【强化学习】6-随机近似与随机梯度下降
Categories: RL
目录
一、例子
回顾一下mean estimation问题:
- 考虑一个随机变量 $X$
- 目标是估计 $\mathbb{E}[X]$
- 假设我们有独立同分布的采样 ${x_i}_{i=1}^N$
- 则 $X$ 的期望可以估计为:
上节我们已经知道这也是Monte Carlo estimation的基本思路,当 $N \to \infty$ 时,$\bar{x} \to \mathbb{E}[X]$。
计算 $\mathbb{E}[X]$ 有两种方法:
- 第一种方法:先收集所有样本,再计算平均值。这种方法的缺点是,如果样本是随着时间逐个采集的,就必须等待所有样本都收集完毕才能计算。
- 第二种方法:以增量(incremental)和迭代(iterative)的方式逐步计算平均值。
具体来说,第二种方法的过程如下:
假设: \(\begin{equation} w_{k+1} = \frac{1}{k} \sum_{i=1}^k x_i, \quad k = 1, 2, \ldots \end{equation}\) 因此有: \(\begin{equation} w_k = \frac{1}{k - 1} \sum_{i=1}^{k-1} x_i, \quad k = 2, 3, \ldots \end{equation}\) 那么,$w_{k+1}$ 可以用 $w_k$ 表示为: \(\begin{equation} \begin{aligned} w_{k+1} = \frac{1}{k} \sum_{i=1}^k x_i &= \frac{1}{k} \left( \sum_{i=1}^{k-1} x_i + x_k \right) \\ &= \frac{1}{k} \big((k - 1) w_k + x_k\big) = w_k - \frac{1}{k}(w_k - x_k) \end{aligned} \end{equation}\) 因此,我们得到以下迭代算法: \(\begin{equation} w_{k+1} = w_k - \frac{1}{k}(w_k - x_k) \end{equation}\) 如果上个时刻我们已经计算得到了 $w_k$,当前时刻采样得到了 $x_k$,就可以直接通过上式计算得到 $w_{k+1}$。该算法的一个优点是:一旦接收到一个样本,就可以立即得到均值估计。在初始阶段,由于样本数量不足,均值估计不够准确(即 $w_k \neq \mathbb{E}[X]$)。然而,它总比没有估计要好。随着获得更多样本,估计值会逐步改进(即当 $k \to \infty$ 时,$w_k \to \mathbb{E}[X]$)。
更一般的表达式是: \(\begin{equation} w_{k+1} = w_k - \alpha_k (w_k - x_k) \end{equation}\) 其中 $1/k$ 被替换为 $\alpha_k > 0$。可以证明当 ${\alpha_k}$ 满足一定条件时,该算法可以收敛到均值 $\mathbb{E}[X]$,实际上它是一种特殊的Stochastic Approximation(SA)算法,同样也是一种特殊的Stochastic Gradient Descent(SGD)算法。
二、Robbins-Monro 算法
1. 算法描述
随机近似(Stochastic approximation, SA)
- SA指的是解决求根或优化问题的一类广泛的随机迭代算法
- 与其他求根算法(例如梯度下降方法)相比,SA的强大之处在于:它不需要知道目标函数的表达式,也不需要其导数。
Robbins-Monro (RM)算法
- 它是随机近似领域的一项开创性工作
- 著名的随机梯度下降算法是 RM 算法的一种特殊形式
- 刚才介绍的mean estimation算法也是该算法的一种特殊形式
问题陈述:假设我们要找到方程 \(\begin{equation} g(w)=0 \end{equation}\) 的根,其中 $w \in \mathbb{R}$ 是要求解的变量,$g: \mathbb{R} \to \mathbb{R}$ 是一个函数。
许多问题最终都可以转化为这个求根问题。例如,假设 $J(w)$ 是一个需要最小化的目标函数,那么优化问题可以转化为: \(\begin{equation} g(w) = \nabla_w J(w) = 0 \end{equation}\) 像 $g(w) = c$(其中 $c$ 为常数)这样的方程也可以通过将 $g(w)-c$ 视为一个新函数,转化为上述方程。
如何计算 $g(w)=0$ 的根?
