【强化学习】1-基本概念
Categories: RL
目录
一、State、Action、Policy等
从grid world这个例子中来理解概念:
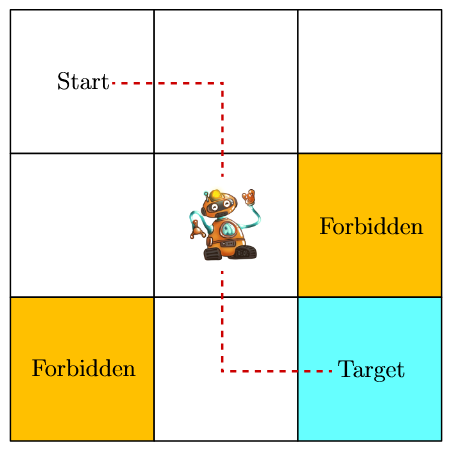
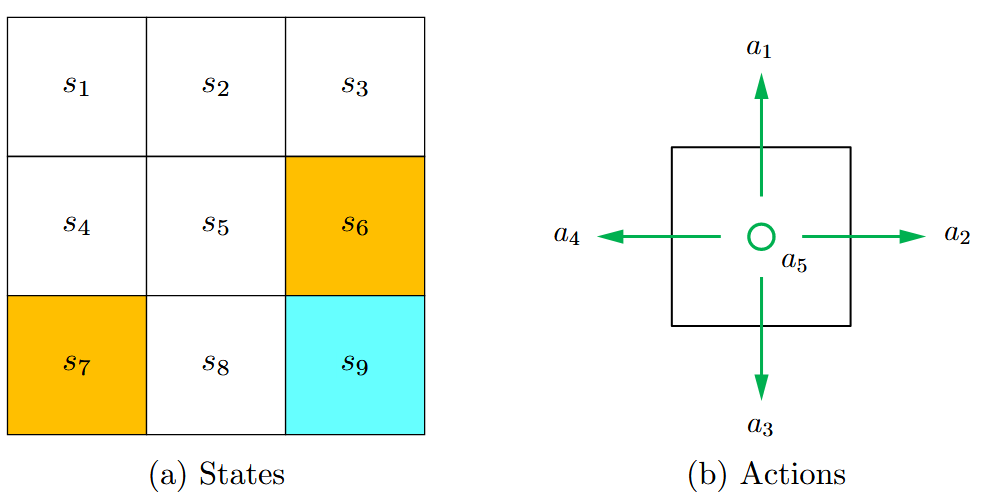
- 状态
State:agent在环境中的状态,$s_1,s_2,\dots,s_9$ - 状态空间
State Space:所有state的集合,$\mathcal{S} = { s_i }_{i=1}^9$ - 动作
Action:一个state所能采取的行动,$a_1,a_2,\dots,a_5$ - 动作空间
Action Space:一个状态的所有可能的action的集合,$\mathcal{A}(s_i)={a_i}_{i=1}^5$,不同state的action space是不一样的
- 状态转移
State Transition:经过一个action,一个state转换到另一个state的过程,状态转移可以根据实际任务来确定,也可以自定义(例如在游戏中)
state transition可以用表格来表示:
| state\action | $a_1$ (upward) | $a_2$ (rightward) | $a_3$ (downward) | $a_4$ (leftward) | $a_5$ (still) |
|---|---|---|---|---|---|
| $s_1$ | $s_1$ | $s_2$ | $s_4$ | $s_1$ | $s_1$ |
| $s_2$ | $s_2$ | $s_3$ | $s_5$ | $s_1$ | $s_2$ |
| $s_3$ | $s_3$ | $s_3$ | $s_6$ | $s_2$ | $s_3$ |
| $s_4$ | $s_1$ | $s_5$ | $s_7$ | $s_4$ | $s_4$ |
| $s_5$ | $s_2$ | $s_6$ | $s_8$ | $s_4$ | $s_5$ |
| $s_6$ | $s_3$ | $s_6$ | $s_9$ | $s_5$ | $s_6$ |
| $s_7$ | $s_4$ | $s_8$ | $s_7$ | $s_7$ | $s_7$ |
| $s_8$ | $s_5$ | $s_9$ | $s_8$ | $s_7$ | $s_8$ |
| $s_9$ | $s_6$ | $s_9$ | $s_9$ | $s_8$ | $s_9$ |
这种表格需要状态转移是确定性(Deterministic)的,而实际中执行一个动作得到的状态可能基于一定的概率,因此可以用条件概率来进一步描述状态转移,对于上述确定性的情况,有:
\[\begin{align} p(s_2 | s_1, a_2) &= 1 \\ p(s_i | s_1, a_2) &= 0 \quad \forall i \neq 2 \end{align}\]当然,状态转移也可以是随机性(Stochastic)的。
- 策略
Policy:告诉agent,在一个state下,应该执行怎样的action,在强化学习中一般用 $\pi$ 表示策略
