【论文解读】Gated Delta Network
Categories: Paper
目录
概览
线性 Transformer 虽作为标准 Transformer 的高效替代方案受到关注,但在检索和长上下文任务中性能有限。它可以被解释为实现了一种基于外积的 key-value 关联记忆,然而,其能够存储的容量受到模型维度的限制。当序列长度超过这个维度时,记忆冲突就不可避免,从而阻碍了精确检索。
Mamba2 通过引入一个简单的门控更新规则 $\mathbf{S}_t = \alpha_t \mathbf{S}_{t-1} + v_t k_t^\top$ 来解决这一局限性,该规则在每个时间步以动态比率 $\alpha_t \in (0,1)$ 均匀衰减所有键值关联。然而,这种方法没有考虑到不同键值关联的重要性差异,从而导致记忆利用效率低下。如果模型需要忘记某个特定的键值关联,所有的键值关联都会被同等程度地遗忘,这使得该过程的针对性和效率都有所降低。
相比之下,DeltaNet 采用 delta rule,通过顺序方式用新传入的键值对替换旧的键值对来选择性的更新记忆。然而,由于该过程每次只能修改一个键值对,模型缺乏快速清除过时或无关信息的能力,特别是在上下文切换期间,模型需要快速擦除先前数据。
本文提出的 gated delta rule 可以结合两种方法的优势,实现灵活的记忆控制。最终,得到的 Gated DeltaNet 在一系列全面的基准测试中始终优于 Mamba2 和 DeltaNet,这些测试包括语言建模、常识推理、上下文内检索、长度外推和长上下文理解。基于这些结果,文章还开发了混合架构,有策略地将 Gated DeltaNet 层与滑动窗口注意力或 Mamba2 层相结合,进一步提高了训练效率和模型性能。
原文链接:Gated Delta Networks: Improving Mamba2 with Delta Rule
一、预备知识
(一)Mamba2: Linear Attention with Decay
1. 基本介绍
线性 Transformer 可以写为如下形式(不考虑归一化和特征映射): \(\begin{equation} \mathbf{S}_t = \mathbf{S}_{t-1} + v_t k_t^\top \in \mathbb{R}^{d_v \times d_k}, \quad o_t = \mathbf{S}_t q_t \in \mathbb{R}^{d_v} \end{equation}\) 其中,$d_k$ 和 $d_v$ 分别表示 query/key 和 value 的维度。通过展开递推式,我们可以将其表示为向量形式(左侧)和矩阵形式(右侧): \(\begin{equation} o_t = \sum_{i=1}^t (v_i k_i^\top) q_t = \sum_{i=1}^t v_i (k_i^\top q_t) \in \mathbb{R}^{d_v}, \quad \mathbf{O} = (\mathbf{Q} \mathbf{K}^\top \odot \mathbf{M}) \mathbf{V} \in \mathbb{R}^{L \times d_v} \label{eq:la} \end{equation}\) 其中,$L$ 是序列长度,$\mathbf{M} \in \mathbb{R}^{L \times L}$ 是因果掩码,定义为当 $i < j$ 时 $\mathbf{M}_{ij} = 0$,即位置 $i$ 的 query 不应看到未来位置 $j$ 的 key,否则为 1。然而,这种简单的线性注意力在语言建模方面的表现远不如 Transformer。为了解决这个问题,通常会添加一个衰减项来遗忘历史信息。这里我们以 Mamba2 为例,它可以用以下线性递推关系表示: \(\begin{equation} \mathbf{S}_t = \alpha_t \mathbf{S}_{t-1} + v_t k_t^\top, \quad o_t = \mathbf{S}_t q_t \end{equation}\) 其中 $\alpha_t \in (0, 1)$ 是随时间变化的数据依赖的标量衰减项,取决于具体的参数化方法。我们可以将其逐步展开: \(\begin{equation} \begin{aligned} \mathbf{S}_t &= \alpha_t \mathbf{S}_{t-1} + v_t k_t^\top \\ &= \alpha_t (\alpha_{t-1} \mathbf{S}_{t-2} + v_{t-1} k_{t-1}^\top) + v_t k_t^\top \\ &= \alpha_t \alpha_{t-1} \mathbf{S}_{t-2} + \alpha_t v_{t-1} k_{t-1}^\top + v_t k_t^\top \\ &= \alpha_t \alpha_{t-1} (\alpha_{t-2} \mathbf{S}_{t-3} + v_{t-2} k_{t-2}^\top) + \alpha_t v_{t-1} k_{t-1}^\top + v_t k_t^\top \\ &= \alpha_t \alpha_{t-1} \alpha_{t-2} \mathbf{S}_{t-3} + \alpha_t \alpha_{t-1} v_{t-2} k_{t-2}^\top + \alpha_t v_{t-1} k_{t-1}^\top + v_t k_t^\top \\ &= \alpha_t \alpha_{t-1} \cdots \alpha_1 \mathbf{S}_0 + \alpha_t \alpha_{t-1} \cdots \alpha_2 v_1 k_1^\top + \cdots + \alpha_t v_{t-1} k_{t-1}^\top + v_t k_t^\top \end{aligned} \end{equation}\) 定义累积衰减乘积 $\gamma_j = \prod_{i=1}^j \alpha_i$,可进一步将上式写为: \(\begin{equation} \begin{aligned} \mathbf{S}_t &= \gamma_t \mathbf{S}_0 + \frac{\gamma_t}{\gamma_1} v_1 k_1^\top + \cdots + \frac{\gamma_t}{\gamma_{t-1} } v_{t-1} k_{t-1}^\top + \frac{\gamma_t}{\gamma_t} v_t k_t^\top \\ &= \gamma_t \mathbf{S}_0 + \sum_{i=1}^t \left( \frac{\gamma_t}{\gamma_i} v_i k_i^\top \right) \end{aligned} \label{eq:S} \end{equation}\) 其中 $\mathbf{S}_0=\mathbf{0}$,因此,可将输出结果表示为向量形式(左)和矩阵形式(右): \(\begin{equation} o_t = \sum_{i=1}^t \left( \frac{\gamma_t}{\gamma_i} v_i k_i^\top \right) q_t = \sum_{i=1}^t v_i \left( \frac{\gamma_t}{\gamma_i} k_i^\top q_t \right), \quad \mathbf{O} = ((\mathbf{Q} \mathbf{K}^\top) \odot \boldsymbol{\Gamma}) \mathbf{V} \in \mathbb{R}^{L \times d_v} \label{eq:mamba2} \end{equation}\) 其中:
- $\frac{\gamma_t}{\gamma_i}$ 表示第 $i$ 步的写入项 $v_i k_i^\top$ 在被用到第 $t$ 步时,会被后续所有门 $\alpha_{i+1}, \ldots , \alpha_t$ 乘一遍
- $\frac{\gamma_t}{\gamma_i} k_i^\top q_t$ 可以理解成:相似度打分 $k_i^\top q_t$ 乘上一个随距离与门控变化的时间衰减权重
- $\boldsymbol{\Gamma} \in \mathbb{R}^{L \times L}$ 是把所有的 $\frac{\gamma_t}{\gamma_i}$ 封装进了一个矩阵,是一个具有衰减感知的因果掩码,当 $i \geq j$ 时 $\Gamma_{ij} = \frac{\gamma_i}{\gamma_j}$,否则 $\Gamma_{ij} = 0$,即只对之前见过的 token 应用衰减
2. Chunkwise Training
上面公式 $\eqref{eq:la}$ 和公式 $\eqref{eq:mamba2}$ 的矩阵形式,是线性递归的另一种等价形式,也称为状态空间对偶性(State Space Duality, SSD)。然而,不论是原始的递归形式(Recurrent),还是等价的矩阵形式(Parallel),它们在训练时都不十分理想。Recurrent 是线性的,但是难并行,Parallel 则实际上又退回了 $O(L^2)$ 的复杂度。因此提出了 chunkwise parallel,它将输入输出划分为若干个大小为 $C$ 的 chunks,并根据前一个块的最终状态以及当前块的 query/key/value 来计算输出。
原文中似乎混用了两种堆叠方式,这里我们首先声明两种方式的差异:
假设一个 chunk 长度为 $C$,把这个 chunk 的 $q,k,v$ 堆叠成矩阵,如果按照行进行堆叠,则有: \(\mathbf{Q} \in \mathbb{R}^{C \times d_k}, \quad \mathbf{K} \in \mathbb{R}^{C \times d_k}, \quad \mathbf{V} \in \mathbb{R}^{C \times d_v}\) 也就是每一行分别是 $q^\top,k^\top,v^\top$。如果按照列进行堆叠,则有: \(\mathbf{Q} \in \mathbb{R}^{d_k \times C}, \quad \mathbf{K} \in \mathbb{R}^{d_k \times C}, \quad \mathbf{V} \in \mathbb{R}^{d_v \times C}\) 即每一列分别是 $q,k,v$。这里我们采用常用的行堆叠方式来推导,结果可能与原文存在一定差异,但实质是一样的。
(1)基本递推
