【论文解读】YaRN
Categories: Paper
目录
概览
YaRN(Yet another RoPE extensioN method)是一种高效扩展RoPE(旋转位置嵌入)上下文长度的方法,旨在解决Transformer模型在处理超出训练时最大上下文长度的序列时性能下降的问题。
一、背景和相关工作
(一)旋转位置编码(Rotary Position Embedding,RoPE)
关于RoPE细节及推导,见【手撕系列】手撕Llama3。
YaRN的工作基础是RoPE,假定隐藏层神经元的集合为 $D$ ( $|D|$ 即嵌入维度),给定一系列向量 $\mathbf{x}_1, \cdots, \mathbf{x}_L \in \mathbb{R}^{|D|}$ ,在执行注意力计算时,首先将这些向量转换为查询向量和键向量:
\[\begin{equation} \mathbf{q}_m = f_q(\mathbf{x}_m, m) \in \mathbb{R}^{|D|}, \quad \mathbf{k}_n = f_k(\mathbf{x}_n, n) \in \mathbb{R}^{|D|} \end{equation}\]接下来,计算注意力权重:
\[\begin{equation} \text{softmax}\left( \frac{\mathbf{q}_m^T \mathbf{k}_n}{\sqrt{|D|} } \right) \end{equation}\]其中,$\mathbf{q}_m$ 和 $\mathbf{k}_n$ 考虑为加入了位置编码的列向量,分别代表位置 $m$ 和 $n$ 处的查询向量和键向量。为了将 $\mathbf{x}_m, \mathbf{x}_n$ 变换为 $\mathbf{q}_m$ 和 $\mathbf{k}_n$ ,首先进行线性变换:
\[\begin{equation} \mathbf{W}_q, \mathbf{W}_k : \mathbb{R}^{|D|} \to \mathbb{R}^{|D|} \end{equation}\]在RoPE中,我们假定 $|D|$ 是偶数,可将嵌入空间转换为复数空间:
\[\begin{equation} \mathbb{R}^{|D|} \cong \mathbb{C}^{|D|/2} \end{equation}\]因此,内积 $\mathbf{q}^T \mathbf{k}$ 就可变为标准Hermitian内积的实部:$\operatorname{Re}(\mathbf{q}^* \mathbf{k})$ 。更具体地说,这一同构映射通过交错实部与虚部的方式进行组合(即两两维度组合为一个复数向量),例如:
\[\begin{align} \left((\mathbf{x}_m)_1, \cdots, (\mathbf{x}_m)_{|D|}\right) \mapsto \left((\mathbf{x}_m)_1 + i(\mathbf{x}_m)_2, \cdots, ((\mathbf{x}_m)_{|D|-1} + i(\mathbf{x}_m)_{|D|})\right) \\ \left((\mathbf{q}_m)_1, \cdots, (\mathbf{q}_m)_{|D|}\right) \mapsto \left((\mathbf{q}_m)_1 + i(\mathbf{q}_m)_2, \cdots, ((\mathbf{q}_m)_{|D|-1} + i(\mathbf{q}_m)_{|D|})\right) \end{align}\]最终,在复数域上,函数 $f_q, f_k$ 可由下式得到:
\[\begin{equation} f_q(\mathbf{x}_m, m) = e^{im\theta} \mathbf{W}_q \mathbf{x}_m, \quad f_k(\mathbf{x}_n, n) = e^{in\theta} \mathbf{W}_k \mathbf{x}_n \end{equation}\]其中,$\theta = \operatorname{diag}(\theta_1, \cdots, \theta_{|D|/2})$ 是 $\theta_d = b^{-2d/|D|}$ 的对角矩阵,其中 $b = 10000$ 。这样,复数空间中,每个复数元素与一个 $\theta_d$ 相关联。在位置关系上,查询向量与键向量的内积仅与他们的相对位置关系 $m-n$ 有关:
\[\begin{equation} \begin{aligned} &\langle f_q(\mathbf{x}_m, m), f_k(\mathbf{x}_n, n) \rangle_\mathbb{R} \\ &= \operatorname{Re}(\langle f_q(\mathbf{x}_m, m), f_k(\mathbf{x}_n, n) \rangle_\mathbb{C}) \\ &= \operatorname{Re}(\mathbf{x}_m^* \mathbf{W}_q^* \mathbf{W}_k \mathbf{x}_n e^{i\theta(m-n)}) \\ &= g(\mathbf{x}_m, \mathbf{x}_n, m - n) \end{aligned} \end{equation}\]在实数域下,RoPE可以用下式表达:
\[\begin{equation} \begin{aligned} & f_{\mathbf{W} }(\mathbf{x}_m, m, \theta_d) = \mathbf{R}_m \mathbf{W} \mathbf{x}_m\\ &= \begin{pmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{|D|/2} & -\sin m\theta_{|D|/2} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{|D|/2} & \cos m\theta_{|D|/2} \end{pmatrix} \mathbf{W} \mathbf{x}_m \end{aligned} \end{equation}\]这一过程可以总结为以下几步:
- 将 $x_m, x_n$ 线性变换为
query'和key'(即原始transformer中的变换)- 将得到的
query'和key'转换至复数空间- 在复数域,分别对
query'和key'乘 $e^{im\theta}, e^{in\theta}$ ,得到最终的query和key(相当于将原始的每个复数向量旋转一定角度)
(二)位置插值(Position Interpolation,PI)
由于语言模型通常使用固定的上下文长度进行预训练,因此很自然的要问,如何在较少的数据量上通过微调来扩展上下文长度。
通过在预训练的上下文长度内,给位置索引进行插值,并进行一定的微调训练,能达到较好的效果。具体来说,给定一个使用了RoPE的预训练语言模型,PI将RoPE修改为:
\[\begin{equation} f_{\mathbf{W} }'(\mathbf{x}_m, m, \theta_d) = f_{\mathbf{W} }\left(\mathbf{x}_m, \frac{mL}{L'}, \theta_d \right) \label{eq:1} \end{equation}\]其中, $L’ > L$ 是超出预训练限制的上下文窗口长度。在原始预训练模型的基础上,结合改进的RoPE公式进行一定的微调,有效的扩展了上下文长度。
(三)附加说明
扩展的上下文长度和原始上下文长度之比定义为 $s$ ,即比例因子:
\[\begin{equation} s = \frac{L'}{L} \end{equation}\]进一步将公式 $\eqref{eq:1}$ 写为更一般的形式:
\[\begin{equation} f_{\mathbf{W} }'(\mathbf{x}_m, m, \theta_d) = f_{\mathbf{W} }(\mathbf{x}_m, g(m), h(\theta_d)) \label{eq:2} \end{equation}\]其中,$g(m), h(\theta_d)$ 是方法依赖的函数,对于PI,有 $g(m) = m / s, h(\theta_d) = \theta_d$ 。
此外,定义 $\lambda_d$ 为RoPE在第 $d$ 个维度的波长:
\[\begin{equation} \lambda_d = \frac{2\pi}{\theta_d} = 2\pi b^{\frac{2d}{|D|} } \end{equation}\]波长描述了在第 $d$ 个维度上,RoPE旋转 $2 \pi$ 所需要的tokens长度。
即 $\lambda_d \theta_d = 2 \pi$ ,对于第 $d$ 维度的旋转,若其token的位置为 $\lambda_d$ ,则执行了 $e^{i \lambda_d \theta_d} = e^{i2\pi}$ ,刚好旋转一周。
PI 不关心各个维度的波长(从波长的定义来看,波长仅与 $\theta_d$ 有关),这种插值方法我们称为盲插值法。本文的YaRN则属于目标插值方法。此外,有一些方法通过修改注意力机制来实现上下文扩展。
二、方法
(一)高频信息丢失——NTK-aware插值法
根据神经正切核(Neural Tangent Kernel,NTK)理论和文献,当输入维度较低且对应的嵌入缺乏高频成分时,深度神经网络难以学习到高频信息。token的位置信息本质是一维的,直接使用低维嵌入会限制模型对位置变化的学习能力。RoPE通过将一维位置信息扩展为高维复数向量嵌入,解决了低维嵌入的问题。
如何理解这里的低频和高频?