策略同样可以使用条件概率形式化表达,在确定性的情况下,当处于状态 $s_1$ 时,有:
\[\begin{equation} \begin{aligned} \pi(a_1 \mid s_1) = 0, \\ \pi(a_2 \mid s_1) = 1, \\ \pi(a_3 \mid s_1) = 0, \\ \pi(a_4 \mid s_1) = 0, \\ \pi(a_5 \mid s_1) = 0. \\ \end{aligned} \end{equation}\]同样,也有在随机性情况下的策略。策略也可以用表格来表示,且这种表格表示是具有普遍性的,既可以表达确定性,也可以表达随机性,例如:
| state\action | $a_1$ (upward) | $a_2$ (rightward) | $a_3$ (downward) | $a_4$ (leftward) | $a_5$ (still) |
|---|---|---|---|---|---|
| $s_1$ | 0 | 0.5 | 0.5 | 0 | 0 |
| $s_2$ | 0 | 0 | 1 | 0 | 0 |
| $s_3$ | 0 | 0 | 0 | 1 | 0 |
| $s_4$ | 0 | 1 | 0 | 0 | 0 |
| $s_5$ | 0 | 0 | 1 | 0 | 0 |
| $s_6$ | 0 | 0 | 1 | 0 | 0 |
| $s_7$ | 0 | 1 | 0 | 0 | 0 |
| $s_8$ | 0 | 1 | 0 | 0 | 0 |
| $s_9$ | 0 | 0 | 0 | 0 | 1 |
编程中会用一个矩阵来表示这样的策略。
因此,在一个状态下,策略是有一定概率让agent执行什么,状态转移是agent执行这个动作之后有一定概率得到什么新的状态。
二、Reward、Return、MDP等
- 奖励
Reward:执行一个动作后所得到的一个标量实数,用 $r$ 表示。一个positive的reward代表鼓励执行这样的动作,一个negative的reward代表惩罚执行这样的动作。零reward不惩罚,不惩罚就代表鼓励。
同样可以用条件概率来表达在某个状态,执行一个动作后得到某个reward的概率:
\[\begin{align} p(r = -1 \mid s_1, a_1) = 1, \\ p(r \neq -1 \mid s_1, a_1) = 0. \end{align}\]reward是依赖于当前的状态和执行的动作的,而不是依赖于下一个状态。
- 轨迹
Trajectory:代表state-action-reward链
- 回报
Return:是针对trajectory而言的,即沿着该trajectory得到的所有reward的总和
- 折扣回报
Discounted Return:指的是在考虑未来奖励的情况下,计算当前策略在一个状态下所能获得的奖励总和。它通过对未来的奖励进行折扣,以反映它们相较于当前奖励的重要性。折扣因子(discount factor/discount rate)通常用 $\gamma$ 表示,范围在 $[0,1)$ 。具体而言,如果我们定义回报为:
其中,$R_t$ 是在时刻 $t$ 的折扣回报,$r_t$ 是在时刻 $t$ 获得的奖励(有时候也写作 $r_{t+1}$),且 $\gamma$ 是折扣因子。这种折扣机制使得在计算长期收益时,较近的奖励比远期的奖励更加重要。这样做的目的是为了使得算法在决策时倾向于那些能够在短期内获得更高回报的行动选择,从而提高整体学习效率。$\gamma$ 越趋近于0,最开始得到的奖励越重要,越趋近于1,则未来的奖励会变得重要。
- 回合
Episode:与环境进行交互时,遵循某一policy,agent可能会在某些终止状态(terminal state)下停止。由此产生的trajectory称为一个episode(或trial)
episode回合通常被视为一个有限的轨迹,其中包含一系列状态、动作和相应的奖励。一次完整的交互过程由某些状态转移而成,通过这些状态的变化和所获奖励,agent能够学习最优行为。这样的任务被称为回合任务(episodic tasks),因为它们以一次完整的回合作为基本单位进行分析和评估。这一概念的含义在于,它允许算法在有限的时间内学习并回顾整个交互过程,从而在后续的回合中改进决策。与此相对应的是持续任务(continuing tasks),在这些任务中,交互没有明确的终止状态,学习过程更为复杂。
实际上,可以通过将episodic tasks转化为continuing tasks,使二者在数学上进行统一的表达。这种统一有两种方式:
Option 1:将目标状态(target state)视为一个特殊的吸收状态(absorbing state)。一旦agent达到这个状态,它将永远停留在此状态,并且相应的奖励 $r$ 为 0。
Option 2:将目标状态视为一个正常状态,允许在此状态下执行策略。agent在达到该状态后仍然可以离开,且当再次进入目标状态时可以获得 $r = +1$ 的奖励。
我们选择第二种方式,更具一般化。
- 马尔科夫决策过程
Markov Decision Process (MDP):一些关键要素包括: - 集合:
- 状态集合:$\mathcal{S}$
- 动作集合:$\mathcal{A}$,其中,$s \in \mathcal{S}$
- 奖励集合:$\mathcal{R}(s,a)$
- 概率分布:
- 状态转移概率:在状态 $s$ ,执行动作 $a$ ,转移到状态 $s’$ 的概率:$p(s’|s,a)$
- 奖励概率:在状态 $s$ ,执行动作 $a$ ,得到奖励 $r$ 的概率:$p(r|s,a)$
- 策略:在状态 $s$ ,选择执行动作 $a$ 的概率:$\pi(a|s)$
- 马尔可夫性质:是指随机过程的无记忆属性(与历史无关):
所有概念均可在MDP框架中找到。MDP中有三种概率,策略中选择执行什么动作的概率;执行动作后得到什么状态的状态转移概率;得到奖励的奖励概率。
grid world可以抽象为更一般的模型:Markov process,如右下图所示。
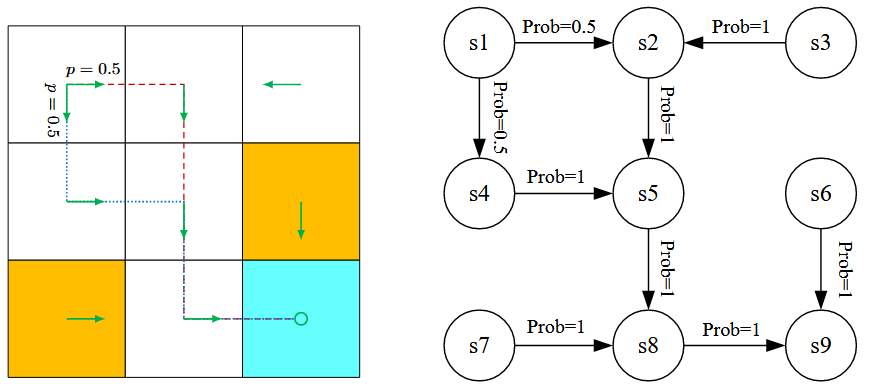
当给定policy后,Markov decision process就变为Markov process。