【强化学习】4-值迭代与策略迭代
Categories: RL
目录
一、值迭代算法
1. 矩阵向量形式
值迭代算法(Value Iteration)即上一节提到的:
\[\begin{equation} v_{k+1} = f(v_k) = \max_\pi (r_\pi + \gamma P_\pi v_k), \quad k = 1, 2, 3, \ldots \end{equation}\]该算法能够找到最优State Value(只有一个)和一个最优Policy(可能有多个)。
该算法可以分解为两步:
- 第1步:Policy更新,求解:
其中 $v_k$ 是迭代时已知的。
- 第2步:Value更新,求解:
注意,这里 $v_k$ 并不是State Value,上式虽然形似贝尔曼公式,但是左侧是 $v_{k+1}$ 而右侧是 $v_k$ ,这里的 $v_k$ 只是迭代的数值。
2. 逐元素形式和实现
Matrix-vector form通常用于理论分析,接下来看Elementwise form以便实际实现。
- 第1步:Policy更新。公式 $\eqref{eq:1}$ 的逐元素形式是:
根据上一节所介绍的,会选取最大的 $q_k(s,a)$ ,即:
\[\begin{equation} \pi_{k+1}(a|s) = \begin{cases} 1 & a = a^*_k(s) \\ 0 & a \neq a^*_k(s) \end{cases} \end{equation}\]其中,$a^*_k(s) = \arg\max_a q_k(a, s)$。 $\pi_{k+1}$ 被称为贪婪策略,因为它简单地选择最大的q值。
- 第2步:Value更新。公式 $\eqref{eq:2}$ 的逐元素形式是:
由于 $\pi_{k+1}$ 是根据贪婪策略得出的,因此上式可以进一步写为:
\[\begin{equation} v_{k+1}(s) = \max_a q_k(a, s) \end{equation}\]3. 伪代码
上面的求解可以总结为如下过程:
\[v_k(s) \rightarrow q_k(s, a) \rightarrow \text{贪婪策略} \pi_{k+1}(a|s) \rightarrow \text{新值} v_{k+1} = \max_a q_k(s, a)\]伪代码如下:
初始化:概率模型 $p(r|s, a)$ 和 $p(s’|s, a)$ 对于所有 $(s, a)$ 已知。初始化猜测值 $v_0$。 目标:寻找最优状态值和解决Bellman最优方程的最优策略。
当 $v_k$ 在 $| v_k - v_{k-1} |$ 大于预定义的小阈值时,对于第 $k$ 次迭代,执行以下操作: \(\begin{equation*} \begin{aligned} &\text{For every state } s \in \mathcal{S}, \text{ do:} \\ &\quad \quad \text{For every action } a \in \mathcal{A}(s), \text{ do:} \\ &\quad \quad \quad \quad \text{q-value: } q_k(s, a) = \sum_r p(r|s, a)r + \gamma \sum_{s'} p(s'|s, a)v_k(s') \\ &\quad \quad \text{Maximum action value: } a^*_k(s) = \arg\max_a q_k(s, a) \\ &\quad \quad \text{Policy update: } \pi_{k+1}(a|s) = 1 \text{ if } a = a^*_k, \text{ else } \pi_{k+1}(a|s) = 0 \\ &\quad \quad \text{Value update: } v_{k+1}(s) = \max_a q_k(a, s) \end{aligned} \end{equation*}\)
二、策略迭代算法
1. 算法描述
给定一个随机初始化的策略 $\pi_0$
- 第1步:策略评估(policy evaluation,PE) 计算 $\pi_k$ 的state value:
- 第2步:策略改进(policy improvement,PI)
因此算法的过程如下:
\[\begin{equation} \pi_0 \xrightarrow{PE} v_{\pi_0} \xrightarrow{PI} \pi_1 \xrightarrow{PE} v_{\pi_1} \xrightarrow{PI} \pi_2 \xrightarrow{PE} v_{\pi_2} \xrightarrow{PI} \cdots \end{equation}\]这里考虑4个问题:
Q1:在policy evaluation阶段,如何求解贝尔曼公式得到state value $v_{\pi_k}$ ?
这在前面求解贝尔曼公式中已经做过介绍:
-
公式求解: \(\begin{equation} v_{\pi_k} = (I - \gamma P_{\pi_k})^{-1} r_{\pi_k} \end{equation}\)
-
迭代求解: \(\begin{equation} v_{\pi_k}^{(j+1)} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}^{(j)}, \quad j = 0, 1, 2, \ldots \label{eq:3} \end{equation}\)
可见,在策略迭代的PE阶段中,包括了另一个小的迭代,用于求解贝尔曼公式。
Q2: 在策略改进步骤中,为什么新策略 $\pi_{k + 1}$ 比 $\pi_k$ 更好?