我们以查询块 $q$ 为例。记 $\mathbf{Q}_{[t]} := q_{tC+1:(t+1)C+1}$ 为第 $t$ 个 chunk 的查询块,$q^r_{[t]} := q_{tC+r}$ 为 chunk $t$ 中的第 $r$ 个查询。chunk $t$ 的初始状态定义为 $\mathbf{S}_{[t]} := \mathbf{S}^0_{[t]} = \mathbf{S}^C_{[t-1]}$。通过部分展开递推关系,我们得到: \(\begin{equation} \mathbf{S}^r_{[t]} = \mathbf{S}_{[t]} + \sum_{i=1}^{r} v^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_v \times d_k}, \quad o^r_{[t]} = \mathbf{S}^r_{[t]} q^r_{[t]} = \mathbf{S}_{[t]} q^r_{[t]} + \sum_{i=1}^{r} v^i_{[t]} \left( k^{i\top}_{[t]} q^r_{[t]} \right) \in \mathbb{R}^{d_v} \end{equation}\) 其中,$\mathbf{S}^r_{[t]}$ 表示在 chunk $t$ 中的第 $r$ 个状态,它等于此 chunk 的初始状态 $\mathbf{S}_{[t]}$ (即上一个 chunk 的最后一个状态)加上从本 chunk 开始一直到第 $r$ 个 $v$ 和 $k$ 的外积。$o^r_{[t]}$ 表示 $\mathbf{S}^r_{[t]}$ 所对应的输出,对 $\mathbf{S}^r_{[t]}$ 乘上 $q^r_{[t]}$ 即可。同样的,我们可以把上式写为矩阵等价形式: \(\begin{equation} \mathbf{S}_{[t+1]} = \mathbf{S}_{[t]} + \mathbf{V}^\top_{[t]} \mathbf{K}_{[t]} \in \mathbb{R}^{d_v \times d_k}, \quad \mathbf{O}_{[t]} = \mathbf{Q}_{[t]} \mathbf{S}^\top_{[t]} + \left( \mathbf{Q}_{[t]} \mathbf{K}^\top_{[t]} \odot \mathbf{M} \right) \mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v} \label{eq:chunk} \end{equation}\) 其中,$\mathbf{S}_{[t+1]}$ 是第 $t+1$ 个 chunk 的初始状态(即第 $t$ 个 chunk 的最后一个状态),$\mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v}, \mathbf{K}_{[t]} \in \mathbb{R}^{C \times d_k}$ 按照行堆叠形成的矩阵。$\mathbf{V}_{[t]}^\top \mathbf{K}_{[t]}$ 是源于: \(\begin{equation} \mathbf{V}^\top_{[t]} \mathbf{K}_{[t]} = \underbrace{[v_{[t]}^1, v_{[t]}^2, \ldots, v_{[t]}^C]}_{\mathbf{V}^\top \text{转置为按列堆叠} } \cdot \underbrace{[k_{[t]}^{1\top}, k_{[t]}^{2\top}, \ldots , k_{[t]}^{C\top}]^\top}_{\mathbf{K} \text{仍为按行堆叠} }=\sum_{i=1}^{C} v^i_{[t]} k^{i\top}_{[t]} \label{eq:vtk} \end{equation}\) 然后,将公式 $\eqref{eq:chunk}$ 的左式转置后再左乘 $\mathbf{Q}_{[t]} \in \mathbb{R}^{C \times d_k}$ 并调整计算顺序后就得到右式,其中 $\mathbf{M} \in \mathbb{R}^{C \times C}$ 是因果掩码。上述公式包含大量矩阵乘法(matmuls),因此便于支持基于 tensor-core 的硬件优化。
(2)带衰减的递推
这种 chunkwise 算法可以方便的扩展到带有衰减的线性注意力。与公式 $\eqref{eq:S}$ 的推导过程类似,如果我们不是展开到最开始的时间步,而是展开到某个全局的中间时间步 $s$,则可以更通用的表示为: \(\begin{equation} \mathbf{S}_{t'} = \frac{\gamma_{t'} }{\gamma_s} \mathbf{S}_s + \sum_{i=s+1}^{t'} \left( \frac{\gamma_{t'} }{\gamma_i} v_i k_i^\top \right) \label{eq:commonS} \end{equation}\) 注意,为了与此部分的 chunk 时间步 $t$ 区分,上式我们把 $t’$ 记为全局时间步。对于 $\mathbf{S}^r_{[t]}$,它代表在第 $t$ 个 chunk 内的第 $r$ 个状态,即全局中的 $tC+r$ 个时间步。因此我们可以将 $\mathbf{S}^r_{[t]}$ 写为 $\mathbf{S}_{[t]}$ 加上后续累计写入的形式: \(\begin{equation} \begin{aligned} \mathbf{S}^r_{[t]} = \mathbf{S}_{tC+r} &= \frac{\gamma_{tC+r} }{\gamma_{tC} } \mathbf{S}_{tC} + \sum_{i=tC+1}^{tC+r} \left( \frac{\gamma_{tC+r} }{\gamma_i} v_i k_i^\top \right) \\ &= \frac{\gamma_{tC+r} }{\gamma_{tC} } \mathbf{S}_{[t]} + \sum_{i=tC+1}^{tC+r} \left( \frac{\gamma_{tC+r} }{\gamma_i} v_i k_i^\top \right) \end{aligned} \end{equation}\) 上式即就是把 $t’=tC+r$ 和 $s=tC$ 代入公式 $\eqref{eq:commonS}$ 得到。进一步,我们定义 $\gamma^j_{[t]} = \prod_{j=tC+1}^{tC+j} \alpha_j$(它和全局 $\gamma$ 的关系是 $\gamma_{tC+j} / \gamma_{tC}$,本质上是从 chunk 内起点到当前位置的相对累乘),则有: \(\begin{equation} \mathbf{S}^r_{[t]} = \gamma^r_{[t]} \mathbf{S}_{[t]} + \sum_{i=1}^{r} \left( \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } v^i_{[t]} k^{i\top}_{[t]} \right) \label{eq:str} \end{equation}\) 其中,$\gamma^r_{[t]}$ 的含义是:chunk 起点到当前位置 $r$ 的相对累乘;$\gamma^r_{[t]} / \gamma^i_{[t]}$ 的含义是:第 $i$ 次写入到当前位置 $r$ 的相对累乘。该位置的输出有: \(\begin{equation} o^r_{[t]} = \mathbf{S}^r_{[t]} q^r_{[t]} = \gamma^r_{[t]} \mathbf{S}_{[t]} q^r_{[t]} + \sum_{i=1}^{r} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } v^i_{[t]} \left( k^{i\top}_{[t]} q^r_{[t]}\right) \end{equation}\) 首先看第一项,它来自 chunk $t$ 的起点状态,定义 $\overleftarrow{q^r_{[t]} } := \gamma^r_{[t]} q^r_{[t]}$ , 它用左箭头表示将该向量衰减到 chunk $t$ 的起点(chunk 起点到当前位置 $r$ 的相对累乘),若将每个位置的 $\overleftarrow{q^r_{[t]} }$ 进行行堆叠,则形成 $\overleftarrow{\mathbf{Q}_{[t]} } \in \mathbb{R}^{C \times d_k}$,因此第一项为 $\overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}^\top_{[t]}$ 。
然后看第二项,如果想写成矩阵形式,需要定义一个 $C \times C$ 的权重矩阵,其第 $(r, i)$ 元素是 $(\mathbf{\Gamma}_{[t]})_{ri} = \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} }$ ,且仅在 $i \leq r$ 时有该衰减系数,其余为 0,保证因果。注意到: \(\begin{equation} (\mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top)_{ri} = (q^r_{[t]})^\top k^i_{[t]} \end{equation}\) 因此有: \(\begin{equation} ((\mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top) \odot \mathbf{\Gamma}_{[t]})_{ri} = \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } (q^r_{[t]})^\top k^i_{[t]} \end{equation}\) 最后右乘 $\mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v}$(其中第 $i$ 行为 $v^i_{[t]}$),即可得到每一行 $r$ 的输出。最终有矩阵形式: \(\begin{equation} \mathbf{O}_{[t]} = \overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}^\top_{[t]} + \left( \mathbf{Q}_{[t]} \mathbf{K}^\top_{[t]} \odot \mathbf{\Gamma}_{[t]} \right) \mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v} \end{equation}\) 再来看递推式,将公式 $\eqref{eq:str}$ 中的 $r$ 应用到整个 chunk,即 $r=C$,则有: \(\begin{equation} \mathbf{S}_{[t+1]} = \mathbf{S}^C_{[t]} = \gamma^C_{[t]} \mathbf{S}_{[t]} + \sum_{i=1}^{C} \left( \frac{\gamma^C_{[t]} }{\gamma^i_{[t]} } v^i_{[t]} k^{i\top}_{[t]} \right) \end{equation}\) 对于第一项,定义:$\overrightarrow{\mathbf{S}_{[t]} } := \gamma^C_{[t]} \mathbf{S}_{[t]}$ ,它用右箭头表示将 chunk $t$ 的状态由起点衰减到终点(chunk 起点到终点的相对累乘)。定义:$\overrightarrow{k^i_{[t]} } := \frac{\gamma^C_{[t]} }{\gamma^i_{[t]} } k^i_{[t]}$ ,它用右箭头表示将该向量衰减到 chunk $t$ 的终点(当前位置 $r$ 到 chunk 终点的相对累乘),其行堆叠为 $\overrightarrow{\mathbf{K}_{[t]} }$ 。类似于公式 $\eqref{eq:vtk}$ 的推导,最终有: \(\begin{equation} \mathbf{S}_{[t+1]} = \overrightarrow{\mathbf{S}_{[t]} } + \mathbf{V}_{[t]}^\top \overrightarrow{\mathbf{K}_{[t]} } \in \mathbb{R}^{d_v \times d_k} \end{equation}\) 综上,带有衰减的线性注意力的 chunkwise 矩阵形式如下:
\(\begin{equation} \mathbf{S}_{[t+1]} = \overrightarrow{\mathbf{S}_{[t]} } + \mathbf{V}_{[t]}^\top \overrightarrow{\mathbf{K}_{[t]} } \in \mathbb{R}^{d_v \times d_k}, \quad \mathbf{O}_{[t]} = \overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}^\top_{[t]} + \left( \mathbf{Q}_{[t]} \mathbf{K}^\top_{[t]} \odot \mathbf{\Gamma}_{[t]} \right) \mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v} \end{equation}\) 这样的矩阵形式进一步方便了并行计算。
(二)Delta Networks: Linear Attention with Delta Rule
1. 基本介绍
Delta 更新规则可以动态的擦除与当前输入 key ($k_t$) 相关联的 value ($v_t^{\text{old} }$),并写入一个新的 value ($v_t^{\text{new} }$)。这个新的 value 是当前输入 value 与 旧 value 基于写入强度(writing strength, $\beta_t \in (0,1)$)的线性组合。 \(\begin{equation} \mathbf{S}_t = \mathbf{S}_{t-1} - \underbrace{(\mathbf{S}_{t-1} k_t)}_{v_t^{\text{old} }} k_t^\top + \underbrace{(\beta_t v_t + (1 - \beta_t) \mathbf{S}_{t-1} k_t)}_{v_t^{\text{new} }} k_t^\top = \mathbf{S}_{t-1} (\mathbf{I} - \beta_t k_t k_t^\top) + \beta_t v_t k_t^\top \end{equation}\) 为什么 $\mathbf{S}_{t-1} k_t$ 就可以认为是 $v_t^{\text{old} }$ ?在 DeltaNet 里,$\mathbf{S} \in \mathbb{R}^{d_v \times d_k}$ 被定义为把 key 映射到 value 的快权重/记忆矩阵,它是一个关联记忆,存储了很多对 $(k_i,v_i)$ 的绑定。在这种记忆表示下,读出操作就是把 key 当做地址去乘状态矩阵: \(\begin{equation} v_t^{\text{old} } = \mathbf{S}_{t-1} k_t = \left( \sum_{i=1}^{t-1} v_i k_i^\top \right) k_t = \sum_{i=1}^{t-1} v_i (k_i^\top k_t) \end{equation}\) 其中,$k_i^\top k_t$ 可以理解为未归一化的相似度,读出的结果是对历史 value 的加权和。因此 $\mathbf{S}_{t-1} k_t$ 的含义就是,用当前 key $k_t$ 去检索旧记忆里与它最相似的几条 value,然后得到一个预测值。它代表在写入前,记忆中对这个 key 的当前内容是什么。
然后它要把与 $k_t$ 相关的那条记忆改写成一个新 value: \(\begin{equation} v_t^{\text{new} } = \beta_t v_t + (1 - \beta_t) v_t^{\text{old} } \end{equation}\) 写入强度 $\beta_t$ 越大,越偏向当前输入 $v_t$ 覆盖;越小,越保留原来的 $v_t^{\text{old} }$ 。然后,对状态矩阵做擦除和写入: \(\begin{equation} \mathbf{S}_t = \mathbf{S}_{t-1} - v_t^{\text{old} } k_t^\top + v_t^{\text{new} } k_t^\top \end{equation}\) 也就是只对 key $k_t$ 对应的那条外积记忆做替换。化简后出现的 $(\mathbf{I} - \beta_t k_t k_t^\top)$ 也被称为一种广义 Householder transition matrix。可以这样理解,假设 $x$ 与 $k_t^\top$ 正交,即 $k_t^\top x=0$,那么就有 $(I - \beta_t k_t k_t^\top)x=x$,也就是说在与当前 key 无关的方向上,旧状态完全不动。
2. Chunkwise Parallel Form
(1)原始递推部分展开
首先,对于原始递归有: \(\begin{equation} \mathbf{S}_t = \mathbf{S}_{t-1} (\mathbf{I} - \beta_t k_t k_t^\top) + \beta_t v_t k_t^\top \end{equation}\)
其中,$\mathbf{S}_t \in \mathbb{R}^{d_v \times d_k}$,$k_t \in \mathbb{R}^{d_k}, v_t \in \mathbb{R}^{d_v}$,$\beta_t \in (0, 1)$。定义两个单步算子: \(\begin{equation} \mathbf{A}_t := \mathbf{I} - \beta_t k_t k_t^\top \in \mathbb{R}^{d_k \times d_k}, \quad \mathbf{B}_t := \beta_t v_t k_t^\top \in \mathbb{R}^{d_v \times d_k} \end{equation}\) 则递推变成更标准的: \(\begin{equation} \mathbf{S}_t = \mathbf{S}_{t-1} \mathbf{A}_t + \mathbf{B}_t \end{equation}\) 然后,我们定义 chunk 内第 $i$ 步有: \(\begin{equation} \mathbf{A}^i_{[t]} := \mathbf{I} - \beta^i_{[t]} k^i_{[t]} k^{i\top}_{[t]}, \quad \mathbf{B}^i_{[t]} := \beta^i_{[t]} v^i_{[t]} k^{i\top}_{[t]} \end{equation}\) 因此,在 chunk 内的递推有: \(\begin{equation} \mathbf{S}^i_{[t]} = \mathbf{S}^{i-1}_{[t]} \mathbf{A}^i_{[t]} + \mathbf{B}^i_{[t]}, \quad \mathbf{S}^0_{[t]} = \mathbf{S}_{[t]} \label{eq:sab} \end{equation}\) 我们可以通过写出前几步来寻找规律,从而写出 $\mathbf{S}^r_{[t]}$ 的部分展开:
- $r = 1$:
- $r = 2$:
- $r = 3$:
因此,对于一般的第 $r$ 步,有: \(\begin{equation} \mathbf{S}^r_{[t]} = \mathbf{S}_{[t]} \left( \prod_{i=1}^{r} \mathbf{A}^i_{[t]} \right) + \sum_{i=1}^{r} \left( \mathbf{B}^i_{[t]} \prod_{j=i+1}^{r} \mathbf{A}^j_{[t]} \right) \end{equation}\) 其中,$i=r$ 时,$\prod_{j=i+1}^{r} \mathbf{A}^j_{[t]}$ 为 $\mathbf{I}$。把 $\mathbf{A}^i_{[t]}$ 和 $\mathbf{B}^i_{[t]}$ 换回去,写成原文中的形式有: \(\begin{equation} \begin{aligned} \mathbf{S}^r_{[t]} &= \mathbf{S}_{[t]} \underbrace{\left( \prod_{i=1}^{r} (\mathbf{I} - \beta^i_{[t]} k^i_{[t]} k^{i\top}_{[t]}) \right)}_{:= \mathbf{P}^r_{[t]} } + \underbrace{\sum_{i=1}^{r} \left( \beta^i_{[t]} v^i_{[t]} k^{i\top}_{[t]} \prod_{j=i+1}^{r} (\mathbf{I} - \beta^j_{[t]} k^j_{[t]} k^{j\top}_{[t]}) \right)}_{:= \mathbf{H}^r_{[t]} } \\ &= \mathbf{S}_{[t]} \mathbf{P}^r_{[t]} + \mathbf{H}^r_{[t]} \end{aligned} \label{eq:sph} \end{equation}\)
上式中 $\mathbf{P}^r_{[t]} \in \mathbb{R}^{d_k \times d_k}$ 是广义 Householder transition matrix 的累乘,只和 ${k^i_{[t]},\beta^i_{[t]}}_{i \leq r}$ 有关,$\mathbf{H}^r_{[t]}$ 是 chunk 内写入贡献,只和 ${v^i_{[t]},k^i_{[t]},\beta^i_{[t]}}$ 有关。
(2)把 $\mathbf{P}^r_{[t]}$ 写为 WY 低秩表示
首先,定义 $\mathbf{P}^0_{[t]}=\mathbf{I}$,对 $\mathbf{P}^r_{[t]}$ 展开有: \(\begin{equation} \begin{aligned} \mathbf{P}^r_{[t]} &= \mathbf{P}^{r-1}_{[t]} (\mathbf{I} - \beta^r_{[t]} k^r_{[t]} k^{r\top}_{[t]}) \\ &= \mathbf{P}^{r-1}_{[t]} - \underbrace{\left( \mathbf{P}^{r-1}_{[t]} (\beta^r_{[t]} k^r_{[t]}) \right)}_{=:w^r_{[t]} } k^{r\top}_{[t]} \\ &= \mathbf{P}^{r-1}_{[t]} - w^r_{[t]}k^{r\top}_{[t]} \\ &= \mathbf{P}^{r-2}_{[t]} - (w^{r-1}_{[t]}k^{r-1\top}_{[t]} + w^r_{[t]}k^{r\top}_{[t]}) \\ & \cdots \\ &= \mathbf{I} - \sum_{i=1}^{r} w^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_k \times d_k} \end{aligned} \end{equation}\) 在上述推导中,我们定义了 $w^r_{[t]} = \mathbf{P}^{r-1}_{[t]} (\beta^r_{[t]} k^r_{[t]}) \in \mathbb{R}^{d_k}$ ,此外,根据上式可写出: \(\begin{equation} \mathbf{P}^{r-1}_{[t]} = \mathbf{I} - \sum_{i=1}^{r-1} w^i_{[t]} k^{i\top}_{[t]} \end{equation}\) 因此得到 $w^r_{[t]}$ 的递推: \(\begin{equation} w^r_{[t]} = \beta^r_{[t]} \mathbf{P}^{r-1}_{[t]} k^r_{[t]} = \beta^r_{[t]} \left( k^r_{[t]} - \sum_{i=1}^{r-1} w^i_{[t]} (k^{i\top}_{[t]} k^r_{[t]}) \right) \in \mathbb{R}^{d_k} \end{equation}\) 且有 $w^1_{[t]} = \beta^1_{[t]} k^1_{[t]}$,综上,我们得到原文中关于 $\mathbf{P}^r_{[t]}$ 的公式: \(\begin{equation} \mathbf{P}^r_{[t]} = \mathbf{I} - \sum_{i=1}^{r} w^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_k \times d_k} , \quad w^r_{[t]} = \beta^r_{[t]} \left( k^r_{[t]} - \sum_{i=1}^{r-1} w^i_{[t]} (k^{i\top}_{[t]} k^r_{[t]}) \right) \in \mathbb{R}^{d_k} \end{equation}\)