如果知道 $g$ 或其导数的表达式,有很多数值算法可以解决这个问题。但如果函数 $g$ 的表达式未知(例如神经网络),此时可以通过Robbins-Monro算法解决这个问题: \(\begin{equation} w_{k+1} = w_k - a_k \tilde{g}(w_k, \eta_k), \qquad k = 1, 2, 3, \ldots \end{equation}\) 其中:
- $w_k$ 是第 $k$ 次迭代的根估计值
- $\tilde{g}(w_k, \eta_k) = g(w_k) + \eta_k$ 是第 $k$ 次含噪声的观测值
- $a_k$ 是一个正系数
函数 $g(w)$ 是一个黑盒,该算法依赖于数据:
- 输入序列:${w_k}$
- 含噪声的输出序列:${\tilde{g}(w_k, \eta_k)}$
2. 收敛性分析
为什么 RM 算法能找到 $g(w)=0$ 的根?首先看一个直观的例子:
以 $g(w) = \tanh(w-1)$ 为例,真正的根是 $w^* = 1$。设置 $w_1 = 3$, $a_k = 1/k$, $\eta_k \equiv 0$。
RM 算法为: \(\begin{equation} w_{k+1} = w_k - a_k g(w_k) \end{equation}\) 仿真结果如下图所示,它显示 $w_k$ 能够收敛到真正的根 $w^* = 1$。
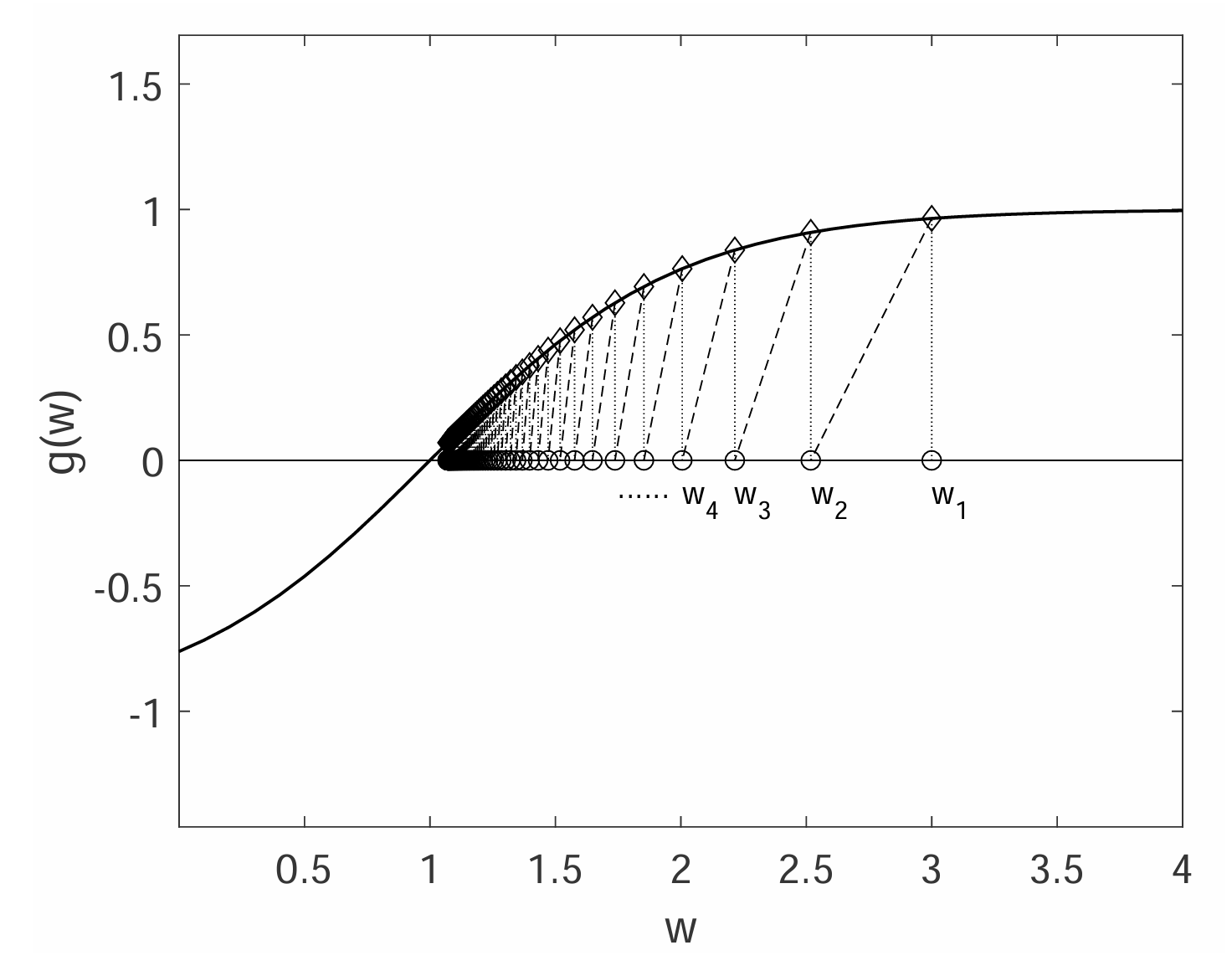
直观理解:$w_{k+1}$ 比 $w_k$ 更接近 $w^*$。
- 当 $w_k > w^*$ 时,有 $g(w_k) > 0$。那么 $w_{k+1} = w_k - a_k g(w_k) < w_k$,因此 $w_{k+1}$ 比 $w_k$ 更接近 $w^*$。
- 当 $w_k < w^*$ 时,有 $g(w_k) < 0$。那么 $w_{k+1} = w_k - a_k g(w_k) > w_k$,因此 $w_{k+1}$ 比 $w_k$ 更接近 $w^*$。
上述分析是直观的,但并不严谨。下面直接给出一个严谨的收敛结果。
Robbins-Monro 定理
在 Robbins-Monro 算法中,如果满足以下条件:
1) 对所有 $w$,有 $0 < c_1 \leq \nabla_w g(w) \leq c_2$;
2) $\sum_{k=1}^\infty a_k = \infty$ 且 $\sum_{k=1}^\infty a_k^2 < \infty$;
3) $\mathbb{E}[\eta_k | \mathcal{H}_k] = 0$ 且 $\mathbb{E}[\eta_k^2 | \mathcal{H}_k] < \infty$;
其中 $\mathcal{H}_k = {w_k, w_{k-1}, …}$,那么 $w_k$ 以概率 1 收敛到满足 $g(w^*) = 0$ 的根 $w^*$。
三个条件的解释:
-
条件 1:$0 < c_1 \leq \nabla_w g(w) \leq c_2$
- 这表明 $g$ 是单调递增的,确保了 $g(w)=0$ 的根存在且唯一。
- 梯度有上界。
-
条件 2:$\sum_{k=1}^\infty a_k = \infty$ 且 $\sum_{k=1}^\infty a_k^2 < \infty$
-