给出以下结论:如果 $\pi_{k + 1} = \arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_k})$,那么对于任意的 $k$,都有 $v_{\pi_{k + 1} }\geq v_{\pi_k}$。这里,$v_{\pi_{k + 1} }\geq v_{\pi_k}$ 表示对于所有的 $s$ ,都有 $v_{\pi_{k + 1} }(s)\geq v_{\pi_k}(s)$ 。
证明: 由于 $v_{\pi_{k + 1} }$ 和 $v_{\pi_k}$ 都是state value,因此它们都满足贝尔曼公式:
\[v_{\pi_{k + 1} }=r_{\pi_{k + 1} }+\gamma P_{\pi_{k + 1} }v_{\pi_{k + 1} } \\ v_{\pi_k}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k}\]由于 $\pi_{k + 1}=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_k})$ ,可知
\[r_{\pi_{k + 1} }+\gamma P_{\pi_{k + 1} }v_{\pi_k}\geq r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k}\]那么有:
\[\begin{aligned} v_{\pi_k}-v_{\pi_{k + 1} }&=(r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k})-(r_{\pi_{k + 1} }+\gamma P_{\pi_{k + 1} }v_{\pi_{k + 1} })\\ &\leq(r_{\pi_{k + 1} }+\gamma P_{\pi_{k + 1} }v_{\pi_k})-(r_{\pi_{k + 1} }+\gamma P_{\pi_{k + 1} }v_{\pi_{k + 1} })\\ &\leq\gamma P_{\pi_{k + 1} }(v_{\pi_k}-v_{\pi_{k + 1} }) \end{aligned}\]因此,
\[\begin{aligned} v_{\pi_k}-v_{\pi_{k + 1} }\leq\gamma^2 P_{\pi_{k + 1} }^2(v_{\pi_k}-v_{\pi_{k + 1} })\leq\cdots &\leq\gamma^n P_{\pi_{k + 1} }^n(v_{\pi_k}-v_{\pi_{k + 1} }) \\ &\leq\lim_{n\rightarrow\infty}\gamma^n P_{\pi_{k + 1} }^n(v_{\pi_k}-v_{\pi_{k + 1} })=0 \end{aligned}\]其中,$P_{\pi_{k + 1} }^n$ 是非负的状态转移矩阵,每一行之和为1。
Q3:为什么这样的迭代能找到最优策略?
直观上,由于每一次都对策略进行了改进,即
\[\begin{equation} v_{\pi_0}\leq v_{\pi_1}\leq v_{\pi_2}\leq\cdots\leq v_{\pi_k}\leq\cdots\leq v^* \end{equation}\]最终,$v_{\pi_k}$ 不断增长并收敛。不过这仍然需要证明收敛到的是最优的 $v^*$ 。
首先给出结论:通过策略迭代算法的计算,state value ${v_{\pi_k}}_{k = 0}^{\infty}$ 最终会收敛到最优state value $v^*$ ,同时,策略 ${\pi_k}_{k = 0}^{\infty}$ 也会收敛到最优策略。
证明: 证明的思路是表明策略迭代算法的收敛速度比值迭代算法快。
为了证明序列 ${v_{\pi_k}}_{k = 0}^{\infty}$ 的收敛,我们引出另一个序列 ${v_k}_{k = 0}^{\infty}$ ,通过比较这两个序列,我们可以更好地理解策略迭代的收敛性质。${v_k}_{k = 0}^{\infty}$ 由下式给出:
\[v_{k + 1}=f(v_k)=\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_k)\]这实际上就是值迭代算法。我们已经知道对于值迭代算法,对于任意初始化的 $v_0$ , $v_k$ 收敛于 $v^*$ 。
对于 $k = 0$ ,$v_{\pi_0}$ 是state value,它必然是有界的,因而我们总能找到一个 $v_0$ 使得对于任何 $\pi_0$ ,有 $v_{\pi_0}\geq v_0$ 。
接下来,通过归纳法,我们期望证明对所有 $k$ ,有【 $v_k\leq v_{\pi_k}\leq v^*$ 】。
对于 $k \geq 0$ ,假设 $v_{\pi_k}\geq v_k$ ,那么对于 $k+1$ ,有
