【论文解读】Flash Attention
Categories: Paper
目录
概览
Transformer 中 self-attention 的时间和内存复杂度为 $O(N^2)$($N$ 为序列长度),成为处理长序列的瓶颈。大量近似 attention 方法虽然将 FLOP 降到了线性或近线性,但往往无法实现真正的 wall-clock 加速。其原因在于,它们只关注 FLOP 数量的减少,忽略了内存访问(IO)开销——而在现代 GPU 上,计算速度已远超内存带宽,大多数 Transformer 操作实际上是 memory-bound 的。
本文提出 FlashAttention,一种 IO-aware 的精确 attention 算法。其核心思想是通过 tiling(分块计算)和 recomputation(反向传播时重计算)两个技术,避免将 $N \times N$ 的 attention 矩阵写入 GPU HBM(高带宽内存),从而大幅减少 HBM 读写次数。FlashAttention 在保持精确计算的同时,实现了线性内存复杂度和显著的速度提升,其 HBM 访问复杂度为 $O(N^2 d^2 M^{-1})$,并被证明是渐近最优的。
原文链接:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
本文源于 Flash Attention V1,暂时仅关注基本原理和前向部分。
一、预备知识
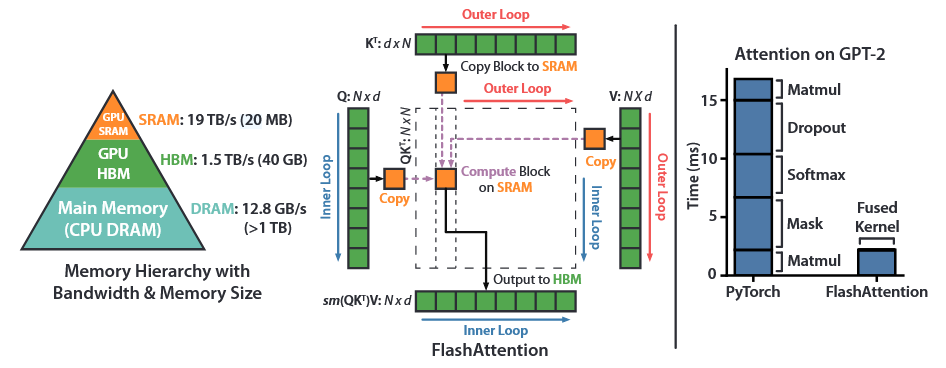
(一)GPU 内存层级与 IO 瓶颈
1. 内存层级
GPU 内存是分层的,不同层级在容量和带宽上差异巨大。以 A100 GPU 为例:
| 层级 | 带宽 | 容量 |
|---|---|---|
| SRAM(片上) | ~19 TB/s | ~20 MB(每个 SM 192 KB,共 108 个 SM) |
| HBM(高带宽内存) | 1.5~2.0 TB/s | 40~80 GB |
| DRAM(CPU 主存) | ~12.8 GB/s | >1 TB |
SRAM 的带宽比 HBM 快约一个数量级,但容量小了三个数量级。在实际计算中,数据需要从 HBM 加载到 SRAM/寄存器,计算完成后再写回 HBM。因此,HBM 的读写次数往往决定了操作的实际运行时间。
2. Compute-bound vs Memory-bound
根据计算量与内存访问量的比值(即 arithmetic intensity,每字节内存访问所执行的算术运算数量),操作可以分为两类:
- Compute-bound(计算受限):运行时间主要由算术运算量决定,内存访问时间相对较小。典型例子是内部维度较大的矩阵乘法、通道数较多的卷积。
- Memory-bound(内存受限):运行时间主要由内存访问次数决定,计算时间相对较小。典型例子是逐元素操作(activation、dropout)和归约操作(sum、softmax、layer norm)。
Transformer 中的大多数操作——特别是 softmax、dropout、masking 等——都是 memory-bound 的。这意味着即使我们减少了 FLOP 数量,如果没有减少 HBM 访问次数,也可能看不到实际的加速效果。
3. Kernel Fusion
Kernel fusion 是减少内存访问的常用手段:如果多个操作作用于相同的输入,可以将它们融合到一个 GPU kernel 中,从 HBM 加载一次数据,在 SRAM 上完成所有计算,然后一次性写回结果,而不是每个操作各自读写 HBM。
(二)标准 Attention 实现及其 IO 分析
1. 标准 Attention 计算
给定输入 $\mathbf{Q}, \mathbf{K}, \mathbf{V} \in \mathbb{R}^{N \times d}$,其中 $N$ 为序列长度,$d$ 为 head 维度,标准 attention 计算如下(略去 scale):
