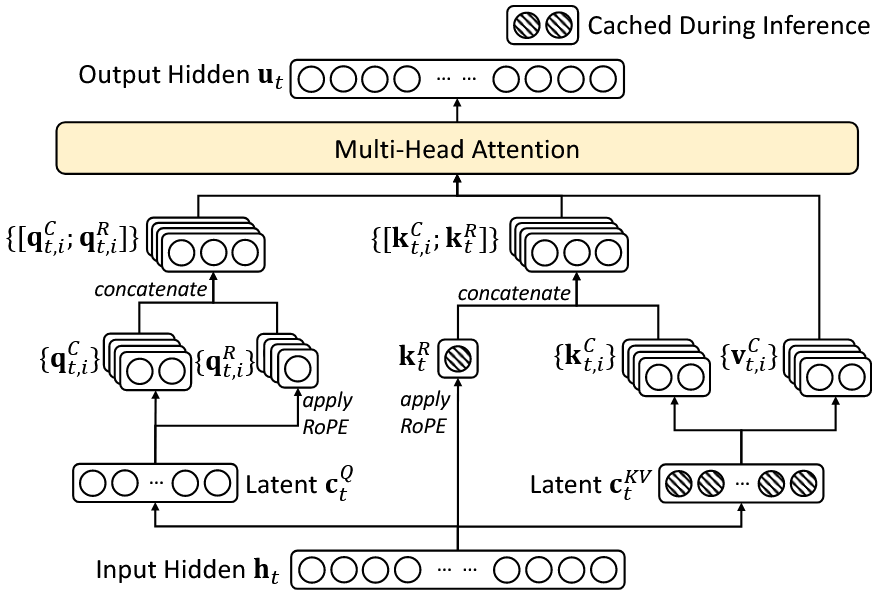
DeepSeek-V3的基本架构如图所示:
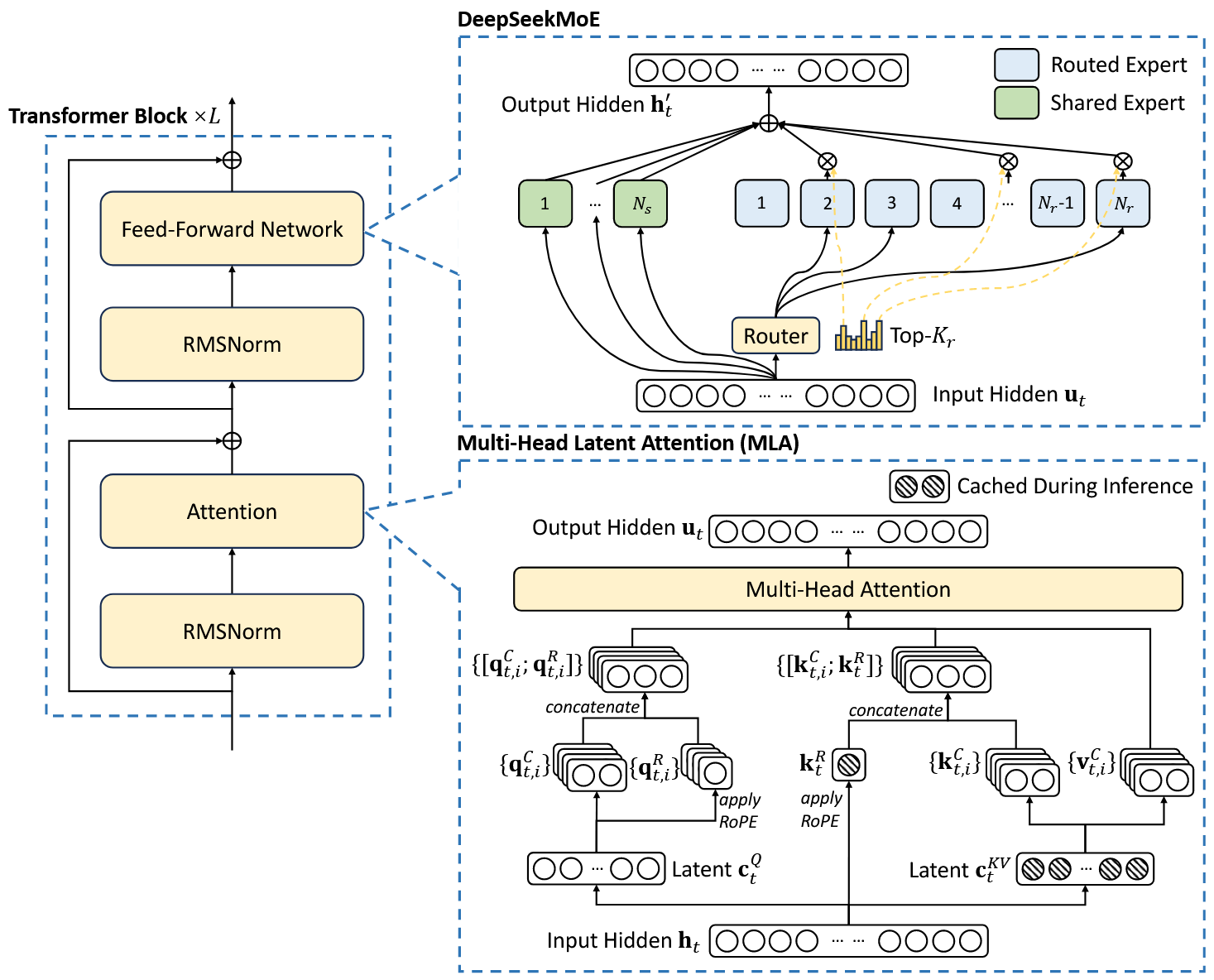
在DeepSeek-V2中,就已经使用了MLA和DeepSeekMoE,这两部分我们结合DeepSeek-V2论文来看。
(一)多头潜在注意力MLA
对于注意力机制,DeepSeek-V3采用了MLA架构。首先做出以下符号定义:
- $d$ :嵌入维度
- $n_h$ :注意力头数
- $d_h$ :每个注意力头的维度
- $\mathbf{h}_t \in \mathbb{R}^d$ :在给定注意力层中第 $t$ 个token的输入
1. 回顾多头注意力MHA
多头注意力(Multi-Head Attention,MHA)首先通过三个矩阵 $W^Q, W^K, W^V \in \mathbb{R}^{d_h n_h \times d}$ 分别产生 $\mathbf{q}_t, \mathbf{k}_t, \mathbf{v}_t \in \mathbb{R}^{d_h n_h}$ :
\[\begin{align} \mathbf{q}_t &= W^Q \mathbf{h}_t, \\ \mathbf{k}_t &= W^K \mathbf{h}_t, \\ \mathbf{v}_t &= W^V \mathbf{h}_t, \end{align}\]$\mathbf{q}_t, \mathbf{k}_t, \mathbf{v}_t$ 将会划分成 $n_h$ 个注意力头来执行多头注意力计算:
\[\begin{align} [\mathbf{q}_{t,1}; \mathbf{q}_{t,2}; \ldots; \mathbf{q}_{t,n_h}] = \mathbf{q}_t, \\ [\mathbf{k}_{t,1}; \mathbf{k}_{t,2}; \ldots; \mathbf{k}_{t,n_h}] = \mathbf{k}_t, \\ [\mathbf{v}_{t,1}; \mathbf{v}_{t,2}; \ldots; \mathbf{v}_{t,n_h}] = \mathbf{v}_t, \\ \mathbf{o}_{t,i} = \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{\mathbf{q}_{t,i}^\top \mathbf{k}_{j,i} }{\sqrt{d_h} } \right) &\mathbf{v}_{j,i}, \\ \mathbf{u}_t = W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; \ldots; \mathbf{o}_{t,n_h}], \end{align}\]其中:
- $\mathbf{q}_{t,i}, \mathbf{k}_{t,i}, \mathbf{v}_{t,i} \in \mathbb{R}^{d_h}$ :
