【论文解读】Gated Attention
Categories: Paper
目录
概览
本文通过实验系统研究了门控增强的 softmax 注意力变体,并发现:在缩放点积注意力(Scaled Dot-Product Attention, SDPA)后应用特定于头的 sigmoid 门控,能持续提升性能、增强训练稳定性、容忍更大学习率并提升 scaling 特性。这主要源于以下两个因素的影响:一是在 softmax 注意力的低秩映射上引入了非线性,二是应用依赖查询的稀疏门控分数调节了 SDPA 的输出。此外,这个稀疏门控机制还可以缓解 Attention Sink,并提升长上下文外推性能。
原文链接:Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
一、Gated-Attention Layer
(一)Multi-Head Softmax Attention
首先简要回顾多头注意力机制。给定输入 $X \in \mathbb{R}^{n \times d_{\text{model} }}$,其中 $n$ 是序列长度,$d_{\text{model} }$ 是模型维度,Transformer 注意力层的计算可分为四个阶段。
QKV 线性投影:输入 $X$ 通过可学习的权重矩阵 $W_Q, W_K, W_V \in \mathbb{R}^{d_{\text{model} } \times d_k}$ 线性变换为查询 $Q$、键 $K$ 和值 $V$,其中 $Q, K, V \in \mathbb{R}^{n \times d_k}$: \(\begin{equation} Q = X W_Q, \quad K = X W_K, \quad V = X W_V \end{equation}\) 缩放点积注意力(SDPA):计算查询与键之间的注意力得分,随后进行 softmax 归一化。