\[\begin{equation} \mathbf{S} = \mathbf{Q}\mathbf{K}^\top \in \mathbb{R}^{N \times N}, \quad \mathbf{P} = \text{softmax}(\mathbf{S}) \in \mathbb{R}^{N \times N}, \quad \mathbf{O} = \mathbf{P}\mathbf{V} \in \mathbb{R}^{N \times d} \end{equation}\]其中 softmax 按行应用,标准实现需要将 $\mathbf{S}$ 和 $\mathbf{P}$ 完整地写入 HBM,占用 $O(N^2)$ 内存。
2. HBM 访问量分析
标准实现分为三步,我们逐步分析每步的 HBM 访问:
第一步:计算 $\mathbf{S} = \mathbf{Q}\mathbf{K}^\top$
- 从 HBM 读取 $\mathbf{Q}, \mathbf{K}$:共 $2Nd$ 个元素 → $O(Nd)$ 次读取
- 将结果 $\mathbf{S}$ 写入 HBM:$N^2$ 个元素 → $O(N^2)$ 次写入
第二步:计算 $\mathbf{P} = \text{softmax}(\mathbf{S})$
- 从 HBM 读取 $\mathbf{S}$:$N^2$ 个元素 → $O(N^2)$ 次读取
- 将结果 $\mathbf{P}$ 写入 HBM:$N^2$ 个元素 → $O(N^2)$ 次写入
第三步:计算 $\mathbf{O} = \mathbf{P}\mathbf{V}$
- 从 HBM 读取 $\mathbf{P}, \mathbf{V}$:$N^2 + Nd$ 个元素 → $O(N^2 + Nd)$ 次读取
- 将结果 $\mathbf{O}$ 写入 HBM:$Nd$ 个元素 → $O(Nd)$ 次写入
总 HBM 访问量为 $O(Nd + N^2)$。在典型设置下 $N \gg d$,$N^2$ 项占主导地位。此外,masking 和 dropout 等操作需要对 $\mathbf{S}$ 或 $\mathbf{P}$ 做逐元素操作,进一步增加 HBM 访问。
(三)Online Softmax
FlashAttention 想要分块计算 attention,但 softmax 是一个全局操作——对于 $\mathbf{Q}$ 的第 $i$ 行,softmax 需要遍历整行 $\mathbf{S}_{i:}$(即该 query 与所有 key 的点积)来计算最大值 $m$ 和归一化常数 $\ell$。这意味着似乎必须先算出完整的 $\mathbf{S}$ 矩阵才能做 softmax。
Online softmax 技巧解决了这个问题:它允许我们逐块处理输入,每处理一个新块就增量地更新 $m$ 和 $\ell$,最终得到与一次性计算完全相同的结果。
1. 数值稳定的 Softmax
直接计算 $e^{x_i}$ 容易导致数值溢出。因此实践中使用减去最大值的技巧。对于向量 $x \in \mathbb{R}^{B}$,数值稳定的 softmax 定义为:
\[\begin{equation} m(x) := \max_i x_i, \quad f(x) := \begin{bmatrix} e^{x_1 - m(x)} \\ \vdots \\ e^{x_B - m(x)} \end{bmatrix}, \quad \ell(x) := \sum_i f(x)_i, \quad \text{softmax}(x) := \frac{f(x)}{\ell(x)} \end{equation}\]其中:
- $m(x)$:向量 $x$ 中的最大值,用于数值稳定
- $f(x)$:减去最大值后的指数向量,每个元素 $f(x)_i = e^{x_i - m(x)}$,这保证了所有值都 $\leq 1$,不会溢出
- $\ell(x)$:$f(x)$ 的元素和,即归一化常数
- $\text{softmax}(x)$:最终的 softmax 结果,$f(x)$ 除以 $\ell(x)$
2. 两个分块的增量合并推导
现在考虑核心问题:如果我们有两个分块 $x^{(1)}, x^{(2)} \in \mathbb{R}^{B}$,已经分别计算了它们的统计量 $m(x^{(1)}), \ell(x^{(1)})$ 和 $m(x^{(2)}), \ell(x^{(2)})$,如何得到拼接向量 $x = [x^{(1)} \; x^{(2)}] \in \mathbb{R}^{2B}$ 的 softmax?