querykeyvalue的第 $i$ -th 个注意力头 - $W^O \in \mathbb{R}^{d \times d_h n_h}$ :输出投影矩阵
- $\text{Softmax}_j$ :对位置 $j=1$ 到 $t$ 的注意力权重进行归一化
在推理阶段,所有的 keys values 需要被缓存,从而加速推理。因此MHA需要对每个token缓存 $2n_h d_h l$ ( $l$ 为模型的层数),过大的 KV Cache 严重限制了模型的 batch size 和 sequence length 。
2. 低秩KV联合压缩
MLA的核心是通过低秩联合压缩注意力的 keys 和 values ,以减少推理过程中的 KV Cache 。
其中:
- $\mathbf{c}_t^{KV} \in \mathbb{R}^{d_c}$ :
keys和values的压缩潜在向量 - $d_c (\ll d_h n_h)$ :KV压缩维度
- $W^{DKV} \in \mathbb{R}^{d_c \times d}$ :下投影矩阵
- $W^{UK}, W^{UV} \in \mathbb{R}^{d_h n_h \times d_c}$ :
keys和values的上投影矩阵
在推理时,MLA仅需要对 $\color{red}{\mathbf{c}_t^{KV} }$ 进行缓存,每个token仅需缓存 $d_c l$ 个元素,从而使 KV Cache 显著减少,同时保持与标准多头注意力(MHA)相当的性能。
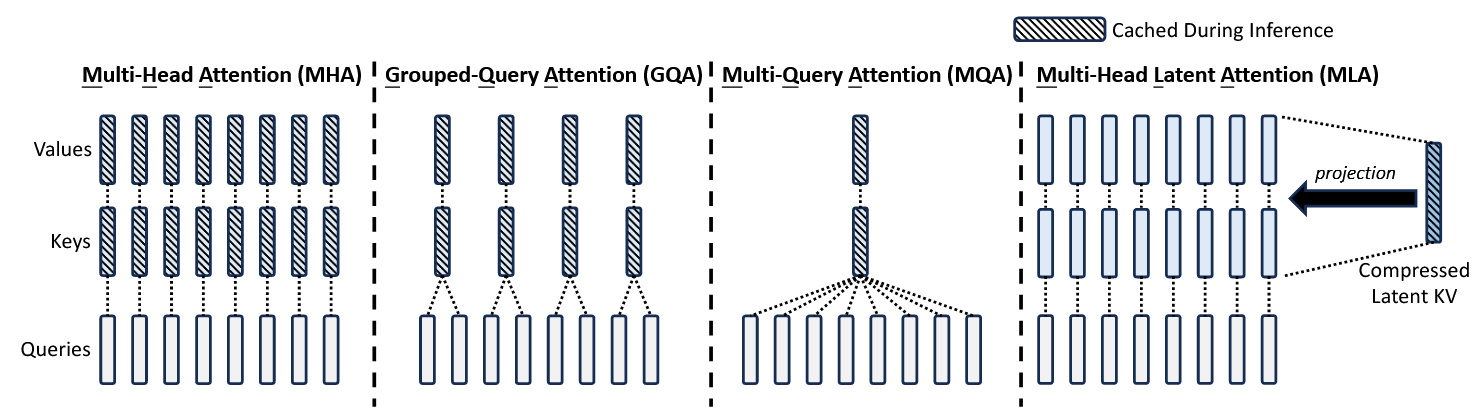
下图对比了多头注意力(MHA),分组查询注意力(GQA),多查询注意力(MQA)和多头潜在注意力(MLA)的区别。
此外,为了减少训练时的激活内存,对 querys 也进行了低秩压缩:
其中:
- $\mathbf{c}_t^Q \in \mathbb{R}^{d_c’}$ :
queries的压缩潜在向量 - $d_c’ (\ll d_h n_h)$ :Q压缩维度
- $W^{DQ} \in \mathbb{R}^{d_c’ \times d}$, $W^{UQ} \in \mathbb{R}^{d_h n_h \times d_c’}$ :
queries的下投影和上投影矩阵
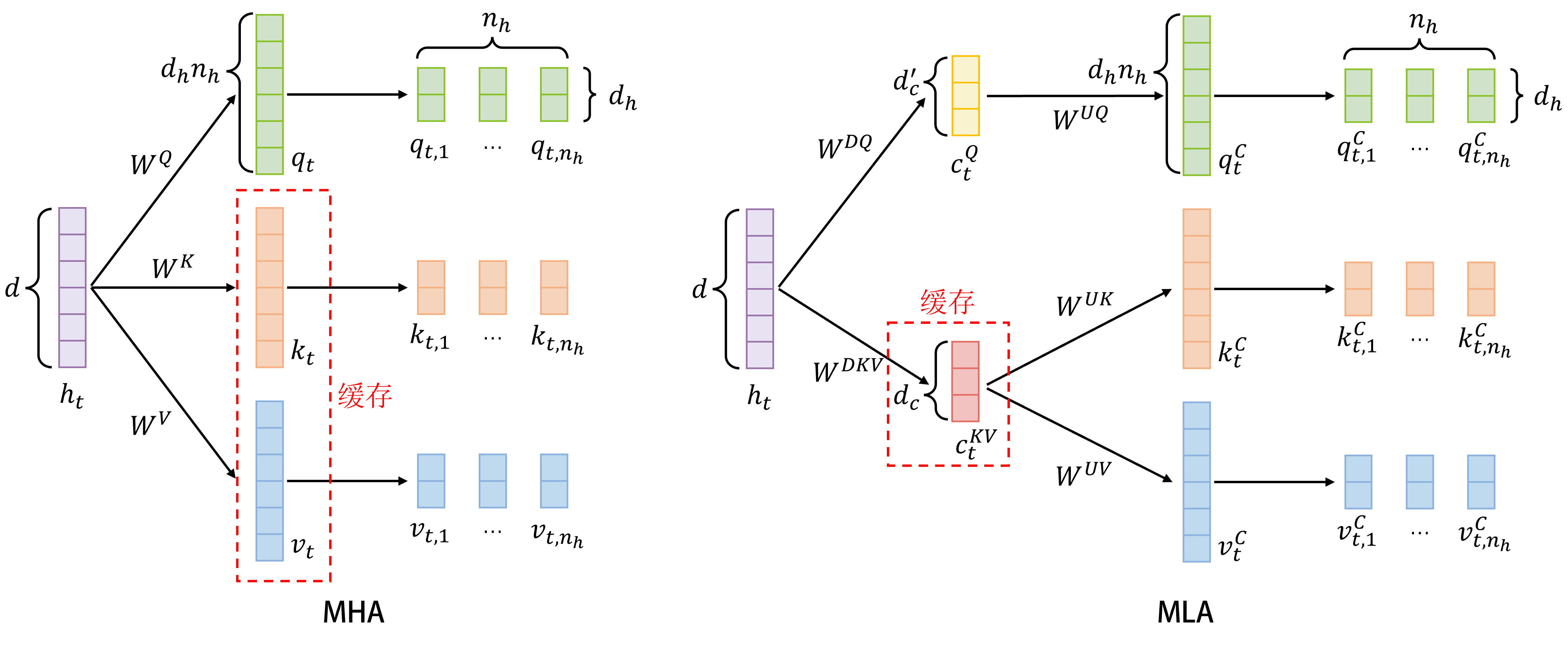
下图更进一步对比了MHA和MLA之间的差异:
【思考】原文中提到:In addition, during inference, since $W^{UK}$ can be absorbed into $W^Q$, and $W^{UV}$ can be absorbed into $W^O$, we even do not need to compute keys and values out for attention. 这句话怎么理解?