输出是值的加权和: \(\begin{equation} \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{Q K^\top}{\sqrt{d_k} } \right) V \end{equation}\) 其中 $\frac{Q K^\top}{\sqrt{d_k} } \in \mathbb{R}^{n \times n}$ 表示缩放后的点积相似度矩阵,$\text{softmax}(\cdot)$ 确保注意力权重非负且每行之和为 1。
多头拼接:在多头注意力中,上述过程对 $h$ 个头并行执行,每个头拥有各自的投影矩阵 $W_q^i, W_K^i, W_V^i$。所有头的输出被拼接: \(\begin{equation} \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h) \end{equation}\) 其中 $\text{head}_i = \text{Attention}(Q W_Q^i, K W_K^i, V W_V^i)$。
最终输出层:拼接后的 SDPA 输出通过一个输出层 $W_o \in \mathbb{R}^{h d_k \times d_{\text{model} }}$: \(\begin{equation} O = \text{MultiHead}(Q, K, V) W_o \end{equation}\)
(二)通过门控机制增强 Attention Layer
门控机制的形式化定义为: \(\begin{equation} Y' = g(Y, X, W_\theta, \sigma) = Y \odot \sigma(X W_\theta) \end{equation}\) 其中 $Y$ 是待调节的输入,$X$ 是用于计算门控得分的另一输入,$W_\theta$ 表示门控的可学习参数,$\sigma$ 是激活函数(例如 sigmoid),$Y’$ 是门控后的输出。门控得分 $\sigma(X W_\theta)$ 进行动态过滤,通过选择性保留或擦除特征来控制从 $Y$ 中的信息流动。
本文主要聚焦于五个关键方面:(1) 位置。研究在不同位置应用门控的效果,如下图所示:(a) 在 $Q, K, V$ 投影之后,对应图 中的 $G_2, G_3, G_4$;(b) 在 SDPA 输出之后($G_1$);(c) 在最终拼接的多头注意力输出之后($G_5$)。(2) 粒度。考虑两种门控得分的粒度级别:(a) 头级(Headwise):单个标量门控得分调节整个注意力头的输出。(b) 元素级(Elementwise):门控得分是与 $Y$ 维度相同的向量,支持细粒度、逐维度的调节。(3) 特定头或共享。考虑到注意力的多头特性,进一步考虑:(a) 特定头(Head-Specific):每个注意力头拥有其专属的门控得分,实现对每个头的独立调节。(b) 头共享(Head-Shared):$W_\theta$ 和门控得分在所有头之间共享。(4) 乘法或加法。对于将门控得分应用于 $Y$,考虑:(a) 乘法门控:门控输出 $Y’$ 计算为 $Y’ = Y \cdot \sigma(X \theta)$。(b) 加法门控:$Y’ = Y + \sigma(X \theta)$。(5) 激活函数。主要考虑两种常用激活函数:SiLU 和 sigmoid。由于 SiLU 的输出范围无界,仅在加法门控中使用它,而 sigmoid 的输出仅在 $[0, 1]$ 范围内。此外,为了进一步剖析门控有效性的内在机制,还考虑恒等映射或 RMSNorm。