写为矩阵形式有: \(\begin{equation} \mathbf{P}_{[t]} = \mathbf{I} - \mathbf{W}^\top_{[t]} \mathbf{K}_{[t]} \in \mathbb{R}^{d_k \times d_k} \end{equation}\)
所谓 WY 低秩表示,大概是把一串 Householder 的乘积,用一个单位矩阵减去低秩项的形式表示出来,从而把逐个相乘的 $O(r)$ 次矩阵相乘,变成便于并行的矩阵运算,这里不深入展开。
(3)把 $\mathbf{H}^r_{[t]}$ 写为低秩表示
同理,定义 $\mathbf{H}^0_{[t]} = \mathbf{0}$,由公式 $\eqref{eq:sab}$ 和公式 $\eqref{eq:sph}$ 可知,任意位置对 chunk 内初始状态有: \(\begin{equation} \mathbf{S}^r_{[t]} = \mathbf{S}_{[t]} \mathbf{P}^r_{[t]} + \mathbf{H}^r_{[t]}, \quad \mathbf{S}^{r-1}_{[t]} = \mathbf{S}_{[t]} \mathbf{P}^{r-1}_{[t]} + \mathbf{H}^{r-1}_{[t]} \end{equation}\) 任意位置对前一个位置有递推: \(\begin{equation} \mathbf{S}^r_{[t]} = \mathbf{S}^{r-1}_{[t]} \mathbf{A}^r_{[t]} + \mathbf{B}^r_{[t]} \end{equation}\) 联合上述三个等式,有: \(\begin{equation} \begin{aligned} \mathbf{S}^r_{[t]} &= \mathbf{S}^{r-1}_{[t]} \mathbf{A}^r_{[t]} + \mathbf{B}^r_{[t]} = \mathbf{S}_{[t]} \mathbf{P}^r_{[t]} + \mathbf{H}^r_{[t]} \\ &= (\mathbf{S}_{[t]} \mathbf{P}^{r-1}_{[t]} + \mathbf{H}^{r-1}_{[t]}) \mathbf{A}^r_{[t]} + \mathbf{B}^r_{[t]} \\ &= \mathbf{S}_{[t]} \mathbf{P}^{r-1}_{[t]} \mathbf{A}^r_{[t]} + \mathbf{H}^{r-1}_{[t]} \mathbf{A}^r_{[t]} + \mathbf{B}^r_{[t]} \end{aligned} \end{equation}\) 我们主要关注上式中的等式关系: \(\begin{equation} \mathbf{S}_{[t]} \mathbf{P}^r_{[t]} + \mathbf{H}^r_{[t]} = \mathbf{S}_{[t]} \mathbf{P}^{r-1}_{[t]} \mathbf{A}^r_{[t]} + \mathbf{H}^{r-1}_{[t]} \mathbf{A}^r_{[t]} + \mathbf{B}^r_{[t]} \end{equation}\) 为了让该等式对初始状态 $\mathbf{S}_{[t]}$ 成立,应当有: \(\begin{align} \mathbf{P}^r_{[t]} &= \mathbf{P}^{r-1}_{[t]} \mathbf{A}^r_{[t]} \label{eq:p}\\ \mathbf{H}^r_{[t]} &= \mathbf{H}^{r-1}_{[t]} \mathbf{A}^r_{[t]} + \mathbf{B}^r_{[t]} \label{eq:h} \end{align}\) 其中,公式 $\eqref{eq:p}$ 就是我们在上一小节中推导的部分,本小节我们关注的是公式 $\eqref{eq:h}$。将 $\mathbf{A}^r_{[t]},\mathbf{B}^r_{[t]}$ 的原始表达代入,就得到 $\mathbf{H}^r_{[t]}$ 的递推: \(\begin{equation} \begin{aligned} \mathbf{H}^r_{[t]} &= \mathbf{H}^{r-1}_{[t]} (\mathbf{I} - \beta^r_{[t]} k^r_{[t]} k^{r\top}_{[t]}) + \beta^r_{[t]} v^r_{[t]} k^{r\top}_{[t]} \\ &= \mathbf{H}^{r-1}_{[t]} - (\mathbf{H}^{r-1}_{[t]} \beta^r_{[t]} k^r_{[t]}) k^{r\top}_{[t]} + \beta^r_{[t]} v^r_{[t]} k^{r\top}_{[t]} \end{aligned} \end{equation}\) 令: \(\begin{equation} u^r_{[t]} := \beta^r_{[t]} v^r_{[t]} - \mathbf{H}^{r-1}_{[t]} \beta^r_{[t]} k^r_{[t]} \end{equation}\) 则: \(\begin{equation} \mathbf{H}^r_{[t]} = \mathbf{H}^{r-1}_{[t]} + u^r_{[t]} k^{r\top}_{[t]} \Rightarrow \mathbf{H}^r_{[t]} = \sum_{i=1}^{r} u^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_v \times d_k} \end{equation}\) 下面推导 $u^r_{[t]}$ 递推。根据上述结果,有: \(\begin{equation} \mathbf{H}^{r-1}_{[t]} = \sum_{i=1}^{r-1} u^i_{[t]} k^{i\top}_{[t]} \end{equation}\) 两边同乘 $\beta^r_{[t]} k^r_{[t]}$ 后得到: \(\begin{equation} \mathbf{H}^{r-1}_{[t]} \beta^r_{[t]} k^r_{[t]} = \beta^r_{[t]} \sum_{i=1}^{r-1} u^i_{[t]} (k^{i\top}_{[t]} k^r_{[t]}) \end{equation}\) 结合 $u^r_{[t]}$ 定义,可得: \(\begin{equation} u^r_{[t]} = \beta^r_{[t]} \left( v^r_{[t]} - \sum_{i=1}^{r-1} u^i_{[t]} (k^{i\top}_{[t]} k^r_{[t]}) \right) \in \mathbb{R}^{d_v} \end{equation}\) 综上,我们得到原文中关于 $\mathbf{H}^r_{[t]}$ 的公式: \(\begin{equation} \mathbf{H}^r_{[t]} = \sum_{i=1}^{r} u^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_v \times d_k}, \quad u^r_{[t]} = \beta^r_{[t]} \left( v^r_{[t]} - \sum_{i=1}^{r-1} u^i_{[t]} (k^{i\top}_{[t]} k^r_{[t]}) \right) \in \mathbb{R}^{d_v} \end{equation}\) 写成矩阵形式则有: \(\begin{equation} \mathbf{H}_{[t]} = \mathbf{U}^\top_{[t]} \mathbf{K}_{[t]} \in \mathbb{R}^{d_v \times d_k} \end{equation}\)
(4)把 $w^r_{[t]},u^r_{[t]}$ 的递推写成矩阵形式
首先回顾一下之前的所有推导结果: \(\begin{equation} \begin{aligned} \mathbf{S}^r_{[t]} &= \mathbf{S}_{[t]} \underbrace{\left( \prod_{i=1}^{r} (\mathbf{I} - \beta^i_{[t]} k^i_{[t]} k^{i\top}_{[t]}) \right)}_{:= \mathbf{P}^r_{[t]} } + \underbrace{\sum_{i=1}^{r} \left( \beta^i_{[t]} v^i_{[t]} k^{i\top}_{[t]} \prod_{j=i+1}^{r} (\mathbf{I} - \beta^j_{[t]} k^j_{[t]} k^{j\top}_{[t]}) \right)}_{:= \mathbf{H}^r_{[t]} } \\ &= \mathbf{S}_{[t]} \mathbf{P}^r_{[t]} + \mathbf{H}^r_{[t]} \\ \end{aligned} \end{equation}\)