假设位置 $m$ 处的token的嵌入维度为 $D$ ,那么经过两两维度的组合,能够变换为维度为 $\frac{D}{2}$ 的复数域向量。如下所示,旋转矩阵会在位置 $m$ 处的每个维度 $d$ 上分别乘上 $e^{im\theta_d}$ 用于旋转角度,且 $\theta_d = b^{-2d/D}$ ,其中 $b=10000$ ,$d=(0,1,2,\dots,\frac{D}{2}-1)$ (在RoPE原文和众多代码实现中,$d$ 的索引从0开始,也就是说第一个维度(索引0)的 $\theta_d=1$ ,其编码是线性的)。
\[\begin{equation} \begin{bmatrix} \text{dim}_{\frac{D}{2} } \\ \vdots \\ \text{dim}_2 \\ \text{dim}_1 \end{bmatrix} \rightarrow \begin{bmatrix} e^{i m \theta_{\frac{D}{2} }} \\ \vdots \\ e^{i m \theta_2} \\ e^{i m \theta_1} \end{bmatrix} \end{equation}\]可以看出,最终在复数域旋转的角度为 $m\theta_d$ ,即旋转的角度只与位置 $m$ 和维度 $d$ 有关($\theta_d \sim d$)。其中,若 $D=64$ ,则 $\theta_d$ 随维度 $d$ 的变化曲线如下图所示,在本例中,$d$ 的取值范围为0-31。
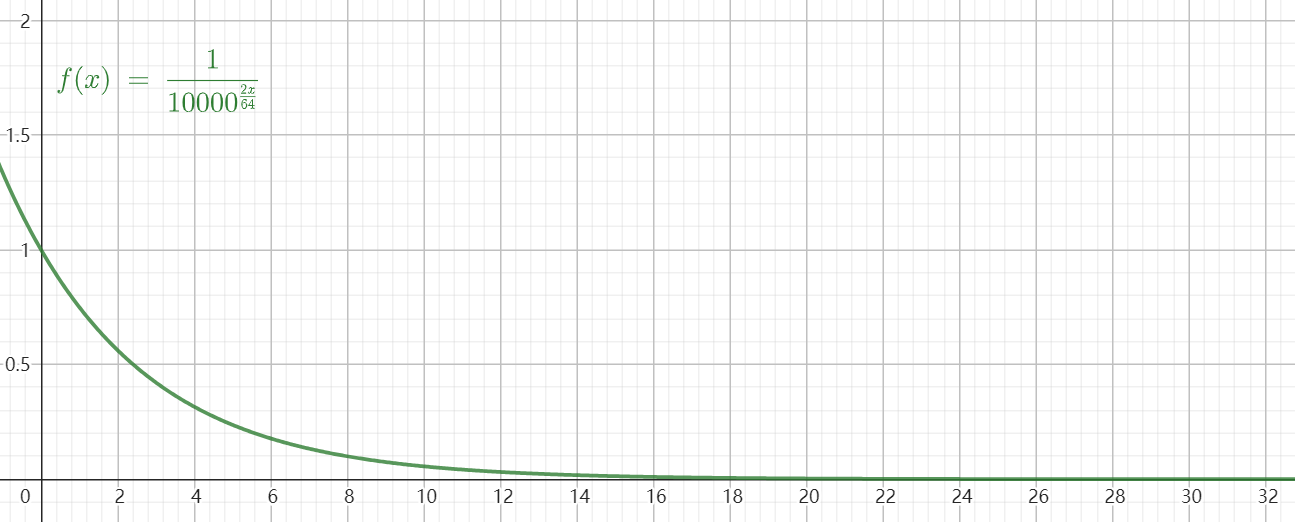
因此,相同位置下,越高的维度,其 $\theta_d$ 越小,即旋转角度越小;相同维度时,不同位置的旋转角度为倍数关系。可见,在低维度时,旋转角度延位置方向变化的更快,即高频,对应短波长。反之,在高维度时,是低频,对应长波长。如下图所示(下图的旋转角度只是为了直观而人为设定的)。
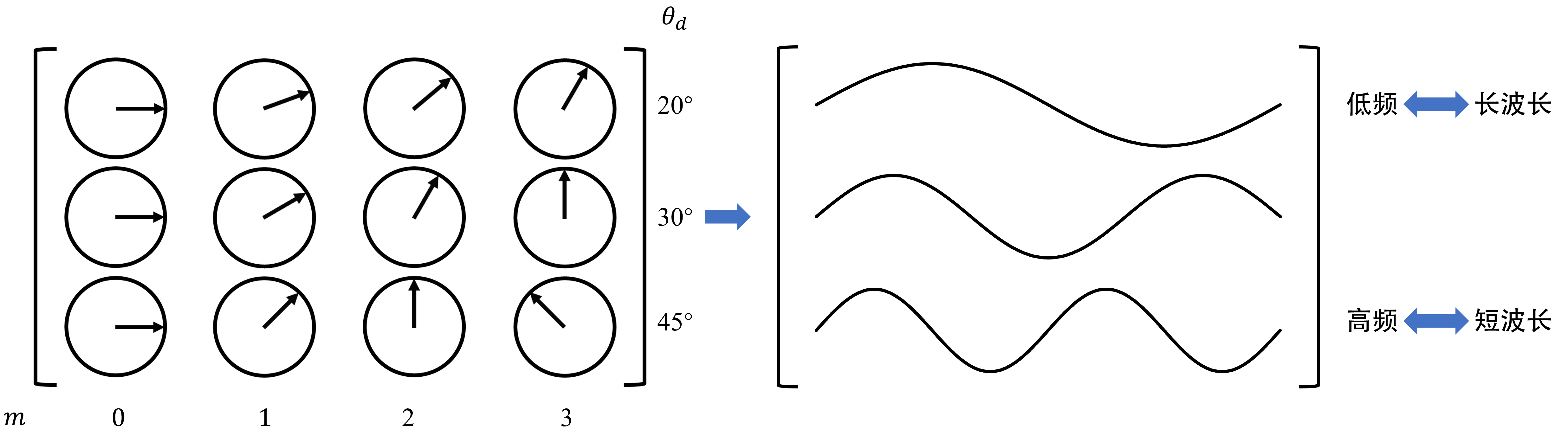