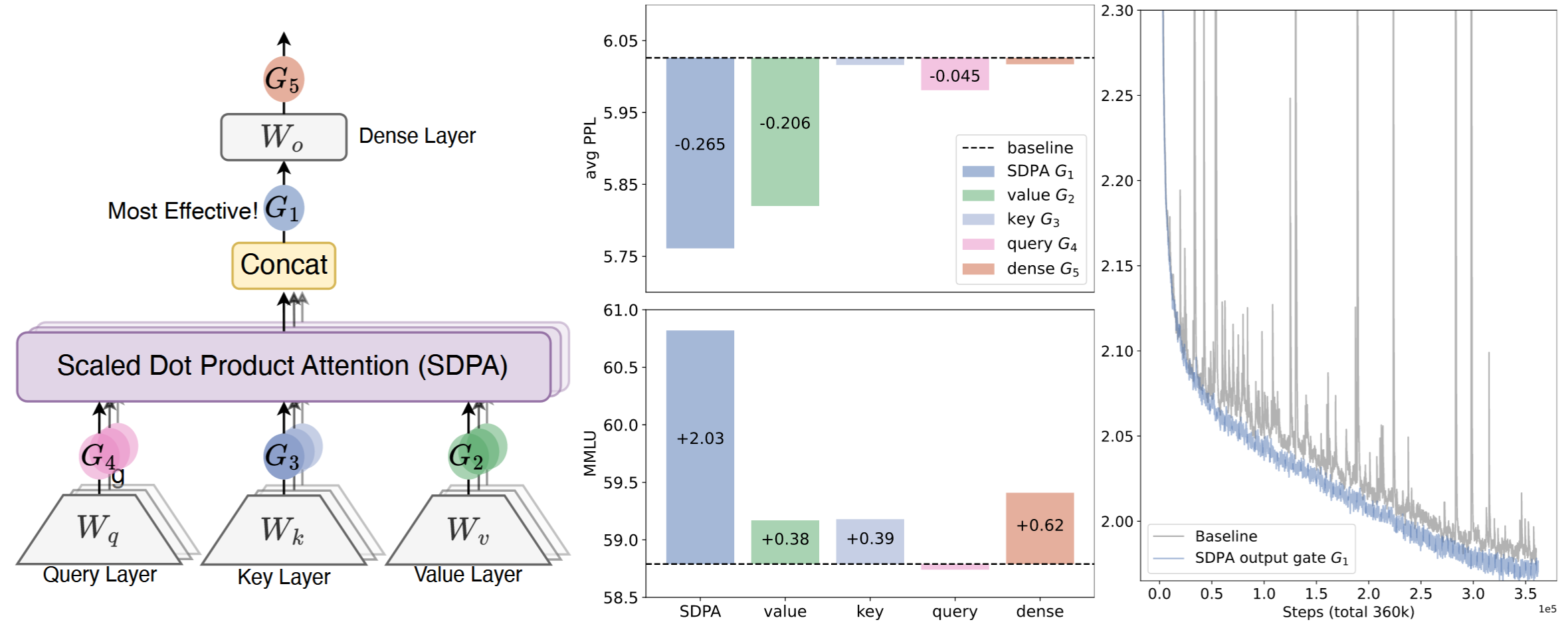
二、实验
(一)实验设置
本文主要在 MoE 模型(15B 总参数量,激活参数 2.54B,即 15A2B)和 Dense 模型(1.7B 参数量)进行了实验。在含多语言、数学、通用知识的 3.5T 高质量 tokens 子集上训练,上下文序列长度 4096。在多个基准上进行少样本测试,包括英语的 Hellaswag、通用知识的 MMLU、数学推理的 GSM8k、编码的 HumanEval、中文能力的 C-eval 和 CMMLU。
(二)主要结果
1. MoE
所有模型都使用了一个调度器,该调度器在 1k 步内将学习率 warm up 到 2e-3,然后余弦衰减至 3e-5。使用全局 1024 的 batch size,共包含100k 个优化步骤。以 vanilla MoE (1) 为对比基线,并补充了参数扩展方法,包括 (2) 增加 key-value heads,(3) 增加 query heads,(4) 增加专家总数和激活总数,这些方法引入的参数量与门控机制的相当或更多。
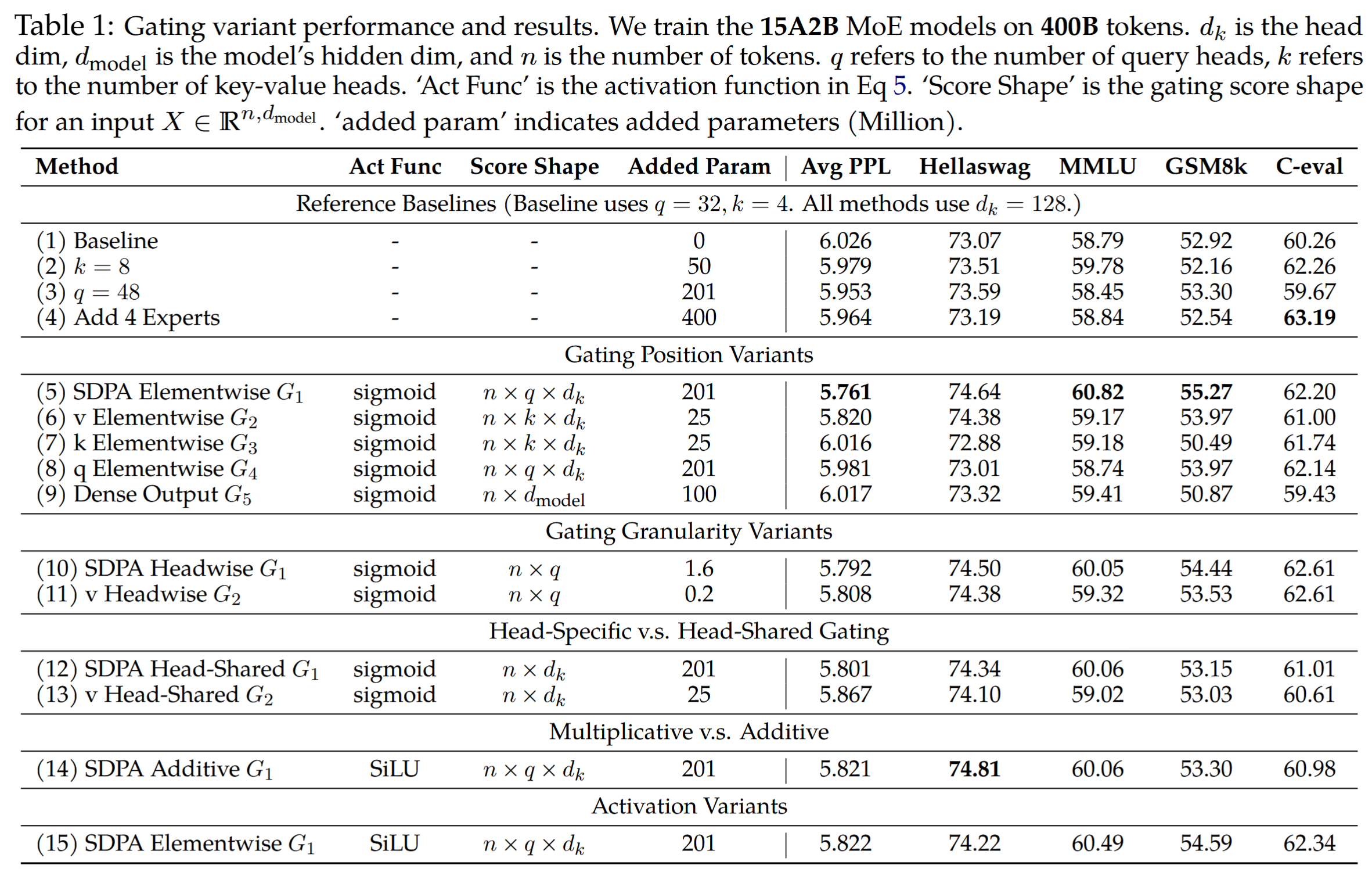
结果表明:
- 在 SDPA ($G_1$) 和 value map $G_2$ 后插入 gate 是最有效的
- headwise 的 $G_1$ 和 $G_2$ 仅引入极少的额外参数,但仍能带来显著的改进 (10)(11)