我们以一个注意力头为例,公式 $\eqref{eq:1}$ 可以写为:
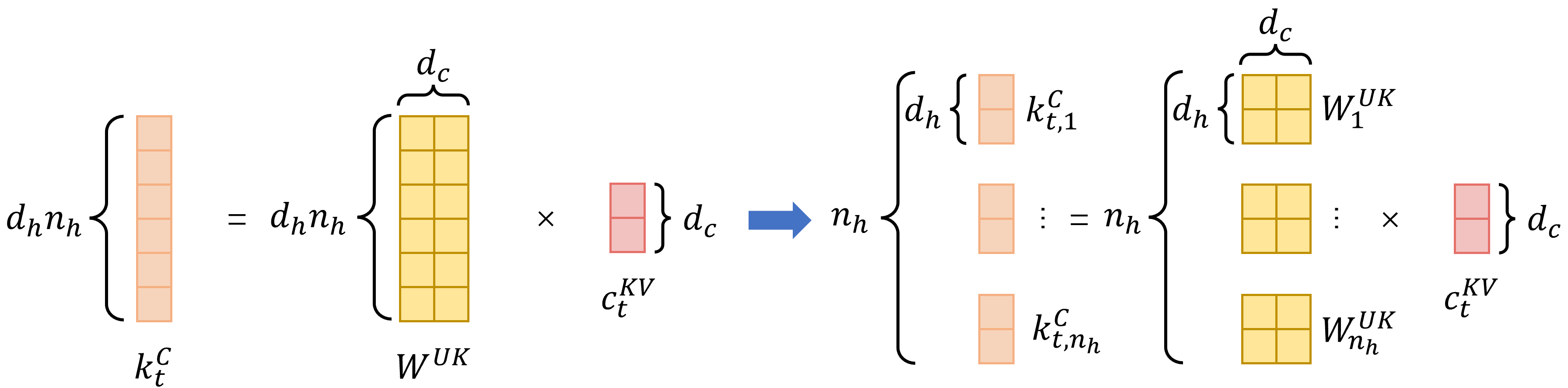
\[\begin{align} [\mathbf{k}_{t,1}^C; \mathbf{k}_{t,2}^C; \ldots; \mathbf{k}_{t,n_h}^C] = \mathbf{k}_t^C = W^{UK} \mathbf{c}_t^{KV} \end{align}\]其中,$\mathbf{k}_{t,i}^C \in \mathbb{R}^{d_h}$ 是每一个注意力头在执行注意力计算时的 key 。进一步,可以写为:
其中,$W_i^{UK} \in \mathbb{R}^{d_h \times d_c}$ 。转换成多头的过程,可以看作是矩阵的拼接计算,因此可将多头看作是 $W^{UK}$ 划分为多个 $W_i^{UK}$ 并与 $\mathbf{c}_t^{KV}$ 相乘得到的,每个头的 query 和 value 的计算过程也类似。下图描述了这个过程:
我们现在聚焦到第 $i$ 个头的注意力分数计算,根据上面的多头转换过程,可得第 $i$ 个头的 query key value 为:
一个注意力头在计算注意力分数时,有:
\[\begin{align} \mathbf{o}_{t,i} &= \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{ {\mathbf{q}_{t,i}^C}^\top \mathbf{k}_{j,i}^C}{\sqrt{d_h} } \right) \mathbf{v}_{j,i}^C \label{eq:2}\\ \mathbf{u}_t &= W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; \ldots; \mathbf{o}_{t,n_h}] \end{align}\]进一步,得到:
\[\begin{align} {\mathbf{q}_{t,i}^C}^\top \mathbf{k}_{j,i}^C &= (W_i^{UQ} \mathbf{c}_t^{Q})^\top W_i^{UK} \mathbf{c}_j^{KV} = {\mathbf{c}_t^{Q} }^\top ({W_i^{UQ} }^\top W_i^{UK}) \mathbf{c}_j^{KV} \end{align}\]由此发现,$W_i^{UK}$ 被吸收到 $W_i^{UQ}$ 中。原文中所说 $W^{UK}$ 被吸收到 $W^Q$ 可以理解为一种概念表示,而我们这里所推导的则是具体到一个注意力头了。此外,原文之所以用 $W^Q$ ,是因为原文在叙述这里时,还未讲到对 query 也要用低秩压缩,在 query 使用低秩压缩后,实际上就是被吸收到 $W^{UQ}$ 了。
$W_i^{UK} \in \mathbb{R}^{d_h \times d_c}$ 和 $W_i^{UQ} \in \mathbb{R}^{d_h \times d_c’}$ 都是静态参数,他们相乘后得到新的 ${W_i^{UQ’} }^\top \in \mathbb{R}^{d_c’ \times d_c}$,因此,在得到潜在向量 $\mathbf{c}_t^{Q}$ 和 $\mathbf{c}_j^{KV}$ 后,可直接通过 ${\mathbf{c}_t^{Q} }^\top {W_i^{UQ’} }^\top \mathbf{c}_j^{KV} = (W_i^{UQ’} \mathbf{c}_t^{Q})^\top \mathbf{c}_j^{KV}$ 来计算注意力分数,而无需再计算
key,从而减小了计算开销。这里的 $W_i^{UQ’}$ 是模型的训练参数,与位置无关,由此也引出为什么在加入RoPE后,会因耦合而导致 $W^{UK}$ 无法被吸收的问题,在第3节解耦RoPE中进一步说明。
对于公式 $\eqref{eq:2}$ ,可进一步得到:
\[\begin{equation} \begin{aligned} \mathbf{o}_{t,i} &= \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{ {\mathbf{q}_{t,i}^C}^\top \mathbf{k}_{j,i}^C}{\sqrt{d_h} } \right) \mathbf{v}_{j,i}^C \\ &= \sum_{j=1}^{t} \alpha_{j,i} W_i^{UV} \mathbf{c}_j^{KV} \\ &= W_i^{UV} \sum_{j=1}^{t} \alpha_{j,i} \mathbf{c}_j^{KV} \end{aligned} \end{equation}\]其中,$\alpha_{j,i}$ 表示在第 $i$ 个注意力头中,当前位置 $t$ 对位置 $j$ 计算得到的注意力权重。$\mathbf{o}_{t,i}$ 为每个注意力头的输出向量。因此,最终的输出为:
\[\begin{equation} \begin{aligned} \mathbf{u}_t &= W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; \ldots; \mathbf{o}_{t,n_h}] \\ &= W^O [W_1^{UV} \sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV}; W_2^{UV} \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV}; \ldots; W_{n_h}^{UV} \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV}] \\ &= W_1^O W_1^{UV} \sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV} + W_2^O W_2^{UV} \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV} + \ldots + W_{n_h}^O W_{n_h}^{UV} \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV} \\ &= W_1^{O'} \sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV} + W_2^{O'} \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV} + \ldots + W_{n_h}^{O'} \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV} \\ &= W^{O'} [\sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV}; \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV}; \ldots; \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV}] \end{aligned} \end{equation}\]其中:
- $W^O \in \mathbb{R}^{d \times d_h n_h}$
- $W_i^O \in \mathbb{R}^{d \times d_h}$
- $W_i^{UV} \in \mathbb{R}^{d_h \times d_c}$
- $W_i^{O’} = W_i^O W_i^{UV} \in \mathbb{R}^{d \times d_c}$
- $W^{O’} \in \mathbb{R}^{d \times d_c n_h}$
- $\mathbf{u}_t \in \mathbb{R}^{d}$
至此,可以看出 $W^{UV}$ 也被吸收进 $W^O$ ,形成了新的 $W^{O’}$ ,在计算注意力权重后,也无需再计算
value了,直接使用 $W^{O’}$ 进行线性转换即可。
3. 解耦RoPE
RoPE(Rotary Position Embedding) 的核心思想是通过复数域旋转操作将位置信息编码到 query 和 key 向量中。具体来说,对于位置为 $m$ 的向量 $\mathbf{q}_m$ 和位置为 $n$ 的向量 $\mathbf{k}_n$,RoPE通过旋转矩阵 $\mathbf{R}_m$ 和 $\mathbf{R}_n$ 对它们进行变换:
其中,旋转矩阵 $\mathbf{R}_m \in \mathbb{R}^{d_h n_h \times d_h n_h}$ 的形式为分块对角矩阵,每个分块对应二维旋转:
\[\begin{equation} \mathbf{R}_m = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \end{equation}\]通过这种变换,注意力得分的计算会自然引入相对位置信息:
\[\begin{equation} \text{attn_score}_{m,n} = \tilde{\mathbf{q} }_m^\top \tilde{\mathbf{k} }_n = \mathbf{q}_m^\top \mathbf{R}_{m-n} \mathbf{k}_n \end{equation}\]这意味着注意力机制仅依赖相对位置 $m-n$,而非绝对位置。关于RoPE,具体见【手撕系列】手撕Llama3。
RoPE与低秩KV压缩不兼容,具体来说,RoPE对 query 和 key 是位置敏感的,如果直接对 $\mathbf{k}_t^C$ 应用RoPE,那么公式 $\eqref{eq:1}$ 中的 $W^{UK}$ 将会耦合一个位置敏感的RoPE矩阵,从而导致 $W^{UK}$ 无法被 $W^{UQ}$ 吸收。
仍然具体到第 $i$ 个注意力头,当位置为 $m$ 的token对位置为 $n$ 的token执行注意力计算时,首先应用RoPE,有:
\[\begin{align} \mathbf{q}_{m,i}^C &= \mathbf{R}_{m,i} (W_i^{UQ} \mathbf{c}_m^{Q}) \\ \mathbf{k}_{n,i}^C &= \mathbf{R}_{n,i} (W_i^{UK} \mathbf{c}_n^{KV}) \end{align}\]其中,$\mathbf{R}_{t,i} \in \mathbb{R}^{d_h \times d_h}$ 是位置 $t$ 的旋转矩阵对应第 $i$ 个注意力头的子分块对角矩阵。在计算注意力分数时,有:
\[\begin{equation} \begin{aligned} {\mathbf{q}_{m,i}^C}^\top \mathbf{k}_{n,i}^C &= (\mathbf{R}_{m,i} W_i^{UQ} \mathbf{c}_m^{Q})^\top (\mathbf{R}_{n,i} W_i^{UK} \mathbf{c}_n^{KV}) \\ &= {\mathbf{c}_n^{KV} }^\top {W_i^{UQ} }^\top \mathbf{R}_{m,i}^\top \mathbf{R}_{n,i} W_i^{UK} \mathbf{c}_n^{KV} \\ &= {\mathbf{c}_n^{KV} }^\top {W_i^{UQ} }^\top \mathbf{R}_{m-n,i} W_i^{UK} \mathbf{c}_n^{KV} \end{aligned} \end{equation}\]可见,${W_i^{UQ} }^\top$ 和 $W_i^{UK}$ 之间有了 $\mathbf{R}_{m-n,i}$ 用于引入相对位置关系,进而导致 ${W_i^{UQ} }^\top$ 无法吸收 $W_i^{UK}$ ,无法被吸收就意味着我们缓存的 $\mathbf{c}_t^{KV}$ 仍然需要按照原先的方式首先计算出 key,再执行注意力计算,这很影响计算效率。
这就是原文中:In this way, $W^{UK}$ cannot be absorbed into $W^Q$ any more during inference, since a RoPE matrix related to the currently generating token will lie between $W^Q$ and $W^{UK}$ and matrix multiplication does not obey a commutative law. 这里原文仍使用的是不能被 $W^Q$ 吸收,但我们的推导是按照
query也使用低秩压缩而来的。
为了解决这个问题,DeepSeek为MLA应用了解耦RoPE的策略,即使用额外的多头 $\mathbf{q}_{t,i}^R \in \mathbb{R}^{d_h^R}$ 和共享的 $\mathbf{k}_t^R \in \mathbb{R}^{d_h^R}$ 来携带RoPE。其中,$d_h^R$ 表示解耦的 query 和 key 的每个头的维度。应用解耦RoPE策略的MLA可以用下面的公式来表示:
\(\begin{align} [\mathbf{q}_{t,1}^R; \mathbf{q}_{t,2}^R; \ldots; \mathbf{q}_{t,n_h}^R] &= \mathbf{q}_t^R = \text{RoPE}(W^{QR} \mathbf{c}_t^Q), \\ \color{red}{\mathbf{k}_t^R} &= \text{RoPE}(W^{KR} \mathbf{h}_t), \\ \mathbf{q}_{t,i} &= [\mathbf{q}_{t,i}^C; \mathbf{q}_{t,i}^R], \\ \mathbf{k}_{t,i} &= [\mathbf{k}_{t,i}^C; \mathbf{k}_t^R], \\ \mathbf{o}_{t,i} &= \sum_{j=1}^t \text{Softmax}_j\left(\frac{\mathbf{q}_{t,i}^\top \mathbf{k}_{j,i} }{\sqrt{d_h + d_h^R} }\right) \mathbf{v}_{j,i}^C, \\ \mathbf{u}_t &= W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; \ldots; \mathbf{o}_{t,n_h}], \end{align}\) 其中:
- $W^{QR} \in \mathbb{R}^{d_h^R n_h \times d_c’}$ :用于产生解耦
queries - $W^{KR} \in \mathbb{R}^{d_h^R \times d}$ :用于产生解耦
key - $\text{RoPE}(\cdot)$ :应用旋转位置编码
- $[ \cdot ; \cdot ]$ :拼接操作
- $\mathbf{q}_{t,i}, \mathbf{k}_{t,i} \in \mathbb{R}^{d_h+d_h^R}$
简单来说,$[\mathbf{q}_{t,i}^C; \mathbf{q}_{t,i}^R]$ 是各个头拼接各自的解耦 queries ,$[\mathbf{k}_{t,i}^C; \mathbf{k}_t^R]$ 是各个头拼接共享的解耦 key 。在推理阶段,解耦 key $\color{red}{\mathbf{k}_t^R}$ 也需要被缓存,因此,每个token的KV Cahe 一共需要缓存 $(d_c + d_h^R) l$ 个元素。
【思考】(1)为什么解耦
queries是多头的,而解耦key是共享的?(2)为什么解耦queries由 $\mathbf{c}_t^Q$ 计算得到,而解耦key直接由 $\mathbf{h}_t$ 计算得到?
以下分析源于个人理解
对于问题(1),可能的原因有以下几点:
- 为什么解耦
queries是多头的: - 多头解耦
queries中,每个注意力头需要独立捕捉不同局部上下文的位置敏感性。若共享解耦query,所有头的位置编码将完全一致,可能削弱模型对序列中多样位置关系的捕捉能力; - 多头设计允许通过并行计算保持位置敏感性的多样性,而不会显著增加总计算量(因参数仅随头数线性增长)。
- 为什么解耦
key是共享的: - 共享解耦
key能够有效降低显存占用; - 所有头共享同一位置编码基础,避免因不同头的位置偏差导致注意力分数分布混乱。
对于问题(2),可能的原因有以下几点:
- 为什么解耦
queries由 $\mathbf{c}_t^Q$ 计算得到:- 通过低秩压缩 $\mathbf{c}_t^Q$ 减少计算量,具有更关键、更高层的语义表示;
- 为什么解耦
key直接由 $\mathbf{h}_t$ 计算得到:- 原始隐藏状态 $\mathbf{h}_t$ 包含完整的语义和位置信息,直接通过 $W^{KR}$ 映射会牺牲一定压缩率,但可保留RoPE对位置的高保真编码,避免低秩压缩引入的信息损失。
此外,将注意力权重部分进一步细化,得到下面的推导:
\[\begin{equation} \begin{aligned} \mathbf{q}_{t,i}^\top \mathbf{k}_{j,i} &= [\mathbf{q}_{t,i}^C; \mathbf{q}_{t,i}^R]^\top [\mathbf{k}_{j,i}^C; \mathbf{k}_j^R] \\ &= {\mathbf{q}_{t,i}^C}^\top \mathbf{k}_{j,i}^C + {\mathbf{q}_{t,i}^R}^\top \mathbf{k}_j^R \\ &= (W_i^{UQ} \mathbf{c}_t^{Q})^\top W_i^{UK} \mathbf{c}_j^{KV} + (\mathbf{R}_{t,i} W_i^{QR} \mathbf{c}_t^Q)^\top \mathbf{R}_{j,i} W^{KR} \mathbf{h}_j \\ &= \underbrace{ {\mathbf{c}_t^Q}^\top ({W_i^{UQ} }^\top W_i^{UK}) \mathbf{c}_j^{KV} }_{\text{低秩语义交互} } + \underbrace{ {\mathbf{c}_t^Q}^\top ({W_i^{QR} }^\top \mathbf{R}_{t-j,i} W_i^{KR}) \mathbf{h}_j}_{\text{位置敏感交互} } \end{aligned} \end{equation}\]第一项为低秩语义交互 ${\mathbf{c}_t^{Q} }^\top ({W_i^{UQ} }^\top W_i^{UK}) \mathbf{c}_j^{KV}$ ,它计算了潜在向量之间的联系,完全独立于位置编码,通过矩阵吸收,优化了计算效率。
第二项为位置敏感交互 ${\mathbf{c}_t^{Q} }^\top ({W_i^{QR} }^\top \mathbf{R}_{t-j,i} W^{KR}) \mathbf{h}_j$ ,将RoPE限制在解耦 queries 和解耦 key 的交互中,避免与低秩压缩参数耦合。
下面展示了MLA的完整计算过程:
(1)低秩压缩得到 query 的潜在向量:
(2)将潜在向量还原为 query 并转换为多头:
(3)得到解耦 queries 并转换为多头:
(4)将各个头的 queries 和解耦 queries 拼接:
(5)低秩压缩得到 key 和 value 的潜在向量:
(6)将潜在向量还原为 key 并转换为多头:
(7)得到共享的解耦 key :
(8)将各个头的 key 和共享解耦 key 拼接:
(9)将潜在向量还原为 value 并转换为多头:
(10)执行注意力计算过程:
\(\begin{align} \mathbf{o}_{t,i} &= \sum_{j=1}^t \text{Softmax}_j\left(\frac{\mathbf{q}_{t,i}^T \mathbf{k}_{j,i} }{\sqrt{d_h + d_h^R} }\right) \mathbf{v}_{j,i}^C \\ \mathbf{u}_t &= W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; \ldots; \mathbf{o}_{t,n_h}] \end{align}\) 其中,在DeepSeek-V2中,$d_c$ 设置为 $4d_h$ ,$d_h^R$ 设置为 $\frac{d_h}{2}$ 。
再次对比原图,进一步理解这个过程:
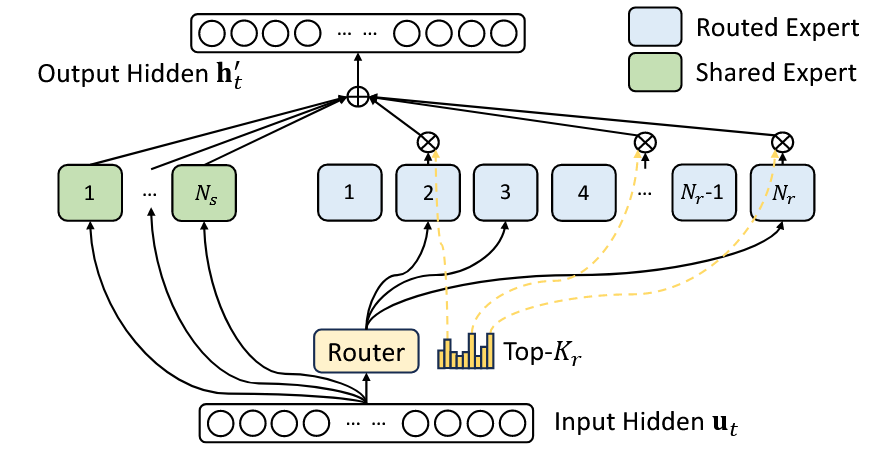
(二)混合专家模型架构DeepSeekMoE
1. DeepSeekMoE基本结构
混合专家模型(Mixture of Experts,MoE)是一种通过组合多个子模型来提升模型性能的架构,让不同的专家处理不同的问题,通过动态路由(门控网络)决定如何组合这些专家的输出。
DeepSeekMoE有两个关键思想:
- 使用更细粒度的专家,以实现更高的专业化和更准确的知识获取
- 分离出一些专家作为共享专家,以减少路由专家之间的知识冗余
令 $\mathbf{u}_t$ 为第 $t$ 个token的FFN输入,通过下面的公式来计算FFN的输出 $\mathbf{h}_t’$ :
\[\begin{align} \mathbf{h}_t' &= \mathbf{u}_t + \sum_{i=1}^{N_s} \text{FFN}_i^{(s)}(\mathbf{u}_t) + \sum_{i=1}^{N_r} g_{i,t} \text{FFN}_i^{(r)}(\mathbf{u}_t) \\ g_{i,t} &= \frac{g_{i,t}'}{\sum_{j=1}^{N_r} g_{j,t}'} \\ g_{i,t}' &= \begin{cases} s_{i,t}, & s_{i,t} \in \text{Topk}(\{s_{j,t} | 1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise} \end{cases} \\ s_{i,t} &= \text{Sigmoid}(\mathbf{u}_t^T \mathbf{e}_i) \\ \end{align}\]其中:
- $N_s$ 和 $N_r$ :共享专家/路由专家的数量
- $\text{FFN}_i^{(s)}(\cdot)$ 和 $\text{FFN}_i^{(r)}(\cdot)$ :第 $i$ 个共享专家/路由专家
- $K_r$ :激活的路由专家数量
- $g_{i,t}$ :第 $i$ 个专家的门控值,决定了第 $i$ 个路由专家在最终FFN输出中所占的权重【注意:这是在选出的topk得分内进行归一化而得到的】
- $s_{i,t}$ :token与专家之间的亲和度,即某个token被分配给某个专家的概率或权重
- $\mathbf{e}_i$ :第 $i$ 个路由专家的质心向量,用于衡量token和专家的匹配程度
- $\text{Topk}(\cdot, K)$ :在第 $t$ 个token和所有专家计算的亲和度分数中,选择 $K$ 个最高的
与DeepSeek-V2不同的是,DeepSeek-V3使用Sigmoid函数来计算亲和度分数,然后在所有选择出的亲和度分数中使用了归一化,从而产生门控值。
具体过程如下图所示:
2. 无辅助损失的负载均衡策略
自动学习的路由策略可能会遇到负载不平衡的问题,表现为:
- 模型总是只选择少数专家,从而阻止其他专家进行充分的训练
- 如果专家分布在多个设备上,负载不平衡会加剧计算瓶颈
常规的方法是借助辅助损失(auxiliary loss)来避免不均衡的负载,例如在最初的DeepSeekMoE架构中,就设计了专家级的均衡损失和设备级的均衡损失,在DeepSeek-V2中还使用了通信均衡损失。然而过大的辅助损失会影响模型性能。在DeepSeek-V3中,设计了无辅助损失的负载均衡策略(auxiliary-loss-free strategy for load balancing)来确保负载均衡。这一策略在论文中Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts有详细介绍,其过程如下图所示:
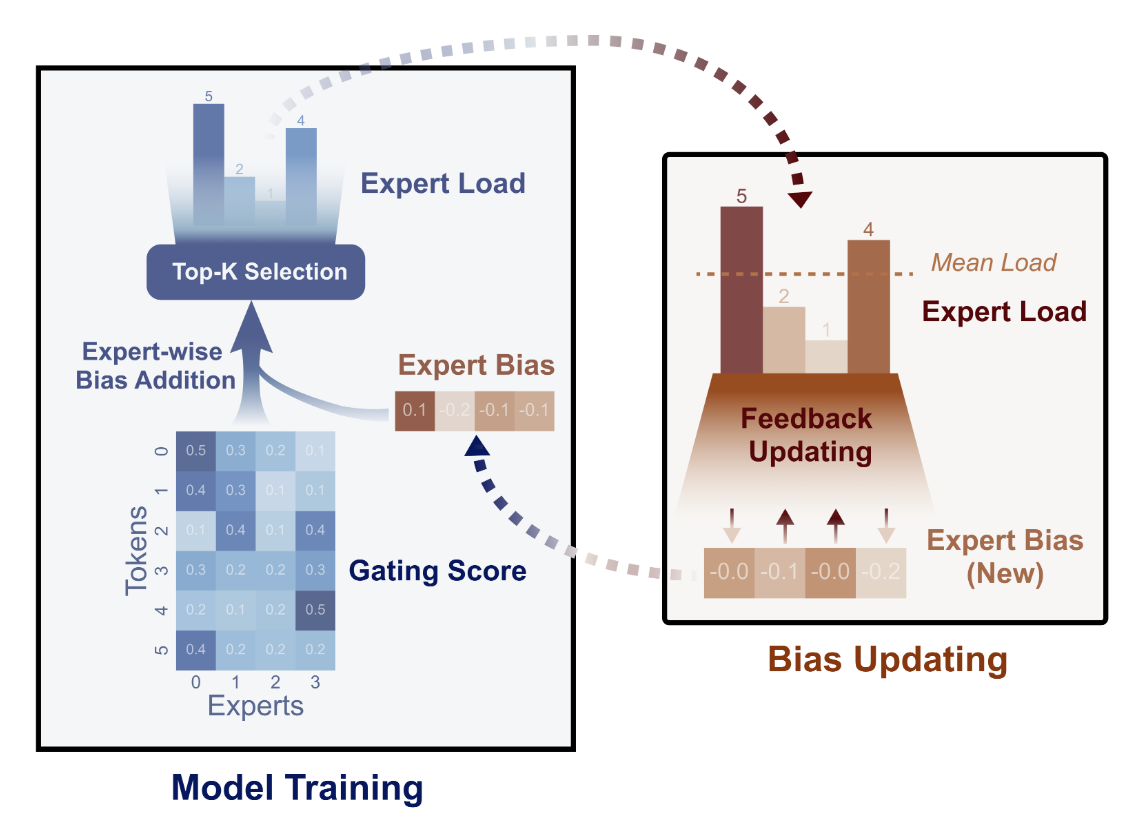
具体来说,为每个专家引入一个偏置项 $b_i$ ,并将其与对应的亲和度分数 $s_{i,t}$ 相加,从而选出top-K路由:
\[\begin{equation} g_{i,t}' = \begin{cases} s_{i,t}, & s_{i,t} + b_i \in \text{Topk}(\{s_{j,t} + b_j | 1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise} \end{cases} \end{equation}\]注意,偏置项 $b_i$ 仅用于路由,与FFN输出相乘的门控值仍然来源于原始的亲和度分数 $s_{i,t}$ 。在训练过程中,持续监控每个step 整个batch 的专家负载,在每个step最后,如果对应的专家过载,则对 $b_i$ 减少 $\gamma$ ,如果对应的专家负载不足,则对 $b_i$ 增加 $\gamma$ ,其中 $\gamma$ 是一个称为偏置更新速度的超参数。通过动态调整,DeepSeek-V3在训练过程中保持均衡的专家负载,比仅通过纯辅助损失鼓励负载均衡的模型性能更好。
其算法流程如下图所示,图中的Eq.(3)即上式:

3. 序列级辅助损失