低维度的快速旋转适合捕捉局部的位置关系,高维度的慢速旋转适合捕捉全局的位置关系。高频细节的重要性:相邻或相似的token需要依赖高频成分来区分它们的相对位置,低维的最小旋转角度不能过小(即频率不能过低),否则网络无法检测到细微的位置差异。PI相当于对所有的维度等比例缩放了 $m$ ,会导致高频成分被过度压缩(即相当于使高频频率下降了),丢失关键的高频细节,导致模型无法有效分辨短距离内的token关系。因而当模型在长上下文上微调后,短上下文任务的困惑度(perplexity)反而略微增加。理想情况下,在更大的上下文规模上进行微调后,不应降低较小上下文规模的性能。
为了解决这一问题,Reddit一篇post提出了NTK-aware插值,对RoPE的高频成分少缩放(保留高频细节),对低频成分多缩放(允许更大范围的扩展),从而平衡不同频率的信息保留。其插值方法对公式 $\eqref{eq:2}$ 做出如下修改:
\[\begin{align} g(m) &= m \\ h(\theta_d) &= b'^{-2d/|D|} \end{align}\]其中:
\[\begin{equation} b' = b \cdot s^{\frac{|D|}{|D| - 2} } \end{equation}\]$s$ 即为前文提到的比例因子,它是扩展的上下文长度和原始上下文长度之比,因此大于1。可见,NTK-aware实际上是将 $\theta_d$ 的基底 $b$ 进行了放大。仍以上面的 $D=64$ 为例,若将基地从10000放大到50000,两个曲线的对比如下图所示:
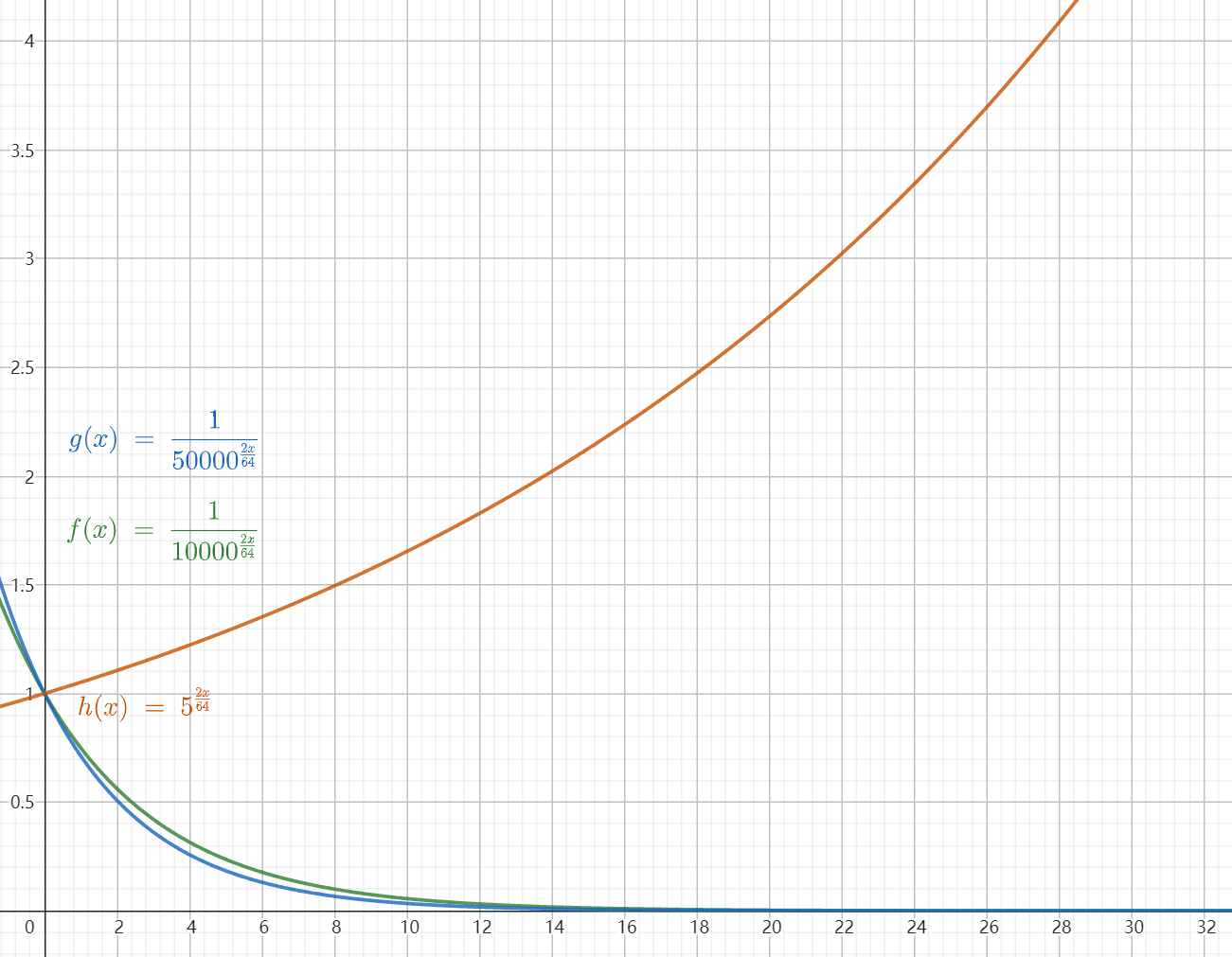
为了更清楚的看出对基底放大前与放大后 $\theta_d$ 的大小关系,上图中我们绘制出 $h(x)$ ,即基底放大前与放大后的比值曲线。可见,随着维度的升高,高维度(低频)部分的 $\theta_d$ 被缩小的倍数越来越大,相比之下低维度(高频)部分缩小的倍数较小。因此对于低维度,若扩展长度L’超过一定值后,更容易使 $L’\theta’_d > L\theta_d$ ,即产生越界。
该文献结果显示,与PI相比,在扩展非微调模型时表现更好,但在微调后不如PI。因为对于一些高频部分 $\theta_d$ 变化较小,仍以接近原有的频率振荡,因此若长度超出一定值,会产生外推。这些外推是基于新的缩小了的 $\theta’_d$ 产生的,其数据在训练时未见过,因此微调可能导致性能下降。为了减少这种影响,可以让 $h(x)$ 变得更陡峭,即人为设定一个更大的 $s$ ,例如Code Llama将基底 $b$ 从10000调至了1M。