- 加法门控尽管比基线有改进,但仍不如乘法门控
- sigmoid 激活函数更有效
2. Dense
在 Dense 模型上对 SDPA 输出的 sigmoid 门控机制进行了验证。在使用门控机制时,减小了前馈网络(FFN)的宽度,以保持参数规模不变。此外,先前的研究已经证实,虽然增加网络深度、采用较大的学习率和较大的批处理大小能够显著提升模型性能和分布式训练效率,但它们往往会引发训练不稳定性。而应用门控机制明显减少了训练过程中损失峰值的出现,这表明门控机制在增强训练稳定性方面具有潜在作用。
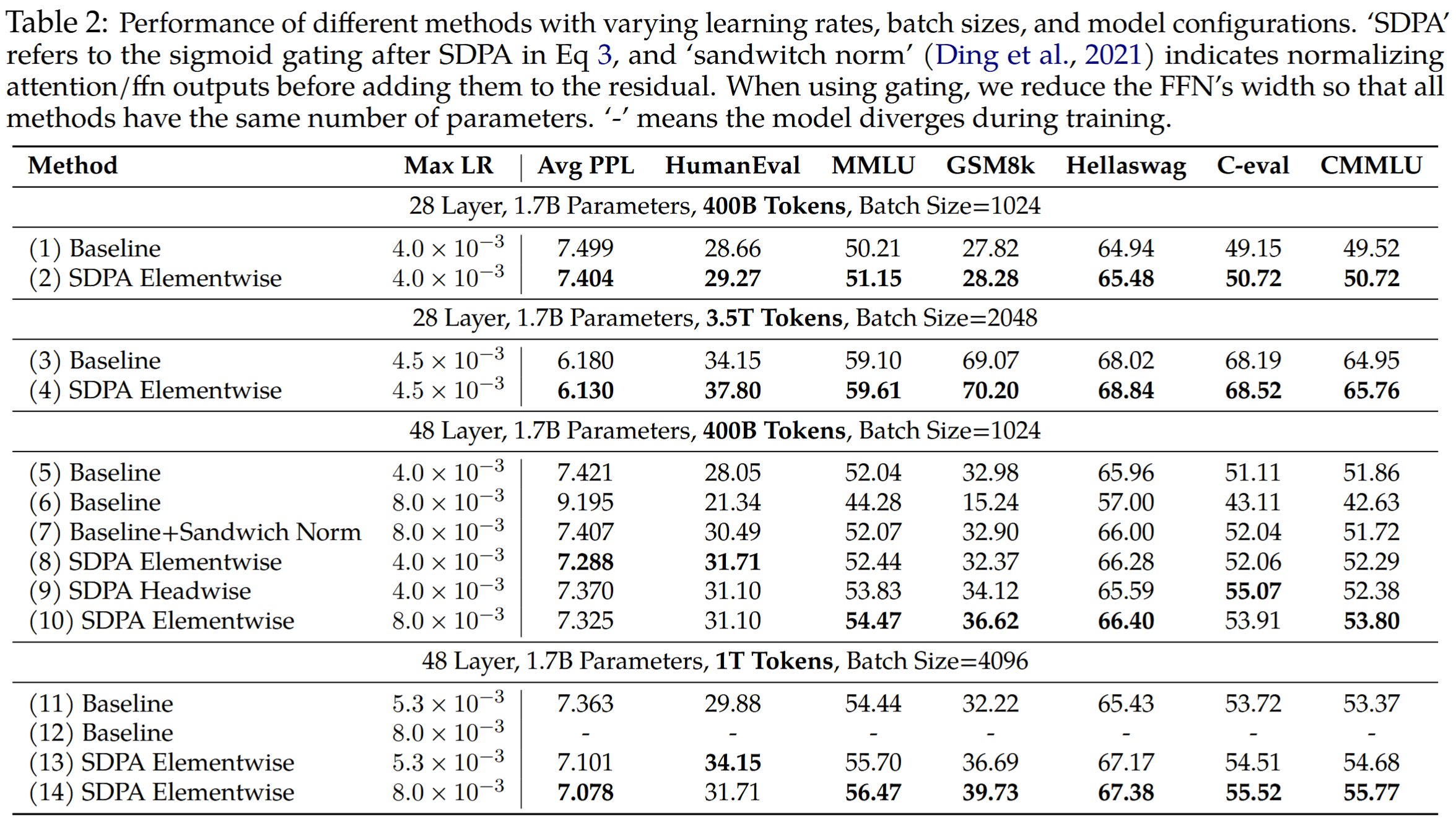
结果表明:
- 门控机制在各种实验设置下均有效
- 门控提高了稳定性并有助于扩展
三、分析
(一)非线性提升注意力机制中低秩映射的表达能力
受到先前工作的启发,在每个注意力头的输出拼接之前,独立加入 RMSNorm,可以在几乎不引入额外参数的情况下显著降低 PPL,如表 3 (5) 所示。
在多头注意力中,第 $i$ 个 token 对应于第 $k$ 个头的输出可表示为: \(\begin{equation} o_i^k = \left( \sum_{j=0}^{i} S_{ij}^k \cdot X_j W_V^k \right) W_O^k = \sum_{j=0}^{i} S_{ij}^k \cdot X_j (W_V^k W_O^k) \end{equation}\) 中 $W_O^k$ 是输出层 $W_O$ 中对应第 $k$ 个头的参数。这里,$S_{ij}^k$ 表示第 $i$ 个 token 在第 $k$ 个头中对第 $j$ 个 token 的注意力得分,$X_j$ 是第 $j$ 个 token 的输入,而 $X_j W_V^k$ 表示第 $j$ 个 token 在第 $k$ 个头中的 value 输出。