\[\begin{equation} \mathbf{P}^r_{[t]} = \mathbf{I} - \sum_{i=1}^{r} w^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_k \times d_k} , \quad w^r_{[t]} = \beta^r_{[t]} \left( k^r_{[t]} - \sum_{i=1}^{r-1} w^i_{[t]} (k^{i\top}_{[t]} k^r_{[t]}) \right) \in \mathbb{R}^{d_k} \end{equation}\] \[\begin{equation} \mathbf{H}^r_{[t]} = \sum_{i=1}^{r} u^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_v \times d_k}, \quad u^r_{[t]} = \beta^r_{[t]} \left( v^r_{[t]} - \sum_{i=1}^{r-1} u^i_{[t]} (k^{i\top}_{[t]} k^r_{[t]}) \right) \in \mathbb{R}^{d_v} \end{equation}\] \[\begin{equation} \mathbf{P}_{[t]} = \mathbf{I} - \mathbf{W}^\top_{[t]} \mathbf{K}_{[t]} \in \mathbb{R}^{d_k \times d_k}, \quad \mathbf{H}_{[t]} = \mathbf{U}^\top_{[t]} \mathbf{K}_{[t]} \in \mathbb{R}^{d_v \times d_k} \end{equation}\]这一步,我们希望得到 $\mathbf{W}_{[t]}$ 与 $\mathbf{U}_{[t]}$ 的具体矩阵推导。首先,我们把 chunk 内所有 $k^r_{[t]}, v^r_{[t]}$ 按行堆叠成: \(\begin{equation} \mathbf{K}_{[t]} \in \mathbb{R}^{C \times d_k}, \quad \mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v} \end{equation}\) 把 $w^r_{[t]}, u^r_{[t]}$ 也按行堆叠: \(\begin{equation} \mathbf{W}_{[t]} \in \mathbb{R}^{C \times d_k}, \quad \mathbf{U}_{[t]} \in \mathbb{R}^{C \times d_v} \end{equation}\) 由 $w^r_{[t]}$ 的递推公式,将右边的求和放至等式左边,有: \(\begin{equation} w^r_{[t]} + \sum_{i=1}^{r-1} (\beta^r_{[t]} k^{i\top}_{[t]} k^r_{[t]}) w^i_{[t]} = \beta^r_{[t]} k^r_{[t]} \end{equation}\)
观察上式,左侧是从 $i=1$ 到 $i=r$ 的 $w^i_{[t]}$ 的累加,其中,$i < r$ 时,$w^i_{[t]}$ 前有系数 $\beta^r_{[t]} k^{i\top}_{[t]} k^r_{[t]}$ ,$i=r$ 时,$w^i_{[t]}$ 的系数为 1。把 $r=1,2, \ldots, C$ 全部堆起来,可以写成一个下三角矩阵×未知矩阵=已知矩阵的形式,即: \(\begin{equation} \begin{bmatrix} 1 & 0 & 0 & \cdots & 0 \\ \beta^2_{[t]} k^{1\top}_{[t]} k^2_{[t]} & 1 & 0 & \cdots & 0 \\ \beta^3_{[t]} k^{1\top}_{[t]} k^3_{[t]} & \beta^3_{[t]} k^{2\top}_{[t]} k^3_{[t]} & 1 & \cdots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \beta^C_{[t]} k^{1\top}_{[t]} k^C_{[t]} & \beta^C_{[t]} k^{2\top}_{[t]} k^C_{[t]} & \beta^C_{[t]} k^{3\top}_{[t]} k^C_{[t]} & \cdots & 1 \end{bmatrix} \begin{bmatrix} w^{1\top}_{[t]} \\ w^{2\top}_{[t]} \\ w^{3\top}_{[t]} \\ \vdots \\ w^{C\top}_{[t]} \end{bmatrix} = \begin{bmatrix} \beta^1_{[t]} & & & & \\ & \beta^2_{[t]} & & & \\ & & \beta^3_{[t]} & & \\ & & & \ddots & \\ & & & & \beta^C_{[t]} \end{bmatrix} \begin{bmatrix} k^{1\top}_{[t]} \\ k^{2\top}_{[t]} \\ k^{3\top}_{[t]} \\ \vdots \\ k^{C\top}_{[t]} \end{bmatrix} \end{equation}\) 其中,定义对角阵 $\mathbf{D}_{[t]} = \text{diag}(\beta^1_{[t]}, \ldots, \beta^C_{[t]}) \in \mathbb{R}^{C \times C}$,定义下三角系数矩阵: \(\begin{equation} \mathbf{L}_{[t]} = \begin{cases} \beta^r_{[t]} k^{i\top}_{[t]} k^r_{[t]}, & i < r \\ 0, & i \geq r \end{cases} \end{equation}\) 该矩阵是严格的下三角矩阵,因此上式可以写为: \(\begin{equation} (\mathbf{I} + \mathbf{L}_{[t]}) \mathbf{W}_{[t]} = \mathbf{D}_{[t]} \mathbf{K}_{[t]} \end{equation}\) 其中,$\mathbf{I} + \mathbf{L}_{[t]}$ 是单位下三角矩阵,对角线全为 1,必定可逆,因此有: \(\begin{equation} \mathbf{W}_{[t]} = (\mathbf{I} + \mathbf{L}_{[t]})^{-1} \mathbf{D}_{[t]} \mathbf{K}_{[t]} \end{equation}\) 原文中,将 $\mathbf{L}_{[t]}$ 写为: \(\begin{equation} \mathbf{L}_{[t]} = \text{strictLower}(\mathbf{D_{[t]} } \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \end{equation}\) 并进一步定义 $\mathbf{T}_{[t]}$ 为: \(\begin{equation} \mathbf{T}_{[t]} = (\mathbf{I} + \mathbf{L}_{[t]})^{-1} \mathbf{D}_{[t]} \in \mathbb{R}^{C \times C} \end{equation}\) 于是就得到: \(\begin{equation} \mathbf{W}_{[t]} = \mathbf{T}_{[t]} \mathbf{K}_{[t]} \in \mathbb{R}^{C \times d_k} \label{eq:wtk} \end{equation}\) 类似的,可以得到: \(\begin{equation} \mathbf{U}_{[t]} = \mathbf{T}_{[t]} \mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v} \label{eq:utv} \end{equation}\) 最后,根据: \(\begin{align} \mathbf{S}_{[t+1]} &= \mathbf{S}_{[t]} \mathbf{P}_{[t]} + \mathbf{H}_{[t]} \\ \mathbf{P}_{[t]} &= \mathbf{I} - \mathbf{W}_{[t]}^\top \mathbf{K}_{[t]} \\ \mathbf{H}_{[t]} &= \mathbf{U}_{[t]}^\top \mathbf{K}_{[t]} \end{align}\) 代入可得: \(\begin{equation} \mathbf{S}_{[t+1]} = \mathbf{S}_{[t]} (\mathbf{I} - \mathbf{W}^\top_{[t]} \mathbf{K}_{[t]}) + \mathbf{U}^\top_{[t]} \mathbf{K}_{[t]} = \mathbf{S}_{[t]} + \left(\mathbf{U}_{[t]} - \mathbf{W}_{[t]} \mathbf{S}^\top_{[t]} \right)^\top \mathbf{K}_{[t]} \in \mathbb{R}^{d_v \times d_k} \end{equation}\) 其中 $\mathbf{W}_{[t]}$ 和 $\mathbf{U}_{[t]}$ 可由公式 $\eqref{eq:wtk}$ 和公式 $\eqref{eq:utv}$ 求得,我们可以将 $(\mathbf{U}_{[t]} - \mathbf{W}_{[t]} \mathbf{S}^\top_{[t]})$ 视为等效块内 value,类似于公式 $\eqref{eq:chunk}$,可以快速写出最终的输出为: \(\begin{equation} \mathbf{O}_{[t]} = \mathbf{Q}_{[t]} \mathbf{S}_{[t]}^\top + \left( \mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top \odot \mathbf{M} \right) \left( \mathbf{U}_{[t]} - \mathbf{W}_{[t]} \mathbf{S}_{[t]}^\top \right) \in \mathbb{R}^{C \times d_o} \end{equation}\)
二、Gated Delta Networks
(一)Gated Delta Rule
1. 基本介绍
本文提出的 gated delta rule 简单但有效: \(\begin{equation} \mathbf{S}_t = \mathbf{S}_{t-1} (\alpha_t (\mathbf{I} - \beta_t k_t k_t^\top)) + \beta_t v_t k_t^\top \label{eq:gated_delta_net} \end{equation}\) 其中,数据依赖的门控项 $\alpha_t \in (0,1)$ 控制状态衰减。这种公式化表达融合了门控机制和增量规则的优势:门控项能够实现自适应的记忆管理,而增量更新结构则有助于高效的键值关联学习。
从在线学习的角度来看:根据 Liu 等人的在线学习框架,递归状态更新是在线学习问题的闭式解。所谓在线学习问题,可以理解为:数据一条一条到来,边看边更新,不允许回头多轮迭代,也不知道未来会来什么。在这类框架里,常见的建模方式不是直接沿着梯度走一步,而是就地解一个优化问题: \(\begin{equation} \mathbf{S}_t = \arg\min_{\mathbf{S}_t} \underbrace{\|\mathbf{S}_t - \alpha_t \mathbf{S}_{t-1}\|_F^2}_{\text{正则:别离上一步太远} } + \underbrace{(\text{当前样本驱动的拟合项})}_{\text{让 } \mathbf{S}_t \text{ 在 } k_t \text{ 上更像 } v_t} \end{equation}\) 以 Linear Attention (LA) 为例,它对应的在线学习目标可以写成: \(\begin{equation} \min_{\mathbf{S}_t} \|\mathbf{S}_t - \mathbf{S}_{t-1}\|_F^2 - 2\langle \mathbf{S}_t k_t, v_t \rangle \end{equation}\) 而它的最优解就是: \(\begin{equation} \mathbf{S}_t = \mathbf{S}_{t-1} + v_t k_t^\top \end{equation}\) 每种方法的优化目标和闭式解如下图所示,这里我们不过分纠结每种方法的数学表达,只是借此来分析 gated delta rule。如下图所示,线性 RNN 架构通常会在在线学习目标中加入正则化项,用于防止状态偏离先前的值,从而实现记忆保留。然而,当状态中充斥过多信息时,这种保留机制就会出现问题。在这种情况下,每个状态都会编码多个信息片段的叠加,导致精确检索变得困难。为解决这一局限性,Mamba2 和 Gated DeltaNet 中引入了一个自适应缩放因子 $\alpha_t$,它可以放宽正则化项,允许 $\mathbf{S}_t$ 和 $\mathbf{S}_{t-1}$ 之间存在可控的偏差。这种修改通过选择性遗忘实现了动态记忆管理,有助于过滤无关信息。