无辅助损失的负载均衡策略主要关注全局的专家负载均衡,确保在整个batch级别上,专家的负载相对均衡。但在序列级别(Sequence-Wise)上,仍然可能出现负载不均衡的情况。例如,一个输入序列中的多个token可能会集中分配给某些专家,导致这些专家在单个序列内负载过高。因此,除了使用无辅助损失的负载均衡策略,DeepSeek-V3还使用了补充的序列级辅助损失(Complementary Sequence-Wise Auxiliary Loss)如下:
\[\begin{align} \mathcal{L}_{\text{Bal} } &= \alpha \sum_{i=1}^{N_r} f_i P_i \\ f_i = \frac{N_r}{K_r T} \sum_{t=1}^{T} &\mathbb{I}(s_{i,t} \in \text{Topk}(\{s_{j,t} \mid 1 \leq j \leq N_r\}, K_r)) \\ s_{i,t}' &= \frac{s_{i,t} }{\sum_{j=1}^{N_r} s_{j,t} } \\ P_i &= \frac{1}{T} \sum_{t=1}^{T} s_{i,t}' \end{align}\]其中:
- $\alpha$ :平衡因子,会被设置为一个非常小的值
- $\mathbb{I}(\cdot)$ :指标函数,若符合括号中的情况,则记为1,不符合则记为0
- $T$ :序列中的token数
- $s_{i,t}’$ :第 $t$ 个token在第 $i$ 个专家上的归一化亲和度得分【注意:与gate不同,这是对所有的得分进行归一化】
- $P_i$ :第 $i$ 个专家在每个token上的归一化亲和度得分均值
- $\mathbb{I}(s_{i,t} \in \text{Topk}({s_{j,t} \mid 1 \leq j \leq N_r}, K_r))$ :对于第 $i$ 个专家,若被第 $t$ 个token激活(是top-k之一),则记为1,否则记为0
- $\frac{1}{T} \sum_{t=1}^{T} \mathbb{I}(s_{i,t} \in \text{Topk}({s_{j,t} \mid 1 \leq j \leq N_r}, K_r))$ :第 $i$ 个专家在每个token上的平均激活次数
- $\frac{N_r}{K_r}$ :缩放系数
- $f_iP_i$ :第 $i$ 个专家在每个token上的平均激活次数乘以平均得分
直观理解上, $P_i$ 可由调整模型权重来改变,而 $f_i$ 是由 $P_i$ 导致的客观结果,专家 $i$ 的得分大,自然被激活的次数就多。因此,若在一个序列中,各个token最终激活专家 $i$ 的频率 $f_i$ 很大,那么该专家的得分 $P_i$ 就应该减小,反之亦然,从而鼓励每个序列上的专家负载变得均衡。
此外,为防止激活的专家分布在过多的节点上,增加通信成本,还使用了节点限制路由(Node-Limited Routing),即确保每个token最多只会被发送到M个节点。首先计算所有节点 $\frac{K_r}{M}$ 个最高亲和度分数之和,然后根据这些亲和度分数和,选则最大的M个节点。接下来,在这M个节点上选择top-k个专家,因此便能确定出最终 $K_r$ 个激活专家。
(三)多token预测
多token预测(Multi-Token Prediction,MTP)即同时预测多个未来token,能够显著增强模型的整体性能。与传统的使用独立的输出头预测多个token不同,DeepSeek-V3的MTP基于主模型(Main Model)和多个MTP模块(MTP Module)的组合,主模型负责基础的下一个token预测,而MTP模块则用于预测多个未来token。这样能够按顺序预测额外的token,并保留完整的因果链(causal chain)。
因果链指的是模型在预测多个未来token时,保持预测之间的因果关系。具体来说,模型在预测第n个token时,必须依赖于前n−1个token的预测结果,确保每个预测都基于正确的上下文信息,而不是独立进行预测。如下图所示:
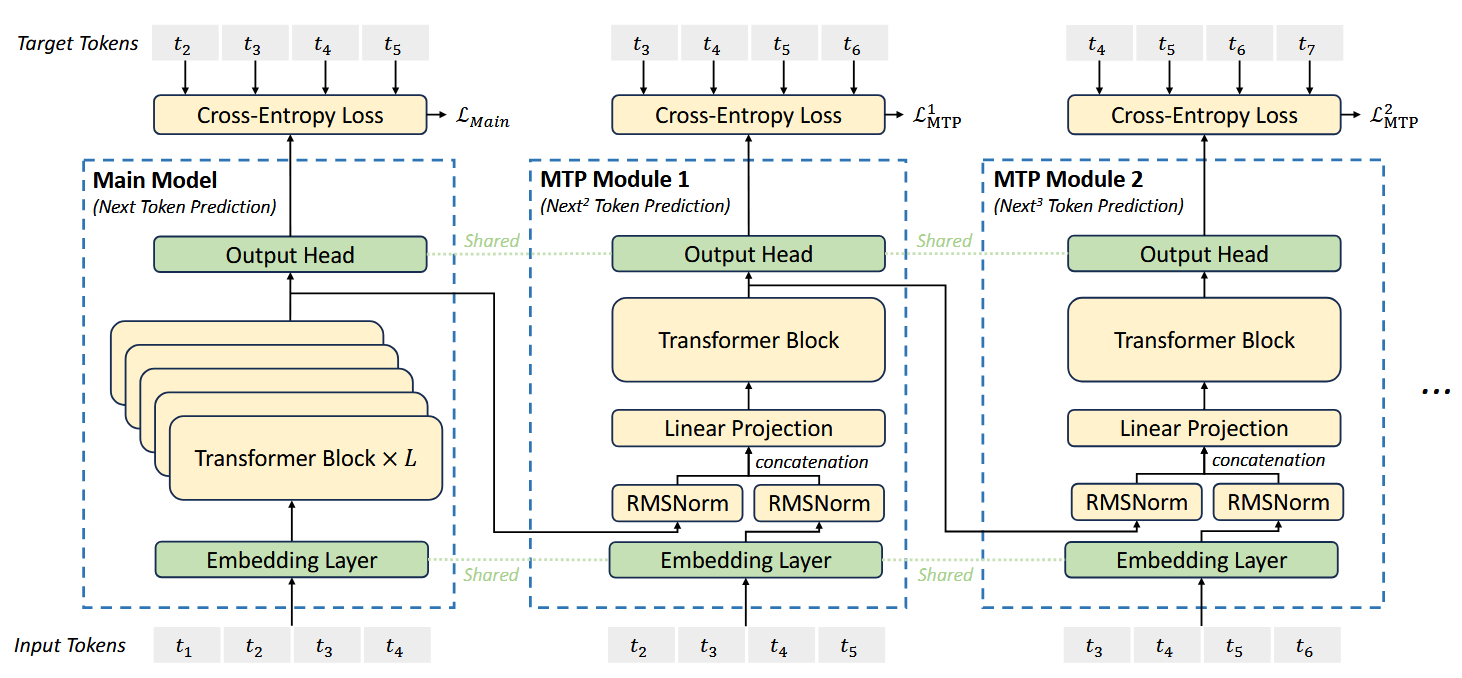
1. MTP模块
DeepSeek-V3的MTP实现通过使用 $D$ 个序列模块来预测 $D$ 个额外tokens。这里需要提到一个概念:预测深度(Prediction Depth),预测深度为 $k$ ,表示模型在生成当前token时,能够预测后续第 $k$ 个token。每个预测深度对应了一个MTP模块,第 $k$ 个MTP模块包括一个共享Embedding层 $\text{Emb}(\cdot)$,一个共享输出头 $\text{OutHead}(\cdot)$,一个Transformer模块 $\text{TRM}_k(\cdot)$ 和一个投影矩阵 $M_k \in \mathbb{R}^{d \times 2d}$ 。
对于输入的第 $i$ 个token $t_i$ ,在预测深度为 $k$ 时,首先通过投影矩阵融合第 $k-1$ 个预测深度的输出表征 $\mathbf{h}_i^{k-1} \in \mathbb{R}^d$ 和第 $i+k$ 个token的Embedding $\text{Emb}(t_{i+k}) \in \mathbb{R}^d$ :
\[\begin{equation} \mathbf{h}_i^{'k} = M_k \left[ \text{RMSNorm}(\mathbf{h}_i^{k-1}); \text{RMSNorm}(\text{Emb}(t_{i+k})) \right] \end{equation}\]其中,$[\cdot ; \cdot]$ 表示拼接操作。特别的,当 $k=1$ 时,$\mathbf{h}_i^{k-1}$ 就是主模型的表征。另外,注意每个MTP模块的Embedding层和输出头,都是与主模型共享的。融合后的 $\mathbf{h}_i^{‘k}$ 作为输入,输入到第 $k$ 个深度的Transformer模块中,产生输出表征 $\mathbf{h}_i^{k}$ :
\[\begin{equation} \mathbf{h}_{1:T-k}^k = \text{TRM}_k(\mathbf{h}_{1:T-k}^{'k}) \end{equation}\]其中,$T$ 表示输入的序列长度【构造数据时,根据使用的预测深度$k$来确定输入序列和输出序列,这里输入序列指$t_1$~$t_6$,而输出是$t_2$~$t_7$,因此输入序列长度$T$指的是6,如果预测深度$k=2$,那么主模型的输入前$6-2=4$个token作为输入,来预测下$k+1$个token,即$t_1$~$t_4$预测$t_4$~$t_7$】,下标 $i:j$ 表示切片操作,包括左右边界。这里相当于对输入序列从1到T-k的token,都进行了后面第 $k$ 个token的预测。
最后,将 $\mathbf{h}_i^k$ 作为共享输出头的输入,共享输出头将会计算第 $k$ 个token预测词的概率分布 $p_{i+k+1}^k \in \mathbb{R}^V$ ,其中,$V$ 是词典的大小:
\[\begin{equation} p_{i+k+1}^k = \text{OutHead}(\mathbf{h}_i^k) \label{eq:3} \end{equation}\]其中,输出头将表征线性映射为logits,然后使用softmax函数来计算预测概率。
2. MTP训练目标
对每个预测深度,计算交叉熵损失:
\[\begin{equation} \mathcal{L}_{\text{MTP} }^k = \text{CrossEntropy}(P_{2+k:T+1}^k, t_{2+k:T+1}) = -\frac{1}{T} \sum_{i=2+k}^{T+1} \log P_i^k[t_i] \end{equation}\]其中:
- $T$ :输入序列长度
- $t_i$ :第 $i$ 个位置的ground truth token
- $P_i^k[t_i]$ :由第 $k$ 个MTP模块给出的对应 $t_i$ 的预测概率
注意,这里的下标 $i$ 与上一小节的下标 $i$ 含义不同。 (1)例如,公式 $\eqref{eq:3}$ 中的下标 $i$ 是从输入的角度,表示当前token的位置,$i+k+1$ 表示预测深度为 $k$ 时预测输出的token的位置。如果 $k=0$ ,则表示仅做下一个字符预测,预测输出第 $i+1$ 个位置的token;如果 $k=1$ ,则表示做下两个字符预测,在第 $k=1$ 个MTP模块中,会预测输出第 $i+2$ 个位置的token。 (2)而本小节的 $i$ 是从输出的角度,表示当前预测输出的token的位置。当上一小节中的 $i$ 取 $1$ ,即输入序列的第 $1$ 个token时,输出对应第 $i+k+1=2+k$ 个token,也就成了本小节的 $i$ 从 $2+k$ 起算;当上一小节中的 $i$ 取 $T-k$ 时,输出对应第 $i+k+1=T+1$ ,也就成了本小节的 $i$ 到 $T+1$ 终止。