由上式可知,我们可以将 $W_V^k W_O^k$ 合并为一个作用于所有 $X_j$ 的低秩线性映射(因为 $d_k < d_{\text{model} }$)。在 GQA(Grouped Query Attention)中,$W_V$ 在同一组内的头之间共享,进一步降低了表达能力。
对任意矩阵 $A \in \mathbb{R}^{m \times r}$, $B \in \mathbb{R}^{r \times n}$,有:$\operatorname{rank}(AB) \leq \min(\operatorname{rank}(A), \operatorname{rank}(B)) \leq r$,这里 $r = d_k$,因此 $\operatorname{rank}(W_V^k W_O^k) \leq d_k$。所以它是一个 $d_{\text{model} }$ 到 $d_{\text{model} }$ 的线性变换,但秩最多只有 $d_k$,这就是低秩线性映射的含义。
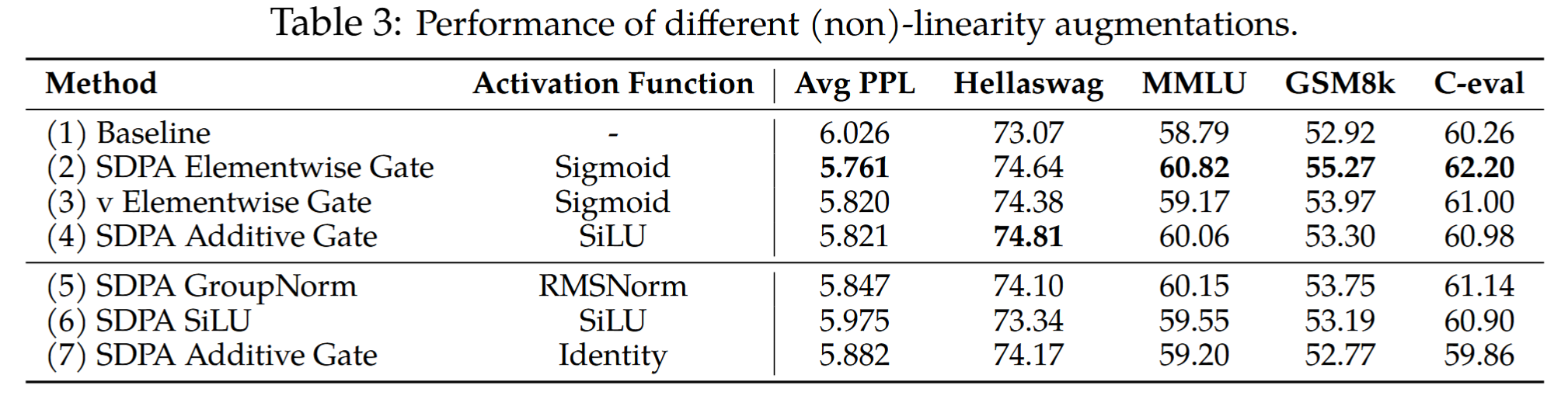
考虑到在两个线性映射之间引入非线性可以提升其表达能力,以下两种修改以缓解低秩问题: \(\begin{align} o_i^k = \left( \sum_{j=0}^{i} S_{ij}^k \cdot \text{Non-Linearity-Map}(X_j W_V^k) \right) W_O^k \label{eq:g2} \\ o_i^k = \text{Non-Linearity-Map} \left( \sum_{j=0}^{i} S_{ij}^k \cdot X_j W_V^k \right) W_O^k \label{eq:g1} \end{align}\) 值得注意的是,在 $G_2$ 位置(表 3 第 3 行)添加门控对应第一种修改,而在 $G_1$ 位置添加门控(第 4 行)或分组归一化(第 5 行)则对应第二种修改。这也解释了为什么在 $W_O$ 之后的 $G_5$ 位置添加门控或归一化没有效果(表 1 第 9 行)——因为它并未解决 $W_V$ 和 $W_O$ 之间缺乏非线性的根本问题。
(二)门控引入了输入依赖的稀疏性
下表和下图展示了 $G_1$ 和 $G_2$ 的所有层的平均 gating scores、score 分布情况等。
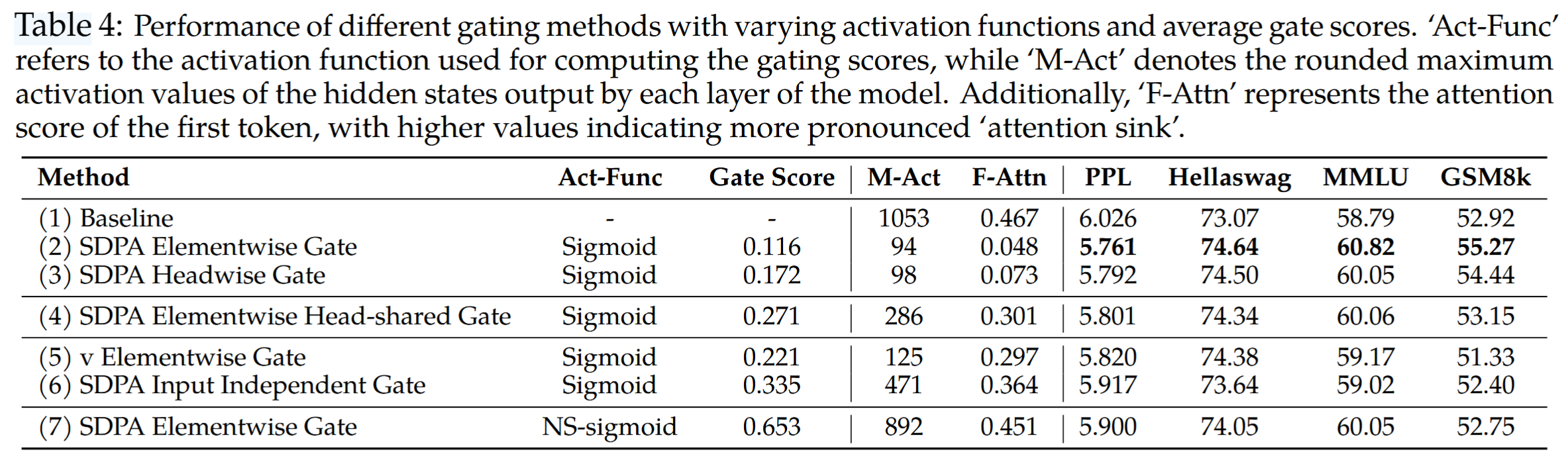
核心发现包括:
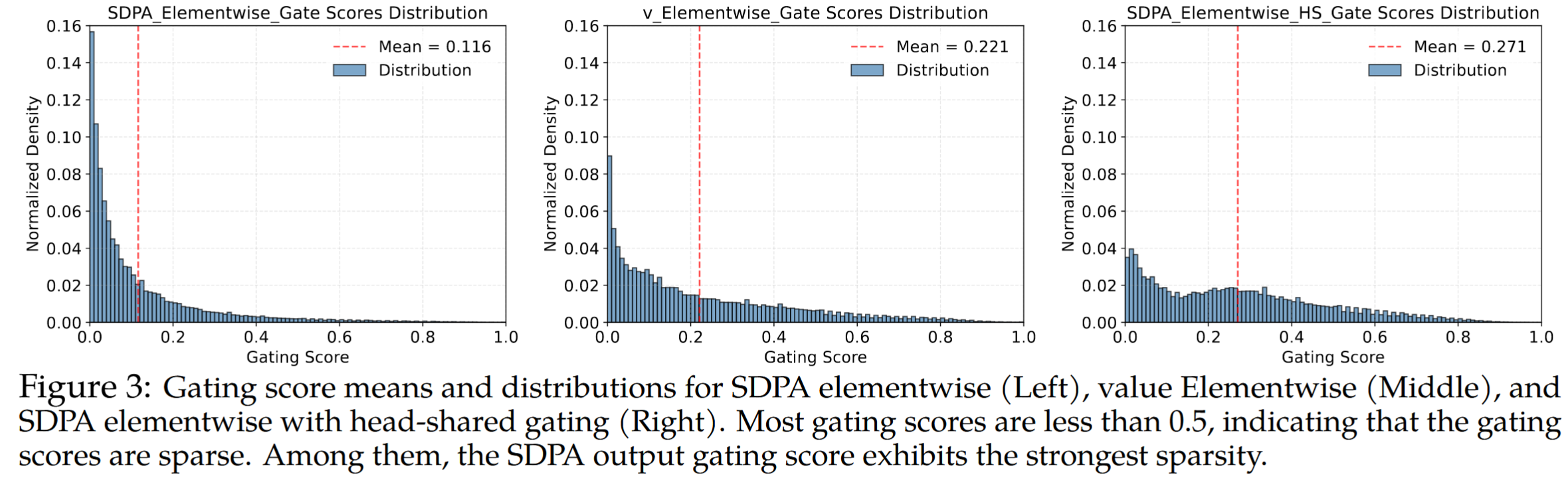
- 有效的门控分数具有稀疏性。SDPA 输出门控分数的分布在 0 值附近高度集中,这表明其具有显著的稀疏性,与其卓越性能相符。
- 特定头的稀疏性至关重要。强制跨注意力头共享门控分数会提高整体门控分数,并削弱性能增益。
- 输入依赖更重要。$G_2$ 的门控得分高于 $G_1$,这表明当 query-dependent 时,门控得分的稀疏性效果更好。具体来说,公式 $\eqref{eq:g1}$ 中的门控得分源于当前 query 聚合后的结果,而公式 $\eqref{eq:g2}$ 中的门控得分源于每一个被 attend 的 token $j$ 上。
- 门控稀疏性较低则效果更差。若使用一种经过修改的非稀疏 (Non-Sparse, NS) 版本:$\text{NS-sigmoid}(x)=0.5+0.5 \cdot \text{sigmoid}(x)$,它将门控限制在 $[0.5,1.0]$ 范围内,则其效果不如稀疏版本。