\[\begin{equation*} \begin{aligned} v_{\pi_{k+1} } - v_{k+1} &= (r_{\pi_{k+1} } + \gamma P_{\pi_{k+1} } v_{\pi_{k+1} }) - \max_\pi (r_\pi + \gamma P_\pi v_k) \\ &\geq (r_{\pi_{k+1} } + \gamma P_{\pi_{k+1} } v_{\pi_k}) - \max_\pi (r_\pi + \gamma P_\pi v_k) \quad (\text{由Q2中的结论 }v_{\pi_{k+1} } \geq v_{\pi_k}) \\ &= (r_{\pi_{k+1} } + \gamma P_{\pi_{k+1} } v_{\pi_k}) - (r_{\pi'_k} + \gamma P_{\pi'_k} v_k) \quad(\text{假设 } \pi'_k = \arg\max_\pi (r_\pi + \gamma P_\pi v_k)) \\ &\geq (r_{\pi'_k} + \gamma P_{\pi'_k} v_{\pi_k}) - (r_{\pi'_k} + \gamma P_{\pi'_k} v_k) \quad(\text{因为 } \pi_{k+1} = \arg\max_\pi (r_\pi + \gamma P_\pi v_{\pi_k})) \\ &= \gamma P_{\pi'_k} (v_{\pi_k} - v_k) \end{aligned} \end{equation*}\]因为 $v_{\pi_k} - v_k \geq 0$ 且 $P_{\pi’_k}$ 非负,因此 $P_{\pi’_k} (v_{\pi_k} - v_k) \geq 0$ ,故 $v_{\pi_{k+1} } - v_{k+1} \geq 0$ 。
因此,我们可以归纳出对任意 $k \geq 0$ ,有 $v_k \leq v_{\pi_k} \leq v^*$ ,由于 $v_k$ 收敛于 $v^*$ ,$v_{\pi_k}$ 也同样收敛于 $v^*$
Q4:策略迭代和值迭代之间有什么关系?
从Q3的证明中可以看出:$v_k \leq v_{\pi_k} \leq v^*$ ,详细的在后续进行进一步对比。
2. 逐元素形式和实现
- 第1步:策略评估。公式 $\eqref{eq:3}$ 的逐元素形式是:
当 $j\rightarrow\infty$ 或 $j$ 足够大或 $|v_{\pi_k}^{(j + 1)}-v_{\pi_k}^{(j)}|$ 足够小时停止。
- 第2步:策略改进。公式 $\eqref{eq:4}$ 的逐元素形式是:
其中,$q_{\pi_k}(s,a)$ 是策略 $\pi_k$ 下的action value,有
\[\begin{equation} a_k^*(s)=\arg\max_{a}q_{\pi_k}(a,s) \end{equation}\]由贪婪策略有:
\[\begin{equation} \pi_{k + 1}(a|s)= \begin{cases} 1&a = a_k^*(s)\\ 0&a\neq a_k^*(s) \end{cases} \end{equation}\]3. 伪代码
伪代码如下:
初始化:概率模型 $p(r|s, a)$ 和 $p(s’|s, a)$ 对于所有 $(s, a)$ 已知。初始化猜测值 $\pi_0$。 目标:寻找最优状态值和最优策略
当策略还未收敛,对于第 $k$ 次迭代,执行以下操作:
- 策略评估: \(\begin{aligned} &\text{an arbitrary initial guess } v_{\pi_k}^{(0)} \\ &\text{While } v_{\pi_k}^{(j)} \text{ has not converged, for the } j \text{th iteration, do} \\ &\quad \quad \text{For every state } s\in\mathcal{S}, \text{ do} \\ &\quad \quad \quad \quad v_{\pi_k}^{(j + 1)}(s)=\sum_{a}\pi_k(a|s)\left[\sum_{r}p(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_{\pi_k}^{(j)}(s')\right] \end{aligned}\)
- 策略改进: \(\begin{aligned} &\text{For every state } s\in\mathcal{S}, \text{ do} \\ &\quad \quad \text{For every action } a\in\mathcal{A}(s), \text{ do} \\ &\quad \quad \quad \quad q_{\pi_k}(s,a)=\sum_{r}p(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_{\pi_k}(s') \\ &\quad \quad a_k^*(s)=\arg\max_{a}q_{\pi_k}(s,a)\\ &\quad \quad \pi_{k + 1}(a|s)=1 \text{ if } a = a_k^*, \text{ else } \pi_{k + 1}(a|s)=0 \end{aligned}\)
三、截断策略迭代算法
值迭代算法和策略迭代算法,实际上是截断策略迭代算法的两个极端情况。
1. 回顾
策略迭代:从 $\pi_0$ 开始
-