插值与外推就看最终推理时的长度L’所旋转的最终角度,比在训练时长度L所旋转最终角度小还是大。如果小,则说明尽管长度L’变大了,但由于一定的缩放,最终旋转角度仍然在训练时的RoPE范围内,即插值;如果大,则说明推理时会出现训练时没见过的旋转角度,即外推。
(二)相对局部距离损失——NTK-by-parts插值法
在像PI和NTK-aware这样的盲插值法中,我们平等的对待所有的RoPE维度(不考虑波长而盲目 的对所有维度插值),这些方法存在种种问题,因此需要一种有针对性的分层插值方法。
在RoPE中,需要注意以下两点:
- 高频维度(低维度)的 $\theta_d$ 大,波长短,对应短距离位置的精细区分;
- 低频维度(高维度)的 $\theta_d$ 小,波长长,对应长距离的全局位置信息。
给定预训练的上下文长度 $L$ ,不同维度 $d$ 的波长 $\lambda_d$ 不同,存在以下几种情况:
- 当 $\lambda_d > L$ 时,该维度的位置范围仅训练到 $L$ ,每个位置的编码在预训练中未经历完整周期,不同位置的编码在旋转后具有唯一性,这就保留了绝对位置信息。
- 当 $\lambda_d < L$ 时,每个位置的编码在预训练中至少经历过一个完整周期,位置编码存在重复,模型适合感知相对位置信息。
若对所有维度进行统一缩放(例如通过比例因子 $s$ 或基底变换 $b’$),会导致以下问题:
- 缩放使得 $\theta_d$ 变小,每个维度的震荡频率放缓
- 两个旋转角度较小的角度点积会放大,即相似度会变大
- 模型难以区分token的相邻局部关系,导致对短距离依赖的判读错误,这也从另一个角度解释了高频细节的丢失
为了解决这个问题,我们选择分层插值,即不插值高频维度(低维度),插值低频维度(高维度):
- 若 $\lambda \ll L$ ,则不进行插值,保留原始高频信息,避免压缩导致的局部关系丢失。
- 若 $\lambda \geq L$ ,则进行插值,并避免外推。这些维度在预训练时未被充分训练,需通过插值扩展其范围,但必须避免外推到未见过的区域。
- 若介于以上两者之间,则使用类似NTK-aware的方法。
为此,引入比率:
\[\begin{equation} r(d)=\frac{L}{\lambda_d}=\frac{L}{2 \pi b^{\frac{2d}{|D|} }} \end{equation}\]为了定义上述不同插值策略的边界,引入两个额外的参数 $\alpha, \beta$ :
- 所有满足 $r(d)<\alpha$ 的维度 $d$ ,通过缩放因子 $s$ 对其进行线性内插(类似于PI,可确保不越出边界)
- 所有满足 $r(d)>\beta$ 的维度 $d$ ,不进行插值
如下图所示:
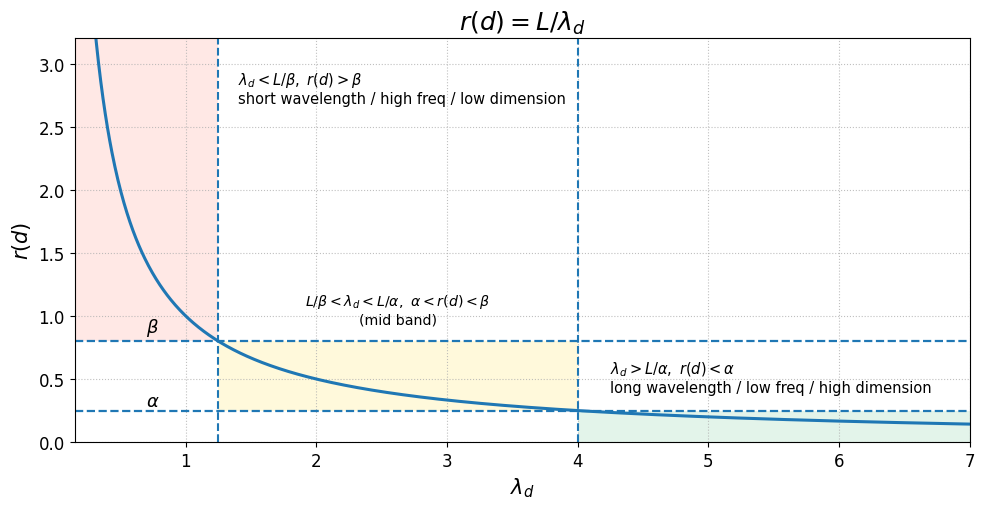
其中,红色底色代表短波长、高频的低维部分,绿色底色代表长波长、低频的高维部分。
定义斜坡函数(ramp function) $\gamma$ :
\[\begin{equation} \gamma(r) = \begin{cases} 0, & \text{if } r < \alpha \\ 1, & \text{if } r > \beta \\ \frac{r - \alpha}{\beta - \alpha}, & \text{otherwise} \end{cases} \end{equation}\]借助斜坡函数,NTK-by-parts可通过对公式 $\eqref{eq:2}$ 修改表示如下:
\[\begin{align} g(m) &= m \\ h(\theta_d) &= \left(1 - \gamma(r(d))\right) \frac{\theta_d}{s} + \gamma(r(d)) \theta_d \end{align}\]$\alpha, \beta$ 的值应根据实际情况进行调整。对于Llama模型,实验发现较好的值为 $\alpha=1, \beta=32$ 。NTK-by-parts不论是在微调还是非微调模型中,表现均优于PI和NTK-aware。
(三)动态缩放——Dynamic NTK插值法
在自回归生成等场景中,模型需要处理的序列长度每次会增加1。因此,我们可以有两种通过比例因子 $s$ 进行插值的方法,即:
- 在整个推理周期中,保持全局固定比例因子 $s=L’/L$ ,其中 $L’$ 是固定的扩展上下文长度;
- 在每次前向传播过程中,位置编码更新比例因子 $s=\text{max}(1, l’/L)$ ,其中, $l’$ 是当前序列的序列长度。