$\sum a_k^2 < \infty$ 确保了当 $k \to \infty$ 时,$a_k$ 收敛到 0。
-
为什么这个条件很重要?因为 $w_{k+1} - w_k = -a_k \tilde{g}(w_k, \eta_k)$。如果 $a_k \to 0$,那么 $a_k \tilde{g}(w_k, \eta_k) \to 0$,因此 $w_{k+1} - w_k \to 0$。如果 $w_k$ 最终收敛,我们需要 $w_{k+1} - w_k \to 0$ 这一事实。如果 $w_k \to w^*$,$g(w_k) \to 0$,$\tilde{g}(w_k, \eta_k)$ 主要受 $\eta_k$ 的影响。
-
$\sum a_k = \infty$ 表明 $a_k$ 不应该收敛到零太快。
-
为什么这个条件很重要?将 $w_2 = w_1 - a_1 \tilde{g}(w_1, \eta_1)$, $w_3 = w_2 - a_2 \tilde{g}(w_2, \eta_2)$,…,$w_{k+1} = w_k - a_k \tilde{g}(w_k, \eta_k)$ 汇总起来可以得到: \(\begin{equation} w_1 - w_\infty = \sum_{k=1}^\infty a_k \tilde{g}(w_k, \eta_k) \end{equation}\) 假设 $w_\infty = w^*$。如果 $\sum a_k < \infty$,那么 $\sum a_k \tilde{g}(w_k, \eta_k)$ 可能有界。那么,如果初始猜测 $w_1$ 任意远离 $w^*$,上面的等式就会失效。
-
一个典型的满足这两个条件的序列是 $a_k = 1/k$。我们知道 $\sum_{k=1}^\infty 1/k = \infty$(调和级数发散),而 $\sum_{k=1}^\infty 1/k^2 = \pi^2/6 < \infty$。
-
-
条件 3:$\mathbb{E}[\eta_k | \mathcal{H}_k] = 0$ 且 $\mathbb{E}[\eta_k^2 | \mathcal{H}_k] < \infty$
- 一个特殊但常见的情况是,${\eta_k}$ 是一个独立同分布的随机序列,满足 $\mathbb{E}[\eta_k] = 0$ 且 $\mathbb{E}[\eta_k^2] < \infty$。观测误差 $\eta_k$ 不要求是高斯分布。
注意:如果不满足这三个条件,算法可能无法工作。例如,$g(w) = w^3 - 5$ 不满足第一个关于梯度有界的条件。如果初始猜测很好,算法可以收敛(局部地);否则,它会发散。在许多强化学习算法中,我们将会看到 $a_k$ 通常被选为一个足够小的常数。虽然在这种情况下不满足第二个条件,但算法仍然可以有效工作。
3. 应用到 mean estimation 中
回顾一下,均值估计算法是 $w_{k+1} = w_k + \alpha_k (x_k - w_k)$。 我们知道:
- 如果 $\alpha_k = 1/k$,那么 $w_{k+1} = \frac{1}{k} \sum_{i=1}^k x_i$。
- 如果 $\alpha_k$ 不是 $1/k$,其收敛性没有被分析过。
接下来,我们将展示这个算法是 RM 算法的一个特例,那么它的收敛性自然就得到了保证。
-