另一方面,LA 和 Mamba2 使用简单的负内积损失 $- \langle \mathbf{S}_t k_t, v_t \rangle$ 来建模键值关联,Longhorn 则使用更具表现力的 $|\mathbf{S}_t k_t - v_t|^2$ ,强调精确拟合 key-value 关联,由此产生的更新规则与 (Gated) DeltaNet 的更新规则非常相似,这表明在它们具有更加精确的关联学习能力。
从测试时 SGD 的角度来看:可以把状态矩阵 $\mathbf{S}$ 看成一个 fast weight matrix,即类似于一个临时权重或快速权重,在序列内部不断被更新,用来实现键值映射。在这个视角下,当时间步 $t$ 到来时,应满足: \(\begin{equation} \mathbf{S}_t k_t \approx v_t \end{equation}\) 这是一个在线回归问题,即数据一条条到来,边看边拟合一个回归模型,它的回归损失是: \(\begin{equation} \mathcal{L}(\mathbf{S}_t)=\frac{1}{2}\|\mathbf{S}_t k_t − v_t\|^2 \end{equation}\) 即用当前 key 的 $k_t$ 经过矩阵 $\mathbf{S}_t$ 的预测值 $\mathbf{S}_t k_t$ 去拟合目标 value $v_t$ ,它的梯度推导如下:
首先写成分量形式: \(\begin{equation} \mathcal{L} = \frac{1}{2} \sum_{i=1}^{d_v} \left( \sum_{j=1}^{d_k} \mathbf{S}_{ij} k_j - v_i \right)^2 \end{equation}\) 对某个元素 $\mathbf{S}_{ab}$ 求偏导: \(\begin{equation} \frac{\partial \mathcal{L} }{\partial \mathbf{S}_{ab} } = \sum_{i=1}^{d_v} \left( \sum_j \mathbf{S}_{ij} k_j - v_i \right) \cdot \frac{\partial}{\partial \mathbf{S}_{ab} } \left( \sum_j \mathbf{S}_{ij} k_j - v_i \right) \end{equation}\) 只有当 $i = a$ 时会依赖 $\mathbf{S}_{ab}$,且导数是 $k_b$ ($j=b$ 时),所以: \(\begin{equation} \frac{\partial \mathcal{L} }{\partial \mathbf{S}_{ab} } = (\mathbf{S} k - v)_a k_b \end{equation}\) 将所有 $(a, b)$ 对应的偏导组合成矩阵形式,即得: \(\begin{equation} \nabla_\mathbf{S} \mathcal{L} = (\mathbf{S} k - v) k^\top \end{equation}\) 因此,对上述在线回归做一步 SGD 有: \(\begin{equation} \mathbf{S}_{t+1} = \mathbf{S}_t - \beta_t \nabla \mathcal{L}(\mathbf{S}_t) = \mathbf{S}_t - \beta_t (\mathbf{S}_t k_t - v_t) k_t^\top = \mathbf{S}_t (\mathbf{I} - \beta_t k_t k_t^\top) + \beta_t v_t k_t^\top \end{equation}\) 这正是 delta rule 的更新式,因此这里 $\beta_t$ 可以被解释为 (adaptive) learning rate,Gated delta rule 等价于在这一步 SGD 里加入自适应的 weight decay ($\alpha_t$)。
2. Hardware-Efficient Chunkwise Training
(1)原始递推部分展开
首先将 Gated Delta Networks 的递推公式 $\eqref{eq:gated_delta_net}$ 也进行部分展开,其过程与公式 $\eqref{eq:sph}$ 类似,相当于只是在 $(\mathbf{I} - \beta^i_{[t]} k^i_{[t]} k^{i\top}_{[t]})$ 前多乘了一个 $\alpha^i_{[t]}$,我们直接写出其展开为: \(\begin{equation} \begin{aligned} \mathbf{S}_{[t]}^r &= \mathbf{S}_{[t]} \underbrace{\left( \prod_{i=1}^{r} \alpha_{[t]}^i \left( \mathbf{I} - \beta_{[t]}^i k_{[t]}^i k_{[t]}^{i\top} \right) \right)}_{:= \mathbf{F}_{[t]}^r} + \underbrace{\sum_{i=1}^{r} \left( \beta_{[t]}^i v_{[t]}^i k_{[t]}^{i\top} \prod_{j=i+1}^{r} \alpha_{[t]}^j \left( \mathbf{I} - \beta_{[t]}^j k_{[t]}^j k_{[t]}^{j\top} \right) \right)}_{:= \mathbf{G}_{[t]}^r} \\ &= \mathbf{S}_{[t]} \mathbf{F}_{[t]}^r + \mathbf{G}_{[t]}^r \end{aligned} \end{equation}\)
(2)低秩表示
对于 $\mathbf{F}_{[t]}^r$,其中的 $\alpha_{[t]}^i$ 是标量,可提到最外层: \(\begin{equation} \begin{aligned} \mathbf{F}_{[t]}^r &= \left( \prod_{i=1}^{r} \alpha_{[t]}^i \right) \left( \prod_{i=1}^{r} \left( \mathbf{I} - \beta_{[t]}^i k_{[t]}^i k_{[t]}^{i\top} \right) \right) \\ &= \gamma_{[t]}^r \mathbf{P}_{[t]}^r = \overleftarrow{\mathbf{P}_{[t]}^r} \end{aligned} \end{equation}\) 其中,$\gamma_{[t]}^r$ 代表 chunk 内从起点到位置 $r$ 的累计衰减,$\overleftarrow{\mathbf{P}_{[t]}^r}$ 表示将 $\mathbf{P}_{[t]}^r$ 衰减到 chunk 起点。
对于 $\mathbf{G}_{[t]}^r$,略微麻烦一些。先前在 Delta Network 部分中,我们定义了 $\mathbf{A}^i_{[t]} := \mathbf{I} - \beta^i_{[t]} k^i_{[t]} k^{i\top}_{[t]}$,Gated Delta Network 相比其多了衰减 $\alpha^i_{[t]}$,我们不妨将其吸收到 $\mathbf{A}^i_{[t]}$,定义 $\widetilde{\mathbf{A}^i_{[t]} } := \alpha^i_{[t]} (\mathbf{I} - \beta^i_{[t]} k^i_{[t]} k^{i\top}_{[t]})$,遵循与 $\mathbf{H}^r_{[t]}$ 相同的推导,可以很快得到与公式 $\eqref{eq:h}$ 类似的结果: \(\begin{equation} \mathbf{G}^r_{[t]} = \mathbf{G}^{r-1}_{[t]} \widetilde{\mathbf{A}^r_{[t]} } + \mathbf{B}^r_{[t]} \end{equation}\) 将 $\widetilde{\mathbf{A}^r_{[t]} }$ 与 $\mathbf{B}^r_{[t]}$ 得到: \(\begin{equation} \begin{aligned} \mathbf{G}^r_{[t]} &= \alpha^r_{[t]} \mathbf{G}^{r-1}_{[t]} (\mathbf{I} - \beta^r_{[t]} k^r_{[t]} k^{r\top}_{[t]}) + \beta^r_{[t]} v^r_{[t]} k^{r\top}_{[t]} \\ &= \alpha^r_{[t]} \mathbf{G}^{r-1}_{[t]} - (\alpha^r_{[t]} \mathbf{G}^{r-1}_{[t]} \beta^r_{[t]} k^r_{[t]}) k^{r\top}_{[t]} + \beta^r_{[t]} v^r_{[t]} k^{r\top}_{[t]} \end{aligned} \end{equation}\) 令: \(\begin{equation} \tilde{u}^r_{[t]} := \beta^r_{[t]} v^r_{[t]} - \alpha^r_{[t]} \mathbf{G}^{r-1}_{[t]} \beta^r_{[t]} k^r_{[t]} \end{equation}\) 则: \(\begin{equation} \mathbf{G}^r_{[t]} = \alpha^r_{[t]} \mathbf{G}^{r-1}_{[t]} + \tilde{u}^r_{[t]} k^{r\top}_{[t]} \Rightarrow \mathbf{G}^r_{[t]} = \sum_{i=1}^{r} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } \tilde{u}^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_v \times d_k} \end{equation}\) 与 Delta Network 部分中 $u^r_{[t]}$ 的递推类似,我们也能很快得到 $\tilde{u}^r_{[t]}$ 的递推为: \(\begin{equation} \tilde{u}^r_{[t]} = \beta^r_{[t]} \left( v^r_{[t]} - \sum_{i=1}^{r-1} \tilde{u}^i_{[t]} (\frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } k^{i\top}_{[t]} k^r_{[t]}) \right) \in \mathbb{R}^{d_v} \end{equation}\)