第一步:合并最大值。 拼接向量的最大值显然是两个分块最大值中较大的那个:
\[\begin{equation} m(x) = \max(m(x^{(1)}), m(x^{(2)})) \label{eq:merge_m} \end{equation}\]第二步:合并指数向量。 对于拼接向量 $x$ 的第 $i$ 个元素(假设 $i$ 在第一个分块中),有:
\[\begin{equation} e^{x_i - m(x)} = e^{x_i - m(x^{(1)})} \cdot e^{m(x^{(1)}) - m(x)} \end{equation}\]第一项 $e^{x_i - m(x^{(1)})}$ 正是 $f(x^{(1)})_i$,即我们已经计算过的值。第二项 $e^{m(x^{(1)}) - m(x)}$ 是一个标量修正因子,用于将旧的最大值 $m(x^{(1)})$ 校正到全局最大值 $m(x)$。因此:
\[\begin{equation} f(x) = \begin{bmatrix} e^{m(x^{(1)}) - m(x)} f(x^{(1)}) \\ e^{m(x^{(2)}) - m(x)} f(x^{(2)}) \end{bmatrix} \label{eq:merge_f} \end{equation}\]第三步:合并归一化常数。 将上式的所有分量求和: \(\begin{equation} \ell(x) = e^{m(x^{(1)}) - m(x)} \ell(x^{(1)}) + e^{m(x^{(2)}) - m(x)} \ell(x^{(2)}) \label{eq:merge_ell} \end{equation}\)
第四步:得到 softmax。 最终: \(\begin{equation} \text{softmax}(x) = \frac{f(x)}{\ell(x)} \label{eq:merge_softmax} \end{equation}\)
上述过程的关键在于:只要维护额外统计量 $(m, \ell)$,就可以逐块处理输入并正确合并。这个技巧可以推广到任意多个分块——每来一个新块,只需按照公式 $\eqref{eq:merge_m}$、$\eqref{eq:merge_ell}$ 更新统计量。
3. 推广到多个分块
上面推导了两个分块的合并,但实际上 FlashAttention 需要处理任意多个分块。假设我们已经处理了前 $j-1$ 个分块,维护了到目前为止的全局统计量 $m^{(j-1)}, \ell^{(j-1)}$。现在来了第 $j$ 个分块,其局部统计量为 $\tilde{m}_j, \tilde{\ell}_j$。更新规则完全相同:
\[\begin{equation} m^{(j)} = \max(m^{(j-1)}, \tilde{m}_j), \quad \ell^{(j)} = e^{m^{(j-1)} - m^{(j)} } \ell^{(j-1)} + e^{\tilde{m}_j - m^{(j)} } \tilde{\ell}_j \end{equation}\]这样,不管有多少个分块,我们始终只需要维护 $m$ 和 $\ell$ 两个统计量,每来一个新块就更新一次。
二、FlashAttention 前向传播
上面我们介绍了 Online Softmax,实现了分块计算 Softmax。在实现中,我们还需要分块更新输出。接下来逐行解读论文中的 Algorithm 1:

(一)Line 1-4:初始化与分块
Line 1 — 设置块大小 \(\begin{equation} B_c = \left\lceil \frac{M}{4d} \right\rceil, \quad B_r = \min\left(\left\lceil \frac{M}{4d} \right\rceil, d\right) \end{equation}\)
其中 $M$ 为 SRAM 容量(更准确地说,是当前 kernel 可用的片上存储预算,按元素数计)。这个设置的核心目的不是给出实际工程中的唯一最优块大小,而是在理论分析中保证主要中间量能放进 SRAM。实际实现通常不会机械套用这个公式,而会针对 GPU 架构、head dimension、数据类型和寄存器压力调参。
Line 2 — 初始化 \(\begin{equation} \mathbf{O} = \mathbf{0}_{N \times d}, \quad \ell = \mathbf{0}_N, \quad m = (-\infty)_N \end{equation}\)