构造目标函数:考虑函数 \(\begin{equation} g(w) \doteq w - \mathbb{E}[X] \end{equation}\) 我们的目标是求解 $g(w) = 0$。如果能够做到,那么我们就可以得到 $\mathbb{E}[X]$。
-
获取噪声观测:我们能得到的观测是 \(\begin{equation} \tilde{g}(w, x) \doteq w - x \end{equation}\) 因为我们只能获得 $X$ 的样本。注意,它可以分解为: \(\begin{equation} \begin{aligned} \tilde{g}(w, \eta) &= w - x = w - x + \mathbb{E}[X] - \mathbb{E}[X] \\ &= (w - \mathbb{E}[X]) + (\mathbb{E}[X] - x) \doteq g(w) + \eta \end{aligned} \end{equation}\) 其中 $\eta = \mathbb{E}[X] - x$ 是均值为零的噪声项。
-
应用 RM 算法:用于求解 $g(w)=0$ 的 RM 算法是 \(\begin{equation} w_{k+1} = w_k - \alpha_k \tilde{g}(w_k, \eta_k) = w_k - \alpha_k (w_k - x_k) \end{equation}\) 这正是均值估计算法。
其收敛性自然成立。
三、随机梯度下降
接下来,我们介绍随机梯度下降算法。SGD 在机器学习领域和强化学习中广泛应用。SGD 是 RM 算法的一个特例,而均值估计算法又是 SGD 的一个特例。它们三者的关系是非常密切的。
1. 算法描述
假设我们要解决以下优化问题: \(\begin{equation} \min_w J(w) = \mathbb{E}[f(w, X)] \end{equation}\)
- $w$ 是要优化的参数。
- $X$ 是一个随机变量。期望是针对 $X$ 的。
- $w$ 和 $X$ 可以是标量或向量。函数 $f(\cdot)$ 是一个标量。
目标是找到最优的 $w$ 使得目标函数的值最小。
方法 1:梯度下降 \(\begin{equation} w_{k+1} = w_k - \alpha_k \nabla_w \mathbb{E}[f(w_k, X)] = w_k - \alpha_k \mathbb{E}[\nabla_w f(w_k, X)] \end{equation}\) 缺点:期望值难以获得。
方法 2:批量梯度下降 用样本均值近似期望: \(\begin{equation} \mathbb{E}[\nabla_w f(w_k, X)] \approx \frac{1}{n} \sum_{i=1}^n \nabla_w f(w_k, x_i) \end{equation}\)
\[\begin{equation} w_{k+1} = w_k - \alpha_k \frac{1}{n} \sum_{i=1}^n \nabla_w f(w_k, x_i) \end{equation}\]缺点:每次迭代需要大量样本。
方法 3:随机梯度下降 \(\begin{equation} w_{k+1} = w_k - \alpha_k \nabla_w f(w_k, x_k) \end{equation}\)