(3)写为矩阵形式
类似于 Delta Network 部分中的推导,我们将上式写为: \(\begin{equation} \tilde{u}^r_{[t]} + \sum_{i=1}^{r-1} \tilde{u}^i_{[t]} (\beta^r_{[t]} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } k^{i\top}_{[t]} k^r_{[t]}) = \beta^r_{[t]} v^r_{[t]} \end{equation}\) 左侧是从 $i=1$ 到 $i=r$ 的 $\tilde{u}^i_{[t]}$ 的累加,其中,$i < r$ 时,$\tilde{u}^i_{[t]}$ 前有系数 $\beta^r_{[t]} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } k^{i\top}_{[t]} k^r_{[t]}$ ,$i=r$ 时,$\tilde{u}^i_{[t]}$ 的系数为 1。把 $r=1,2, \ldots, C$ 全部堆起来,可以写成一个下三角矩阵×未知矩阵=已知矩阵的形式,即: \(\begin{equation} \begin{bmatrix} 1 & 0 & 0 & \cdots & 0 \\ \beta^2_{[t]} \frac{\gamma^2_{[t]} }{\gamma^1_{[t]} } k^{1\top}_{[t]} k^2_{[t]} & 1 & 0 & \cdots & 0 \\ \beta^3_{[t]} \frac{\gamma^3_{[t]} }{\gamma^1_{[t]} } k^{1\top}_{[t]} k^3_{[t]} & \beta^3_{[t]} \frac{\gamma^3_{[t]} }{\gamma^2_{[t]} } k^{2\top}_{[t]} k^3_{[t]} & 1 & \cdots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \beta^C_{[t]} \frac{\gamma^C_{[t]} }{\gamma^1_{[t]} } k^{1\top}_{[t]} k^C_{[t]} & \beta^C_{[t]} \frac{\gamma^C_{[t]} }{\gamma^2_{[t]} } k^{2\top}_{[t]} k^C_{[t]} & \beta^C_{[t]} \frac{\gamma^C_{[t]} }{\gamma^3_{[t]} } k^{3\top}_{[t]} k^C_{[t]} & \cdots & 1 \end{bmatrix} \begin{bmatrix} \tilde{u}^{1\top}_{[t]} \\ \tilde{u}^{2\top}_{[t]} \\ \tilde{u}^{3\top}_{[t]} \\ \vdots \\ \tilde{u}^{C\top}_{[t]} \end{bmatrix} = \begin{bmatrix} \beta^1_{[t]} & & & & \\ & \beta^2_{[t]} & & & \\ & & \beta^3_{[t]} & & \\ & & & \ddots & \\ & & & & \beta^C_{[t]} \end{bmatrix} \begin{bmatrix} v^{1\top}_{[t]} \\ v^{2\top}_{[t]} \\ v^{3\top}_{[t]} \\ \vdots \\ v^{C\top}_{[t]} \end{bmatrix} \end{equation}\) 同样定义对角阵 $\mathbf{D}_{[t]} = \text{diag}(\beta^1_{[t]}, \ldots, \beta^C_{[t]}) \in \mathbb{R}^{C \times C}$,定义下三角衰减比值矩阵: \(\begin{equation} \mathbf{\Gamma}_{[t]} = \begin{cases} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} }, & i \leq r \\ 0, & i > r \end{cases} \end{equation}\) 因此整个下三角部分可以写为: \(\begin{equation} \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \end{equation}\) 故上述等式可以写为: \(\begin{equation} \left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right] \widetilde{\mathbf{U}_{[t]} } = \text{diag}(\beta_{[t]}) \mathbf{V}_{[t]} \end{equation}\) 求解得到: \(\begin{equation} \widetilde{\mathbf{U}_{[t]} } = \left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v} \end{equation}\)
接下来我们推导最终矩阵形式的输出,之前我们得到 $\mathbf{G}^r_{[t]} = \sum_{i=1}^{r} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } \tilde{u}^i_{[t]} k^{i\top}_{[t]} \in \mathbb{R}^{d_v \times d_k}$,则: \(\begin{equation} \begin{aligned} \mathbf{G}_{[t]} &= \sum_{i=1}^{C} \tilde{u}^i_{[t]} \frac{\gamma^C_{[t]} }{\gamma^i_{[t]} } k^{i\top}_{[t]} \\ &= \sum_{i=1}^{C} \tilde{u}^i_{[t]} \overrightarrow{k^{i\top}_{[t]} } \\ &= \widetilde{\mathbf{U}_{[t]} }^\top \overrightarrow{\mathbf{K}_{[t]} } \in \mathbb{R}^{d_v \times d_k} \end{aligned} \end{equation}\) 其中,$\overrightarrow{k^i_{[t]} } = \frac{\gamma^C_{[t]} }{\gamma^i_{[t]} } k^i_{[t]}$,代表将 $k^i_{[t]}$ 从位置 $i$ 衰减到 chunk 终点。由此,我们有: \(\begin{align} \mathbf{S}_{[t+1]} &= \mathbf{S}_{[t]} \mathbf{F}_{[t]} + \mathbf{G}_{[t]} \\ \mathbf{F}_{[t]} &= \gamma_{[t]}^C \mathbf{P}_{[t]} = \gamma_{[t]}^C (\mathbf{I} - \mathbf{W}_{[t]}^\top \mathbf{K}_{[t]}) \\ \mathbf{G}_{[t]} &= \widetilde{\mathbf{U}_{[t]} }^\top \overrightarrow{\mathbf{K}_{[t]} } \end{align}\) 为了整合代入得到 chunk 递推,我们还需要弄清 $\overrightarrow{\mathbf{K}_{[t]} }$ 与 $\mathbf{K}_{[t]}$ 的关系,$\overrightarrow{\mathbf{K}_{[t]} }$ 是吸收了 $\frac{\gamma^C_{[t]} }{\gamma^i_{[t]} }$ 后的 $\mathbf{K}_{[t]}$,即: \(\begin{equation} \begin{aligned} \overrightarrow{\mathbf{K}_{[t]} } &= \left[ \frac{\gamma^C_{[t]} }{\gamma^1_{[t]} } k^{1\top}_{[t]}, \frac{\gamma^C_{[t]} }{\gamma^2_{[t]} } k^{2\top}_{[t]}, \ldots, \frac{\gamma^C_{[t]} }{\gamma^C_{[t]} } k^{C\top}_{[t]} \right]^\top \\ &= \begin{bmatrix} \frac{\gamma^C_{[t]} }{\gamma^1_{[t]} } & & & \\ & \frac{\gamma^C_{[t]} }{\gamma^2_{[t]} } & & \\ & & \ddots & \\ & & & \frac{\gamma^C_{[t]} }{\gamma^C_{[t]} } \end{bmatrix} \begin{bmatrix} k^{1\top}_{[t]} \\ k^{2\top}_{[t]} \\ \vdots \\ k^{C\top}_{[t]} \end{bmatrix} \\ &= \text{diag}(\frac{\gamma^C_{[t]} }{\gamma^i_{[t]} }) \mathbf{K}_{[t]} \end{aligned} \end{equation}\) 此外,也可轻易得到: \(\begin{equation} \mathbf{K}_{[t]} = \text{diag}(\frac{\gamma^i_{[t]} }{\gamma^C_{[t]} }) \overrightarrow{\mathbf{K}_{[t]} } \end{equation}\) 得到这个关系之后,我们便可以代入求得 chunk 递推: \(\begin{equation} \begin{aligned} \mathbf{S}_{[t+1]} &= \mathbf{S}_{[t]} \gamma_{[t]}^C \left( \mathbf{I} - \mathbf{W}_{[t]}^\top \mathbf{K}_{[t]} \right) + \widetilde{\mathbf{U}_{[t]} }^\top \overrightarrow{\mathbf{K}_{[t]} } \\ &= \mathbf{S}_{[t]} \gamma_{[t]}^C \left( \mathbf{I} - \mathbf{W}_{[t]}^\top \text{diag}(\frac{\gamma^i_{[t]} }{\gamma^C_{[t]} }) \overrightarrow{\mathbf{K}_{[t]} } \right) + \widetilde{\mathbf{U}_{[t]} }^\top \overrightarrow{\mathbf{K}_{[t]} } \\ &= \gamma_{[t]}^C \mathbf{S}_{[t]} + \left( \widetilde{\mathbf{U}_{[t]} }^\top - \mathbf{S}_{[t]} \mathbf{W}_{[t]}^\top \text{diag}(\gamma^i_{[t]}) \right) \overrightarrow{\mathbf{K}_{[t]} } \\ &= \overrightarrow{\mathbf{S}_{[t]} } + \left( \widetilde{\mathbf{U}_{[t]} } - \text{diag}(\gamma^i_{[t]}) \mathbf{W}_{[t]} \mathbf{S}_{[t]}^\top \right)^\top \overrightarrow{\mathbf{K}_{[t]} } \\ & = \overrightarrow{\mathbf{S}_{[t]} } + \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right)^\top \overrightarrow{\mathbf{K}_{[t]} } \in \mathbb{R}^{d_v \times d_k} \end{aligned} \end{equation}\) 其中:
- $\overrightarrow{\mathbf{S}_{[t]} } = \gamma_{[t]}^C \mathbf{S}_{[t]}$
- $\overleftarrow{w^r_{[t]} } = \gamma^r_{[t]} w^r_{[t]}$,堆叠后则为 $\overleftarrow{\mathbf{W}_{[t]} } = \text{diag}(\gamma^i_{[t]}) \mathbf{W}_{[t]}$
- $\left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right)$ 同样可以视为等效 value
上式是通过设定 $r=C$ ,即从 chunk 起点到终点的直接推导,对于一般的位置 $r$ 有: \(\begin{equation} \begin{aligned} \mathbf{S}^r_{[t]} &= \mathbf{S}_{[t]} \mathbf{F}_{[t]}^r + \mathbf{G}_{[t]}^r \\ &= \mathbf{S}_{[t]} \gamma_{[t]}^r \mathbf{P}_{[t]}^r + \mathbf{G}_{[t]}^r \\ & = \mathbf{S}_{[t]} \gamma_{[t]}^r \left( \mathbf{I} - \sum_{i=1}^{r} w^i_{[t]} k^{i\top}_{[t]} \right) + \sum_{i=1}^{r} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } \tilde{u}^i_{[t]} k^{i\top}_{[t]} \\ &= \mathbf{S}_{[t]} \gamma_{[t]}^r + \left( \sum_{i=1}^{r} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } \tilde{u}^i_{[t]} k^{i\top}_{[t]} - \mathbf{S}_{[t]} \sum_{i=1}^{r} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } \gamma^i_{[t]} w^i_{[t]} k^{i\top}_{[t]} \right) \\ &= \mathbf{S}_{[t]} \gamma_{[t]}^r + \sum_{i=1}^{r} \left( \tilde{u}^i_{[t]} - \mathbf{S}_{[t]}\gamma^i_{[t]} w^i_{[t]} \right) \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } k^{i\top}_{[t]} \end{aligned} \end{equation}\) 对于该位置的输出 $o^r_{[t]}$,有: \(\begin{equation} \begin{aligned} o^r_{[t]} &= \mathbf{S}^r_{[t]} q^r_{[t]} \in \mathbb{R}^{d_v} \\ &= \mathbf{S}_{[t]} \gamma_{[t]}^r q^r_{[t]} + \sum_{i=1}^{r} \left( \tilde{u}^i_{[t]} - \mathbf{S}_{[t]}\gamma^i_{[t]} w^i_{[t]} \right) \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } k^{i\top}_{[t]} q^r_{[t]} \\ &= \mathbf{S}_{[t]} \overleftarrow{q^r_{[t]} } + \sum_{i=1}^{r} \left( \tilde{u}^i_{[t]} - \mathbf{S}_{[t]} \overleftarrow{w^i_{[t]} } \right) \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} } k^{i\top}_{[t]} q^r_{[t]} \end{aligned} \end{equation}\) 其中,$\left( \tilde{u}^i_{[t]} - \mathbf{S}_{[t]} \overleftarrow{w^i_{[t]} } \right)$ 即等效 value,$q^r_{[t]}$ 只关注 $r$ 之前的 $k^{i\top}_{[t]}$ 和等效 value,因此,通过将整个 $r=1,2,\ldots,C$ 堆叠,可得到 chunk 的输出为: \(\begin{equation} \mathbf{O}_{[t]} = \overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}_{[t]}^\top + \left( \mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top \odot \mathbf{\Gamma} \right) \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right) \in \mathbb{R}^{C \times d_v} \end{equation}\)
这里的 mask 原文写的是 $\mathbf{M}$,但是经过我们的推导,结合原文仓库、Qwen3-Next代码实现来看,这里确实应该是 decay mask $\mathbf{\Gamma}$。详见原文仓库中的:代码链接
(4)整理
最后,我们将 Gated Delta Network 的 chunkwise training 所推导的公式总结一下: \(\begin{align} \mathbf{S}_{[t+1]} &= \overrightarrow{\mathbf{S}_{[t]} } + \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right)^\top \overrightarrow{\mathbf{K}_{[t]} } &\in \mathbb{R}^{d_v \times d_k} \\ \mathbf{O}_{[t]} &= \overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}_{[t]}^\top + \left( \mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top \odot \mathbf{\Gamma} \right) \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right) &\in \mathbb{R}^{C \times d_v} \\ \widetilde{\mathbf{U}_{[t]} } &= \left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{V}_{[t]} &\in \mathbb{R}^{C \times d_v} \\ \mathbf{\Gamma}_{[t]} &= \begin{cases} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} }, & i \leq r \\ 0, & i > r \end{cases} &\in \mathbb{R}^{C \times C} \\ \overleftarrow{\mathbf{W}_{[t]} } &= \text{diag}(\gamma^i_{[t]}) \mathbf{W}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \mathbf{W}_{[t]} &= \left[ \mathbf{I} + \text{strictLower} \left( \text{diag}(\beta_{[t]}) (\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{K}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \overrightarrow{\mathbf{S}_{[t]} } &= \gamma_{[t]}^C \mathbf{S}_{[t]} &\in \mathbb{R}^{d_v \times d_k} \\ \overrightarrow{\mathbf{K}_{[t]} } &= \text{diag}(\frac{\gamma^C_{[t]} }{\gamma^i_{[t]} }) \mathbf{K}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \overleftarrow{\mathbf{Q}_{[t]} } &= \text{diag}(\gamma^i_{[t]}) \mathbf{Q}_{[t]} &\in \mathbb{R}^{C \times d_k} \end{align}\)
(二)Gated Delta Networks and Hybrid Models
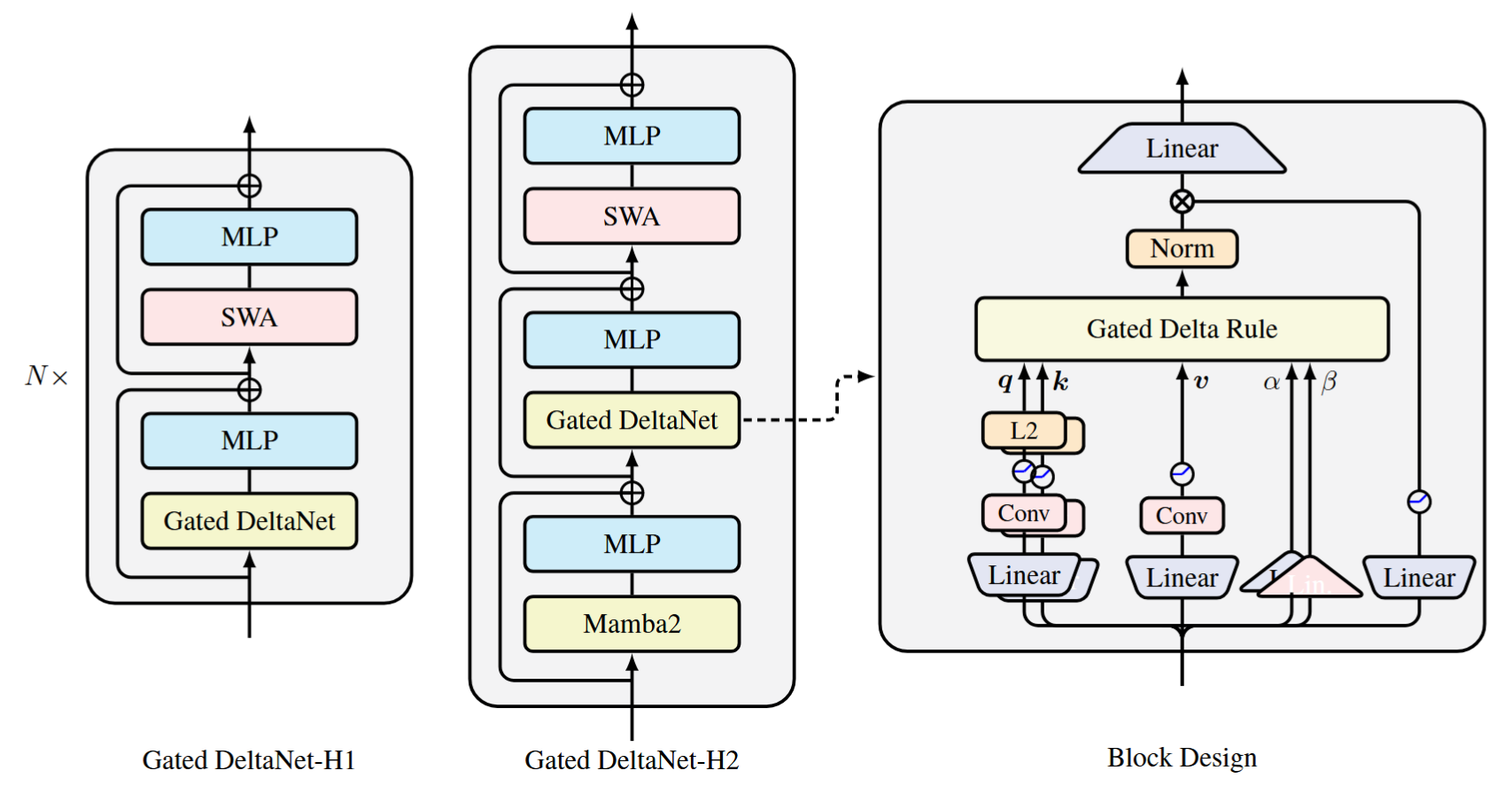
基础的 Gated DeltaNet 与 Llama 的宏观架构一致,但用 gated delta rule 的 token mixing 替换了 self-attention。对于 gated delta rule,仍然需要 ${q,k,v}$,它们是经过一系列轻量的特征提取得到的,包括:
- Linear Projection(线性投影)
- Short Convolution(短卷积,加入局部混合能力)
- SiLU(激活)
- $q,k$ L2 Normalization(训练稳定性)
$\alpha, \beta$ 则仅通过线性投影生成。此外,在做最终的输出投影之前,会经过归一化与门控处理,用于稳定训练、提升表达能力、避免输出分布漂移。
同时不可否认的是, Linear Transformer 仍然存在局部建模能力不足、固定状态容量导致精确检索变难的局限。因此本文还实现了:(1)Gated DeltaNet + sliding window attention (SWA);(2)Mamba2 + Gated DeltaNet + SWA 两种混合模型,进一步提高性能,如下图所示。
三、总结
实验部分略。总之,本文提出 Gated DeltaNet,其键值关联学习优于 Mamba2,内存清除比 DeltaNet 更具适应性,在各类任务中实证结果更优。混合 Gated DeltaNet 模型训练吞吐量和整体性能更高,适用于实际部署。此外,本文提出了一种实现 Gated DeltaNet 的硬件高效训练算法。