最后,在所有MTP模块上计算平均,并乘一个系数 $\lambda$ ,得到最终的MTP损失 $\mathcal{L}_{\text{MTP} }$ :
\[\begin{equation} \mathcal{L}_{\text{MTP} } = \frac{\lambda}{D} \sum_{k=1}^{D} \mathcal{L}_{\text{MTP} }^k \end{equation}\]3. 推理时的MTP
MTP模块的目标主要是为了提升主模型的性能,在推理阶段可以直接丢弃MTP模块,主模型能够独立正常的运行。
- 在传统的单token预测中,模型在每个训练步骤中只预测下一个token,并基于预测结果更新模型参数。这种方式在每个训练步骤中只提供一个训练信号(即下一个token的预测)。
- 而MTP(多token预测)策略让模型在每个训练步骤中同时预测多个token,这意味着每个训练步骤中,模型会收到多个训练信号(即多个token的预测)。这种多token预测增加了模型在每个训练步骤中接收到的信息量,使模型能够更快地学习语言结构和上下文依赖关系。
此外,MTP模块还可以被重新用于投机解码(speculative decoding),以进一步减少生成延迟。投机解码是一种加速生成过程的技术,通过并行预测多个token并验证其准确性,从而减少逐步生成的次数。MTP模块在投机解码中扮演了草稿模型(Draft Model)的角色,用于快速生成多个候选token。目标模型(Target Model,也就是主模型)对这些候选token进行验证,通过的token被接受,未通过的token被修正。
关于speculative decoding,可参考:
二、基础设施(仅了解)
此部分涉及大规模训练的工程实践和优化,仅做知识性的了解,后面有机会再深入学习。
(一)计算集群
DeepSeek-V3是在一个配备了2048个NVIDIA H800 GPU的集群上训练的。H800集群中的每个节点(Node)包含8个通过NVLink和NVSwitch在节点内部互联的GPU。而在不同的节点之间,则利用InfiniBand (IB) 互连来促进通信。
(二)训练框架
DeepSeek-V3使用工程师从头打造的高效的轻量训练框架HAI-LLM进行训练,使用了16路管道并行(Pipeline Parallelism,PP)、64路专家并行(Expert Parallelism,EP)和ZeRO-1 数据并行(Data Parallelism,DP)。
- Pipeline Parallelism,PP
- 当模型太大,无法在单个 GPU 的内存中容纳时,可以将模型的不同层分配到多个 GPU 上,每个 GPU 只负责模型的一部分。
- Pipeline Parallelism 将模型按层分割,每个 GPU 负责一部分层的计算。数据依次通过这些 GPU,就像在管道中流动一样。
- 由于 GPU 之间需要等待前一个 GPU 完成计算才能开始下一个 GPU 的计算,这会导致“管道气泡”,降低效率。
- Expert Parallelism,EP
- Expert Parallelism 将不同的专家分配到不同的 GPU 上,每个 GPU 只负责一部分专家的计算。
- 在 DeepSeek-V3 中,使用了 64-way Expert Parallelism,将专家分配到 64 个 GPU 上,跨越了 8 个节点。
- Data Parallelism,DP
- 在数据并行中,每个 GPU 都有一份完整的模型副本,处理不同的数据批次。然而,随着模型规模的增大,存储模型参数和优化器状态的内存开销也会变得非常大。
- ZeRO (Zero Redundancy Optimizer) 是一种优化数据并行的技术,它将模型参数、梯度和优化器状态分布到多个 GPU 上,从而减少每个 GPU 的内存占用。
- 在 ZeRO-1 中,只有优化器状态被分布到多个 GPU 上,而模型参数和梯度仍然在每个 GPU 上保留完整副本。
为了实现高效训练,DeepSeek-V3实施了细致的工程优化。首先,设计了DualPipe算法以实现高效的管道并行,与现有的PP方法相比,管道起泡更少。其次,开发了高效的跨节点多对多通信内核,以充分利用IB和NVLink带宽。最后,精心优化了训练内存占用。
(三)FP8训练
DeepSeek-V3通过FP8混合精度训练,在保证模型精度的同时,大幅降低显存占用并提升训练速度。对于模型中对精度较为敏感的组件(例如Embedding、Output Head、MoE Gating、Normalization、Attention 等),DeepSeek-V3仍然采用BF16或FP32进行计算,以保证模型的性能。
DeepSeek-V3没有采用传统的per-tensor量化,而是采用了更细粒度的量化策略:对激活值采用1x128 tile-wise量化,对权重采用128x128 block-wise量化。这种策略可以更好地适应数据的分布,减少量化误差。
为了减少FP8计算过程中的精度损失,DeepSeek-V3将MMA(Matrix Multiply-Accumulate)操作的中间结果累加到FP32寄存器中。
为了进一步降低显存占用和通信开销,DeepSeek-V3将激活值和优化器状态以FP8或BF16格式进行存储,并在通信过程中也使用这些低精度格式。
三、预训练
(一)数据构建
与DeepSeek-V2相比,DeepSeek-V3增加了数学和编程样本的语料比例,将语言覆盖范围扩展到中英文以外,同时优化了数据处理管道,在保证语料多样性的同时,最大限度的减少冗余。通过文档打包的方法确保数据完整性,但在训练时没有使用跨样本的注意力掩码。
Fill-in-Middle(FIM)策略的核心思想是让模型学会填补中间缺失的部分,即在给定前缀(Prefix)和后缀(Suffix)的情况下,生成中间缺失的内容(Middle)。这种训练方式模拟了实际编程中常见的场景,例如在编写代码时,程序员可能先定义函数的前后部分,再补充中间的逻辑。在DeepSeekCoder-V2的训练中,发现在使用FIM策略时,不会损害模型预测下一个token的能力,同时还能使模型根据上下文提示,准确的预测出中间的文本。在DeepSeek-V3中也引入了这种策略,具体来说,使用Prefix-Suffix-Middle(PSM)框架来实现这一策略,即前缀-后缀-中间框架来构造数据如下:
\[<\text{|fim_begin|}> f_{\text{pre} } <\text{|fim_hole|}> f_{\text{suf} } <\text{|fim_end|}> f_{\text{middle} } <\text{|eos_token|}>\]其中:
- $<\text{|fim_begin|}>$ :标记FIM任务的开始
- $<\text{|fim_hole|}>$ :前缀和后缀之间的分隔符,表示确实部分
- $<\text{|fim_end|}>$ :标记FIM任务的结束
- $<\text{|eos_token|}>$ :标记序列的结束
- $f_{\text{pre} }$ :前缀部分
- $f_{\text{suf} }$ :后缀部分
- $f_{\text{middle} }$ :中间缺失的部分,即模型需要生成的内容
这一结构被应用于文档级别,作为预打包的一个部分,FIM结构的应用率为10%,即有10%的数据使用这一策略进行训练。
DeepSeek-V3采用字节级BPE,具有128k的扩展词汇。
(二)超参数
1. 模型超参数
- Transformer Layers:61
- Hidden Dimension:7168
- MLA :
- attention heads $n_h$ :128
- per-head dimension $d_h$ :128
- KV compression dimension $d_c$ :512
- query compression dimension $d_c’$ :1536
- per-head dimension of decoupled queries and key $d_h^R$ :64
- Each MoE Layer :
- 1 shared expert
- 256 routed experts
- intermediate hidden dimension of each expert :2048
- 8 routed experts will be activated for each token
- each token will be ensured to be sent to at most 4 nodes