第1个方法的问题在于,当输入长度小于 $L$ 时, 模型可能因过度缩放而性能下降,当输入长度超过 $L’$ 时,模型性能会突然崩溃(abrupt degradation)。
第2种方法,允许模型在超出 $L’$ 时渐进式退化(graceful degradation),而非突然失效。这种方法被称为动态缩放(Dynamic Scaling),若与NTK-awere方法相结合,便称为Dynamic NTK。值得注意的是,Dynamic NTK在未微调的预训练模型(即 $L’=L$ )上表现非常好。
在自回归任务中,通常会使用KV Cache技术来提高整体效率。需要注意的是,若缓存的KV向量已经应用了RoPE,则会导致KV缓存中使用的是过去的 $s$ 所对应的位置编码。正确的做法是,在应用RoPE之前缓存原始的KV,因为当 $s$ 变化时,每个token的RoPE位置嵌入会更新,因此必须重新计算位置信息,然后再应用RoPE。
(四)YaRN
接下来进入到本文介绍的YaRN,有了以上基础,就很容易理解。
核心思想:
- 引入温度参数 $t$,可以均匀控制模型对不同位置token的注意力权重,从而影响困惑度(perplexity),且对不同的数据样本和token位置均有效,经过温度参数缩放的注意力计算如下:
- RoPE的重新参数化,通过将 $\mathbf{q}_m$ 和 $\mathbf{k}_n$ 的复数RoPE嵌入同时缩放 $\sqrt{1/t}$ ,可以避免直接修改注意力机制代码而实现温度参数的引入。此外,在推理和训练时,RoPE是预先计算好的,可以重复用于前向传播,因此可实现零额外计算开销。
- 与NTK-by-parts相结合,就成了完整的YaRN方法。
对LLaMA和Llama2系列模型,文章推荐使用如下公式:
\[\begin{equation} \sqrt{\frac{1}{t} } = 0.1 \ln(s) + 1 \end{equation}\]这一公式通过实验拟合LLaMA不同规模模型的困惑度最优值得出,并验证了对Llama2模型的通用性。YaRN在微调和非微调场景中,都超过了先前的方法,得益于其低开销,YaRN可直接兼容修改注意力机制的库,如Flash Attention 2。
三、总结
论文后续的实验验证不再详细记录。用论文结论的最后一句话来总结YaRN的特点:train short, and test long。