策略评估(PE): \(\begin{equation} v_{\pi_k}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k} \end{equation}\)
-
策略改进(PI): \(\begin{equation} \pi_{k + 1}=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_k}) \end{equation}\)
值迭代:从 $v_0$ 开始
-
策略更新(PU): \(\begin{equation} \pi_{k + 1}=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{k}) \end{equation}\)
-
值更新(VU): \(\begin{equation} v_{k + 1}=r_{\pi_{k + 1} }+\gamma P_{\pi_{k + 1} }v_{k} \end{equation}\)
二者的过程是非常类似的:
\[\begin{equation*} \begin{aligned} &策略迭代:\pi_0 \xrightarrow{PE} v_{\pi_0} \xrightarrow{PI} \pi_1 \xrightarrow{PE} v_{\pi_1} \xrightarrow{PI} \pi_2 \xrightarrow{PE} v_{\pi_2} \xrightarrow{PI} \cdots \\ &值迭代:\quad \quad \quad \quad u_0 \xrightarrow{PU} \pi_1' \xrightarrow{VU} u_1 \xrightarrow{PU} \pi_2' \xrightarrow{VU} u_2 \xrightarrow{PU} \cdots \end{aligned} \end{equation*}\]使用表格来一步一步表示这个过程⭐️:
| 步骤 | 策略迭代算法 | 值迭代算法 | 备注 |
|---|---|---|---|
| 1) Policy: | $\pi_0$ | N/A | |
| 2) Value: | $v_{\pi_0}=r_{\pi_0}+\gamma P_{\pi_0}v_{\pi_0}$ | $\color{red}{v_0 := v_{\pi_0} }$ | 这里人为让 $v_0$ 初始化为 $v_{\pi_0}$ ,方便比较,实际上 $v_0$ 可以是任意的 |
| 3) Policy: | $\pi_1=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_0})$ | $\pi_1=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{0})$ | 由于令 $v_0$ 与 $v_{\pi_0}$ 一致,因此这两个策略相同 |
| 4) Value: | $\color{green}{v_{\pi_1} }=r_{\pi_1}+\gamma P_{\pi_1}\color{blue}{v_{\pi_1} }$ | $\color{green}{v_1}=r_{\pi_1}+\gamma P_{\pi_1}\color{blue}{v_{0} }$ | 因为 $v_{\pi_1} \geq v_{\pi_0} = v_0$,所以 $v_{\pi_1} \geq v_1$ |
| 5) Policy: | \(\pi_2=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_1})\) | \(\pi_2'=\arg\max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{1})\) | |
| $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ |
说明:表格中的前三步是一致的,到了第四步,就开始不同了:
- 在策略迭代算法中,求解 $v_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v_{\pi_1}$ 需要进行迭代求解,从 $v_{\pi_1}^{(0)}$ 迭代到 $v_{\pi_1}^{(\infty)}$ 从而求解出 $v_{\pi_1}$ 。
- 在值迭代算法中,$v_1=r_{\pi_1}+\gamma P_{\pi_1}v_0$ 是单步计算。
2. 比较算法关系
现在通过下面的步骤来理解截断策略迭代算法:
考虑求解贝尔曼公式 $v_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v_{\pi_1}$ 这一步:
\[\begin{equation*} \begin{aligned} &v_{\pi_1}^{(0)} = v_0 (假定 v_{\pi_1}^{(0)} 的初始值为v_0)\\ 值迭代算法 \leftarrow v_1 \longleftarrow &v_{\pi_1}^{(1)}=r_{\pi_1}+\gamma P_{\pi_1}v_{\pi_1}^{(0)} \\ &v_{\pi_1}^{(2)}=r_{\pi_1}+\gamma P_{\pi_1}v_{\pi_1}^{(1)} \\ &\quad \quad \vdots \\ 截断策略迭代 \leftarrow \bar{v}_1 \longleftarrow &v_{\pi_1}^{(j)}=r_{\pi_1}+\gamma P_{\pi_1}v_{\pi_1}^{(j - 1)} \\ &\quad \quad \vdots \\ 策略迭代 \leftarrow v_{\pi_1} \longleftarrow &v_{\pi_1}^{(\infty)}=r_{\pi_1}+\gamma P_{\pi_1}v_{\pi_1}^{(\infty)} \end{aligned} \end{equation*}\]由此可见三种算法之间的关系:
- 值迭代算法只计算一次。
- 策略迭代算法进行无限次迭代计算。
- 截断策略迭代算法进行有限次(设为 $j$ 次)迭代计算。从 $j$ 到 $\infty$ 的其余迭代被截断。
- 策略迭代算法实际不可能是无限次迭代,因此实际上是截断策略迭代算法
3. 伪代码
伪代码与策略迭代的伪代码基本一致,仅在策略评估时,需要设定截断的循环次数
初始化:概率模型 $p(r|s, a)$ 和 $p(s’|s, a)$ 对于所有 $(s, a)$ 已知。初始化猜测值 $\pi_0$。 目标:寻找最优状态值和最优策略
当策略还未收敛,对于第 $k$ 次迭代,执行以下操作:
- 策略评估: \(\begin{aligned} &\text{Initialization: select the initial guess as } v_{k}^{(0)} = v_{k - 1}. \\ &\text{The maximum iteration is set to be } j_{\text{truncate} }. \\ &\text{While } j < j_{\text{truncate} }, \text{ do} \\ &\quad \quad \text{For every state } s\in\mathcal{S}, \text{ do} \\ &\quad \quad \quad \quad v_{k}^{(j + 1)}(s)=\sum_{a}\pi_k(a|s)\left[\sum_{r}p(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_{k}^{(j)}(s')\right] \\ &\text{Set } v_k = v_k^{(j_{\text{truncate} })} \end{aligned}\)
- 策略改进: \(\begin{aligned} &\text{For every state } s\in\mathcal{S}, \text{ do} \\ &\quad \quad \text{For every action } a\in\mathcal{A}(s), \text{ do} \\ &\quad \quad \quad \quad q_{k}(s,a)=\sum_{r}p(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_{k}(s') \\ &\quad \quad a_k^*(s)=\arg\max_{a}q_{k}(s,a)\\ &\quad \quad \pi_{k + 1}(a|s)=1 \text{ if } a = a_k^*, \text{ else } \pi_{k + 1}(a|s)=0 \end{aligned}\)
对于如下的求解过程:
\(\begin{equation} v_{\pi_k}^{(j + 1)}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k}^{(j)},\ j = 0,1,2,\ldots \end{equation}\) 可以证明,如果初始猜测值选择为 $v_{\pi_k}^{(0)} = v_{\pi_{k - 1} }$,则对于每个 $j = 0,1,2,\ldots$,都有 \(\begin{equation} v_{\pi_k}^{(j + 1)}\geq v_{\pi_k}^{(j)} \end{equation}\) 因此在三种算法的收敛过程中,大小关系大致如下图所示:
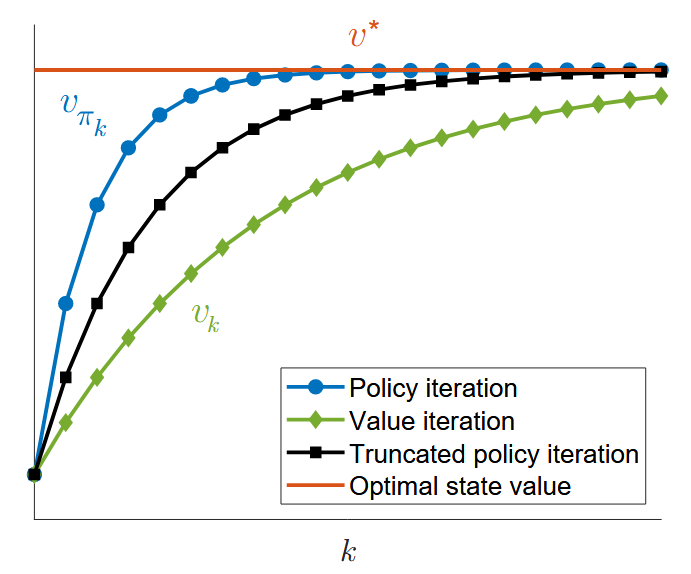
最后再简单总结一下:
| 内容\算法 | 值迭代算法 | 策略迭代算法 |
|---|---|---|
| step 1 | 策略更新: $\color{green}{\pi_{k+1} = \arg\max_\pi (r_\pi + \gamma P_\pi v_k)}$ 初始化 $v_0$ ,求策略 |
策略评估: $\color{red}{v_{\pi_k} } = r_{\pi_k} + \gamma P_{\pi_k} \color{red}{v_{\pi_k} }$ 初始化 $\pi_0$ ,求状态值 |
| step 2 | 值更新: $\color{blue}{v_{k+1} } = r_{\pi_{k+1} } + \gamma P_{\pi_{k+1} } \color{red}{v_k}$ 将策略代入,求更好的值 |
策略改进: $\color{green}{\pi_{k+1} = \arg\max_\pi (r_\pi + \gamma P_\pi v_{\pi_k})}$ 将值代入,求更好的策略 |