- MTP depth $D$ :1
此外,所有可学习参数以0.006的标准差随机初始化;在压缩潜在向量后,使用额外的RMSNorm;将除前三层外的所有层的FFN换为MoE;总共训练14.8T tokens。
2. 训练超参数
- AdamW :
- $\beta_1$ :0.9
- $\beta_2$ :0.95
- weight_decay :0.1
- max_seq_len in pre-training :4k
- Learning Rate Scheduling :
- linearly increase from $0$ to $2.2 \times 10^{−4}$ during the first 2K steps
- keep a constant learning rate of $2.2 \times 10^{−4}$ until the model consumes 10T training tokens
- gradually decay the learning rate to $2.2 \times 10^{−5}$ in 4.3T tokens, following a cosine decay curve
- the final 500B tokens, keep a constant learning rate of $2.2 \times 10^{−5}$ in the first 333B tokens, and switch to another constant learning rate of $7.3 \times 10^{−6}$ in the remaining 167B tokens
- Gradient Clipping Norm :1.0
- Batch Size Scheduling Strategy :
- gradually increased from 3072 to 15360 in the training of the first 469B tokens
- keeps 15360 in the remaining training
- leverage pipeline parallelism to deploy different layers of a model on different GPUs
- for each layer, the routed experts will be uniformly deployed on 64 GPUs belonging to 8 nodes
- auxiliary-loss-free load balancing :
- set the bias update speed $\gamma$ to 0.001 for the first 14.3T tokens
- set $\gamma$ to 0.0 for the remaining 500B tokens
- balance loss $\alpha$ :0.0001
- MTP loss weight $\lambda$ is set to 0.3 for the first 10T tokens, and to 0.1 for the remaining 4.8T tokens
3. 长上下文扩展
在预训练之后,使用YaRN进行上下文扩展,并执行两个额外的训练阶段,每个阶段包括1000个step,逐步将上下文窗口从4k扩展到32k再到128k。
YaRN仅用于解耦共享 key $\mathbf{k}_t^R$ ,超参数在两个阶段保持相同,参数含义及原理具体参考YaRN论文:
- $s$ :40
- $\alpha$ :1
- $\beta$ :32
- 缩放因子: $\sqrt{t} = 0.1 \ln s + 1$
在第一阶段,序列长度设置为32k,批量大小为1920。在第二阶段,序列长度增加到128K,批量大小减小到480。两个阶段的学习率都设置为 $7.3 \times 10^{-6}$,与预训练阶段的最终学习率相匹配。
四、后训练
(一)监督微调SFT
监督微调精心挑选了150万个实例的指令调优数据集,横跨多个领域。每个领域都采用了量身定制的数据创建方法。
1. 推理数据
包括数学、代码、逻辑等数据,这些数据由DeepSeek-R1生成。虽然DeepSeek-R1生成的数据准确性很强,但在表达上存在过度推理、格式不规范和内容过长等问题。我们的目标是平衡R1生成的高准确度推理数据与格式规范且简洁清晰的常规推理数据之间的关系。
为了实现这一点,首先通过SFT和RL,为特定领域(如代码、数学、一般推理)训练了一个专家模型,这个专家模型作为最终模型的数据生成器。训练过程会为每个实例生成两种不同的SFT样本:第一类是将问题与原始响应结合起来,形成 <problem, original response> ;第二类是包含系统提示词、问题及R1响应的组合,形成 <system prompt, problem, R1 response> 。
系统提示词经过精心设计,用于指导模型生成富含反思与验证机制的输出。在RL阶段,使用高温度采样,使输出能够融合R1 response和原始response的模式,即使没有明确的系统提示词。经过数百个步骤的强化学习训练,这个中间RL模型学会了整合R1模式,从而提升整体性能。
RL训练完成后,通过拒绝采样(rejection sampling)从专家模型中筛选高质量SFT数据,用于最终模型训练。这样这样既保留R1模型的优势(如严谨性),同时生成更简洁、高效的响应。
2. 非推理数据
对于非推理数据,如创造性写作、角色扮演和简单问答,使用DeepSeek-V2.5生成响应,并人工验证数据的准确性和正确性。
3. 微调设置
使用SFT数据集,在DeepSeek-V3-Base进行了两个epoch的微调,采用余弦衰减学习率调度,从 $5 \times 10^{-6}$ 开始,逐渐衰减到 $1 \times 10^{-6}$ 。在训练时,每个序列由多个样本打包,使用样本掩码策略保证样本之间互相不会看到。
(二)强化学习RL
1. 奖励模型
使用了基于规则的奖励模型(Reward Model,RM)和基于模型的奖励模型。
- 基于规则的奖励模型(Rule-Based RM):对于可以使用特定规则进行验证的问题,使用基于规则的奖励系统来确定反馈。比如某些数学问题具有确定性的结果,我们要求模型以指定的格式提供最终答案,从而允许我们能够基于规则来验证正确性。类似的,对于LeetCode问题,我们可以利用编译器根据测试用例生成反馈。通过尽可能利用基于规则的验证,确保了更高水平的可靠性,因为这种方法不易受到操纵或利用。
- 基于模型的奖励模型(Model-Based RM):有些问题的ground-truth答案具有自由格式,我们依靠奖励模型来决定输出的响应是否匹配预期的ground-truth答案。相反,对于没有确定答案的开放性问题,例如涉及创作写作的问题,奖励模型的任务是根据输入的问题和相应的回答提供反馈。奖励模型是从DeepSeek-V3 SFT检查点进行训练的。为了提高其可靠性,我们构建了偏好数据,不仅提供了最终的奖励,还包含了获得奖励的推理过程。这种方法有助于在特定任务中减轻奖励作弊的风险。
2. 群体相对策略优化
与DeepSeek-V2相同,采用了群组相对策略优化(Group Relative Policy Optimization,GRPO),该方法在DeepSeekMath提出。GRPO放弃了通常与policy model大小相同的critic model,并且从组分数来估计baseline。
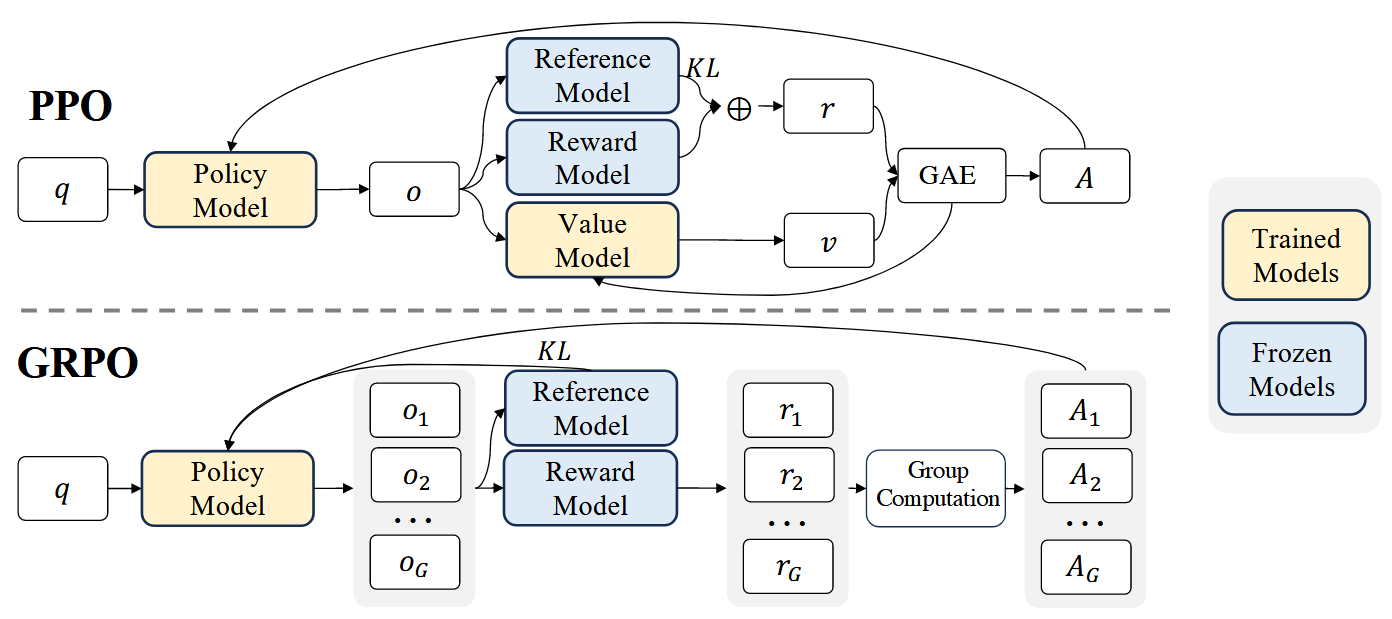
详细的介绍参见【笔记】从策略梯度到PPO再到GRPO。
论文最后的评估与讨论部分不再过多介绍。
五、DeepSeek开源周内容
- FlashMLA:专注于GPU超频加速的底层优化工具,提升硬件计算效率,通过优化GPU的内存调度和并行计算能力,让大模型在普通GPU(如英伟达H800)上的运行速度显著提升,同时降低硬件资源浪费。
- DeepEP:这是首个用于MoE(混合专家)模型训练和推理的开源EP(专家并行)通信库,提供高吞吐量和低延迟的GPU内核。
- DeepGEMM:这是一个支持密集布局和MoE布局的通用矩阵乘法库,专为V3/R1模型的训练和推理提供强大支持,并支持即时编译。
- Optimized Parallelism Strategies:包括DualPipe,一种双向流水线并行算法,用于V3/R1训练中的计算-通信重叠;EPLB,用于V3/R1的专家并行负载均衡器;profile-data,训练和推理框架的分析数据。
- 3FS(Fire-Flyer File System):高速文件系统及配套工具smallpond。