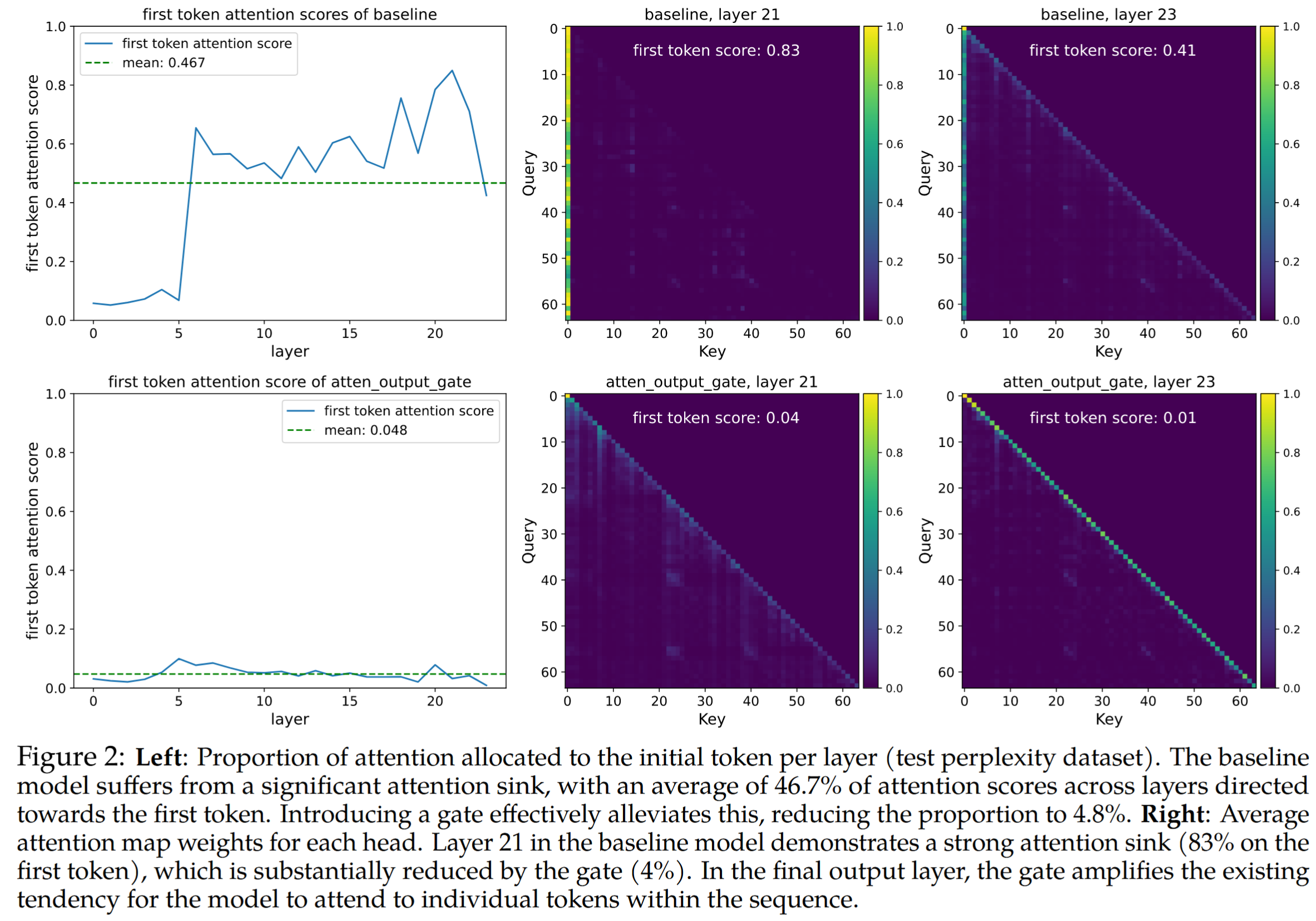
(三)SDPA 输出门控降低了 Attention-Sink
核心发现包括:
- $G_1$ 门控在很大程度上降低了分配给第一个 token 的注意力分数,并减少了大量激活。
- 强制跨头共享门控分数,或者仅应用 $G_2$ 门控,会减少大量激活,但不会降低对一个 token 的注意力分数,这强调了特定头门控的重要性。
- 降低门控的输入依赖,或使用 NS-sigmoid 来减少稀疏性,会同时加剧大量激活和 Attention-Sink。
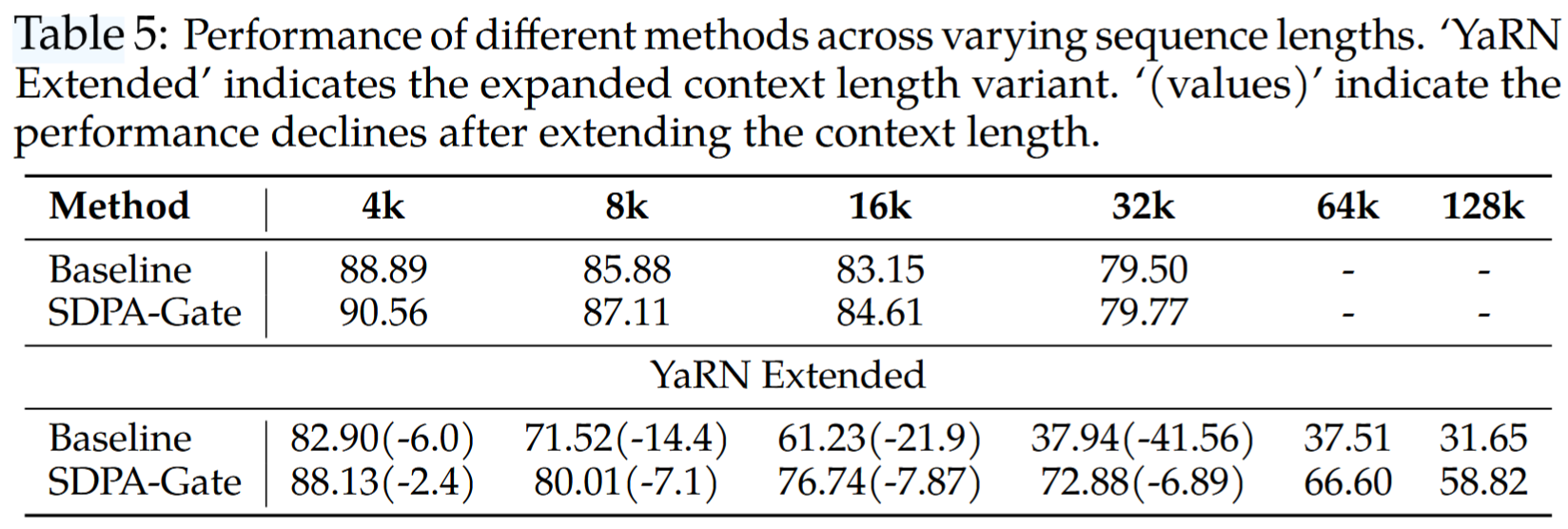
(四)SDPA 输出门控有利于长上下文扩展
首先将 RoPE 的 base 从 10k 增加到 1M,并继续在 32k 的上下文长度上训练了 80B tokens,然后通过 YaRN 将上下文长度进一步扩展到 128k。在 RULER 基准上进行评估,结果表明:
- 32k 设置下,带有门控的模型略优于基线模型。
- 当使用 YaRN 将上下文长度延长至 128k 时,基线模型和带门控的模型在原来的 32k 范围内都出现了性能下降。带门控的模型性能下降不太明显。
- 在 64k 和 128k 的上下文长度下,带门控的注意力模型显著优于基线模型。
四、总结
通过系统探究门控机制在 softmax 注意力机制中的作用,发现在缩放点积注意力后应用 sigmoid 门控改进效果最显著。该简单机制可增强非线性、引入输入依赖的稀疏性、消除 attention sink 等问题,还有助于上下文长度扩展。