- 与梯度下降相比:用随机梯度 $\nabla_w f(w_k, x_k)$ 代替了真实梯度 $\mathbb{E}[\nabla_w f(w_k, X)]$。
- 与批量梯度下降相比:相当于取 $n=1$。
2. 示例与应用
考虑一个例子: \(\begin{equation} \min_w J(w) = \mathbb{E}[f(w, X)] = \mathbb{E}\left[ \frac{1}{2} \| w - X \|^2 \right] \end{equation}\) 其中 \(\begin{equation} f(w, X) = \| w - X \|^2 / 2 \qquad \nabla_w f(w, X) = w - X \end{equation}\)
显然,为了得到 $J(w)$ 的最小值,我们首先对其求梯度,并令梯度为 0,有: \(\begin{equation} \begin{aligned} \nabla_w J(w) = \nabla_w \mathbb{E}[f(w, X)] &= \mathbb{E}[\nabla_w f(w, X)] \\ &= \mathbb{E}[w-X] \\ &= w - \mathbb{E}[X] = 0 \end{aligned} \end{equation}\) 因此 $w^* = \mathbb{E}[X]$ 。
GD 算法对此问题的求解为: \(\begin{equation} \begin{aligned} w_{k+1} &= w_k - \alpha_k \nabla_w J(w_k) \\ &= w_k - \alpha_k \mathbb{E}[\nabla_w f(w_k, X)] \\ &= w_k - \alpha_k \mathbb{E}[w_k - X] \end{aligned} \end{equation}\) SGD 算法对此问题的求解为: \(\begin{equation} w_{k+1} = w_k - \alpha_k \nabla_w f(w_k, x_k) = w_k - \alpha_k (w_k - x_k) \end{equation}\) 这个 SGD 算法与我们之前介绍的均值估计算法完全相同。也就是说,均值估计算法是一个特殊的 SGD 算法。
3. 收敛性分析
从 GD 到 SGD,可以理解为用一个采样来近似 $\mathbb{E}$:
- GD: $w_{k+1} = w_k - \alpha_k \mathbb{E}[\nabla_w f(w_k, X)]$
- SGD: $w_{k+1} = w_k - \alpha_k \nabla_w f(w_k, x_k)$
$\nabla_w f(w_k, x_k)$ 可以看作是 $\mathbb{E}[\nabla_w f(w, X)]$ 的含噪声测量: \(\begin{equation} \nabla_w f(w_k, x_k) = \mathbb{E}[\nabla_w f(w, X)] + \underbrace{[\nabla_w f(w_k, x_k) - \mathbb{E}[\nabla_w f(w, X)]]}_{\eta} \end{equation}\) 由于 $\nabla_w f(w_k, x_k) \neq \mathbb{E}[\nabla_w f(w, X)]$,通过 SGD 能否保证当 $k \to \infty$ 时,$w_k \to w^*$ ?
SGD 的目标是最小化 $J(w) = \mathbb{E}[f(w, X)]$,这个问题可以转化为求根问题: \(\begin{equation} \nabla_w J(w) = \mathbb{E}[\nabla_w f(w, X)] = 0 \end{equation}\) 令 \(\begin{equation} g(w) = \nabla_w J(w) = \mathbb{E}[\nabla_w f(w, X)] \end{equation}\) 那么 SGD 的目标就是求 $g(w)=0$ 的根。
我们能测量到的是: \(\begin{equation} \begin{aligned} \tilde{g}(w, \eta) &= \nabla_w f(w, x) \\ &= \underbrace{\mathbb{E}[\nabla_w f(w, X)]}_{g(w)} + \underbrace{[\nabla_w f(w, x) - \mathbb{E}[\nabla_w f(w, X)]]}_{\eta} \end{aligned} \end{equation}\) 那么,用于求解 $g(w)=0$ 的 RM 算法就是: \(\begin{equation} w_{k+1} = w_k - a_k \tilde{g}(w_k, \eta_k) = w_k - a_k \nabla_w f(w_k, x_k) \end{equation}\) 这正是 SGD 算法。因此,SGD 是 RM 算法的一个特例。由于 SGD 是 RM 算法的特例,其收敛性自然成立。
在 SGD 算法中,如果满足:
-
$0 < c_1 \leq \nabla_w^2 f(w, X) \leq c_2$;
-
$\sum_{k=1}^\infty a_k = \infty$ 且 $\sum_{k=1}^\infty a_k^2 < \infty$;
-
${x_k}_{k=1}^\infty$ 是独立同分布的;
那么 $w_k$ 以概率 1 收敛到 $\nabla_w \mathbb{E}[f(w, X)] = 0$ 的根。
4. 收敛模式
问题:由于随机梯度是随机的,近似不准确,SGD 的收敛是否缓慢或随机?
为了回答这个问题,我们考虑随机梯度和批量梯度之间的相对误差: \(\begin{equation} \delta_k \doteq \frac{\left| \nabla_w f(w_k, x_k) - \mathbb{E}\left[ \nabla_w f(w_k, X) \right] \right|}{\left| \mathbb{E}\left[ \nabla_w f(w_k, X) \right] \right|} \end{equation}\)
由于 $\mathbb{E}[\nabla_w f(w^*, X)] = 0$,我们可以进一步写出: \(\begin{equation} \delta_k = \frac{|\nabla_w f(w_k, x_k) - \mathbb{E}[\nabla_w f(w_k, X)]|}{|\mathbb{E}[\nabla_w f(w_k, X)] - \mathbb{E}[\nabla_w f(w^*, X)]|} = \frac{|\nabla_w f(w_k, x_k) - \mathbb{E}[\nabla_w f(w_k, X)]|}{|\mathbb{E}[\nabla_w^2 f(\tilde{w}_k, X) (w_k - w^*)]|} \end{equation}\) 其中最后一个等式是由中值定理得到的,且 $\tilde{w}_k \in [w_k, w^*]$。
假设 $f$ 是严格凸的,使得对所有 $w, X$,有 $\nabla_w^2 f \geq c > 0$,其中 $c$ 是一个正常数。那么,$\delta_k$ 的分母变为: \(\begin{equation} \begin{aligned} \left| \mathbb{E}\left[ \nabla_w^2 f(\tilde{w}_k, X) (w_k - w^*) \right] \right| &= \left| \mathbb{E}\left[ \nabla_w^2 f(\tilde{w}_k, X) \right] (w_k - w^*) \right| \\ &= \left| \mathbb{E}\left[ \nabla_w^2 f(\tilde{w}_k, X) \right] \right| \left| (w_k - w^*) \right| \geq c |w_k - w^*| \end{aligned} \end{equation}\) 将上述不等式代入 $\delta_k$ 得到: \(\begin{equation} \delta_k \leq \frac{\left| \nabla_w f(w_k, x_k) - \mathbb{E}\left[ \nabla_w f(w_k, X) \right] \right|}{c \left| w_k - w^* \right|} \end{equation}\) 也就是说: \(\begin{equation} \delta_k \leq \frac{|\text{随机梯度} - \text{真实梯度}|}{\underbrace{c |w_k - w^*|}_{\text{到最优解的距离} }} \end{equation}\)
这个方程揭示了 SGD 的一个有趣的收敛模式:
- 相对误差 $\delta_k$ 与 $|w_k - w^*|$ 成反比。
- 当 $|w_k - w^*|$ 很大时(即离最优解很远),$\delta_k$ 很小,SGD 的表现类似于 GD(确定性梯度下降)。
- 当 $w_k$ 接近 $w^*$ 时,相对误差可能很大,收敛在 $w^*$ 附近表现出更多的随机性。
5. 确定性情形的形式化
我们上面介绍的 SGD 公式涉及随机变量和期望。有时会遇到 SGD 的确定性公式,不涉及任何随机变量。
考虑优化问题: \(\begin{equation} \min_w J(w) = \frac{1}{n} \sum_{i=1}^n f(w, x_i) \end{equation}\)
- $f(w, x_i)$ 是一个参数化函数。
- $w$ 是要优化的参数。
- ${x_i}_{i=1}^n$ 是一组实数,其中 $x_i$ 不一定是任何随机变量的样本。
用于求解此问题的梯度下降算法是: \(\begin{equation} w_{k+1} = w_k - \alpha_k \nabla_w J(w_k) = w_k - \alpha_k \frac{1}{n} \sum_{i=1}^n \nabla_w f(w_k, x_i) \end{equation}\)
假设集合很大,我们每次只能获取单个数字。在这种情况下,我们可以使用以下迭代算法: \(\begin{equation} w_{k+1} = w_k - \alpha_k \nabla_w f(w_k, x_k) \end{equation}\)
问题:
- 这个算法是 SGD 吗?它不涉及任何随机变量或期望值。
- 我们应该如何使用有限集合 ${x_i}_{i=1}^n$?我们应该按某种顺序对这些数字进行排序然后逐个使用?还是应该从集合中随机抽取一个数字?
对上述问题的快速回答是,我们可以手动引入一个随机变量,并将确定性公式转换为 SGD 的随机公式。具体来说,假设 $X$ 是一个定义在集合 ${x_i}_{i=1}^n$ 上的随机变量。假设其概率分布是均匀的,使得
\(\begin{equation} p(X = x_i) = 1/n \end{equation}\) 那么,确定性优化问题就变成了一个随机优化问题: \(\begin{equation} \min_w J(w) = \frac{1}{n} \sum_{i=1}^n f(w, x_i) = \mathbb{E}[f(w, X)] \end{equation}\) 上面等式中的最后一个等号是严格的,而不是近似的。因此,该算法就是 SGD。如果 $x_k$ 是从 ${x_i}_{i=1}^n$ 中均匀独立地抽样得到的,那么估计值就会收敛。由于是随机抽样,$x_k$ 可能重复取到 ${x_i}_{i=1}^n$ 中的同一个数。
四、BGD、MBGD 和 SGD 的比较
假设给定一组 $X$ 的随机样本 ${x_i}_{i=1}^n$,我们想最小化 $J(w) = \mathbb{E}[f(w, X)]$。解决这个问题的 BGD、SGD 和 MBGD 算法分别如下:
-
BGD: \(\begin{equation} w_{k+1} = w_k - \alpha_k \frac{1}{n} \sum_{i=1}^n \nabla_w f(w_k, x_i) \end{equation}\)
-
MBGD: \(\begin{equation} w_{k+1} = w_k - \alpha_k \frac{1}{m} \sum_{j \in \mathcal{I}_k} \nabla_w f(w_k, x_j) \end{equation}\)
-
SGD: \(\begin{equation} w_{k+1} = w_k - \alpha_k \nabla_w f(w_k, x_k) \end{equation}\)
-
在 BGD 算法中,每次迭代使用所有样本。当 $n$ 很大时,$\frac{1}{n} \sum_{i=1}^n \nabla_w f(w_k, x_i)$ 接近真实梯度 $\mathbb{E}[\nabla_w f(w_k, X)]$。
-
在 MBGD 算法中,$\mathcal{I}_k$ 是 ${1, \ldots, n}$ 的一个子集,其大小为 $m = |\mathcal{I}_k|$。集合 $\mathcal{I}_k$ 是通过 $m$ 次独立同分布抽样获得的。
-
在 SGD 算法中,$x_k$ 是在时刻 $k$ 从 ${x_i}_{i=1}^n$ 中随机抽样得到的。
MBGD 与 BGD 和 SGD 的比较:
- 与 SGD 相比,MBGD 的随机性较小,因为它使用了更多样本,而不是像 SGD 那样只用一个样本。
- 与 BGD 相比,MBGD 不需要在每次迭代中使用所有样本,使其更加灵活和高效。
- 如果 $m=1$,MBGD 变成 SGD。
- 如果 $m=n$,严格来说 MBGD 并不会变成 BGD,因为 MBGD 使用随机获取的 $n$ 个样本,而 BGD 使用所有 $n$ 个数。特别是,MBGD 可能多次使用 ${x_i}_{i=1}^n$ 中的一个值,而 BGD 每个数只使用一次。
均值估计的示例:
给定一些数字 ${x_i}_{i=1}^n$,我们的目标是计算均值 $\bar{x} = \sum_{i=1}^n x_i / n$。这个问题可以等价地表述为以下优化问题: \(\begin{equation} \min_w J(w) = \frac{1}{2n} \sum_{i=1}^n \| w - x_i \|^2 \end{equation}\)
用于解决此问题的三种算法分别是:
-
BGD: \(\begin{equation} w_{k+1} = w_k - \alpha_k \frac{1}{n} \sum_{i=1}^n (w_k - x_i) = w_k - \alpha_k (w_k - \bar{x}) \end{equation}\)
-
MBGD: \(\begin{equation} w_{k+1} = w_k - \alpha_k \frac{1}{m} \sum_{j \in \mathcal{I}_k} (w_k - x_j) = w_k - \alpha_k (w_k - \bar{x}_k^{(m)}) \end{equation}\)
-
SGD: \(\begin{equation} w_{k+1} = w_k - \alpha_k (w_k - x_k) \end{equation}\)
其中 $\bar{x}_k^{(m)} = \sum_{j \in \mathcal{I}_k} x_j / m$。此外,如果 $\alpha_k = 1/k$,上述方程可以求解为:
-
BGD: \(\begin{equation} w_{k+1} = \frac{1}{k} \sum_{j=1}^k \bar{x} = \bar{x} \end{equation}\) 这意味着 BGD 在每一步的估计值恰好就是最优解 $w^* = \bar{x}$。
-
MBGD: \(\begin{equation} w_{k+1} = \frac{1}{k} \sum_{j=1}^k \bar{x}_j^{(m)} \end{equation}\)
-
SGD: \(\begin{equation} w_{k+1} = \frac{1}{k} \sum_{j=1}^k x_j \end{equation}\)
MBGD 的估计值比 SGD 更快地趋近于均值,因为 $\bar{x}_k^{(m)}$ 本身就是一个平均值。
五、总结
-
均值估计:使用 ${x_k}$ 计算 $\mathbb{E}[X]$ \(\begin{equation} w_{k+1} = w_k - \frac{1}{k} (w_k - x_k) \end{equation}\)
-
RM 算法:使用 ${\tilde{g}(w_k, \eta_k)}$ 求解 $g(w)=0$ \(\begin{equation} w_{k+1} = w_k - a_k \tilde{g}(w_k, \eta_k) \end{equation}\)
-
SGD 算法:使用 ${\nabla_w f(w_k, x_k)}$ 最小化 $J(w) = \mathbb{E}[f(w, X)]$ \(\begin{equation} w_{k+1} = w_k - \alpha_k \nabla_w f(w_k, x_k) \end{equation}\)
这些结果很有用:
- 我们将在下一章看到,时序差分学习算法可以被视为随机近似算法,因此具有类似的表达式。
- 它们是可以应用于许多其他领域的重要优化技术。