- $\mathbf{O}$:累加输出,初始为 0
- $\ell$:归一化常数累积,初始为 0
- $m$:最大值,初始为 $-\infty$(这样第一个块的 $\max(-\infty, \tilde{m}) = \tilde{m}$)
Line 3-4 — 分块
沿序列长度方向,$\mathbf{Q}$ 分为 $T_r = \lceil N / B_r \rceil$ 块,$\mathbf{K}, \mathbf{V}$ 分为 $T_c = \lceil N / B_c \rceil$ 块。$\mathbf{O}, \ell, m$ 也按 $T_r$ 分块。
(二)Line 5-8:双层循环加载数据
Line 5 — 外层循环: $j = 1, \ldots, T_c$,遍历 K/V 块
Line 6: 将 $\mathbf{K}_j, \mathbf{V}_j$ 从 HBM 加载到 SRAM($O(B_c d)$ 次读取)
Line 7 — 内层循环: $i = 1, \ldots, T_r$,遍历 Q 块
Line 8: 将 $\mathbf{Q}_i, \mathbf{O}_i, \ell_i, m_i$ 从 HBM 加载到 SRAM($O(B_r d)$ 次读取)
注意 $\mathbf{O}_i, \ell_i, m_i$ 不是初始值,而是上一轮外层循环更新后的值,用于增量更新。
(三)Line 9-12:片上计算
以下计算全部在 SRAM 中完成,不涉及 HBM 读写。
Line 9 — 计算局部 score 矩阵
$B_r \times d$ 乘以 $d \times B_c$ 的矩阵乘法。 \(\begin{equation} \mathbf{S}_{ij} = \mathbf{Q}_i \mathbf{K}_j^\top \in \mathbb{R}^{B_r \times B_c} \end{equation}\)
Line 10 — 计算局部 softmax 统计量
对 $\mathbf{S}_{ij}$ 的每行取最大值。 \(\begin{equation} \tilde{m}_{ij} = \text{rowmax}(\mathbf{S}_{ij}) \in \mathbb{R}^{B_r} \end{equation}\)
每行减去该行最大值后取指数。这是未归一化的 softmax,还没有除以分母。
\[\begin{equation} \tilde{\mathbf{P} }_{ij} = \exp(\mathbf{S}_{ij} - \tilde{m}_{ij}) \in \mathbb{R}^{B_r \times B_c} \end{equation}\]每行求和,得到局部分母。
\[\begin{equation} \tilde{\ell}_{ij} = \text{rowsum}(\tilde{\mathbf{P} }_{ij}) \in \mathbb{R}^{B_r} \end{equation}\]Line 11 — 更新全局最大值和归一化常数
全局 max 是已处理各块 max 的最大值。 \(\begin{equation} m_i^{\text{new} } = \max(m_i, \tilde{m}_{ij}) \end{equation}\)
将旧分母和新分母都 rescale 到新的全局 max 后相加。这就是第一节中 online softmax 的公式 $\eqref{eq:merge_ell}$。
\[\begin{equation} \ell_i^{\text{new} } = e^{m_i - m_i^{\text{new} }} \ell_i + e^{\tilde{m}_{ij} - m_i^{\text{new} }} \tilde{\ell}_{ij} \end{equation}\]Line 12 — 更新输出 \(\begin{equation} \mathbf{O}_i \leftarrow \text{diag}(\ell_i^{\text{new} })^{-1} \left( \text{diag}(\ell_i) e^{m_i - m_i^{\text{new} }} \mathbf{O}_i + e^{\tilde{m}_{ij} - m_i^{\text{new} }} \tilde{\mathbf{P} }_{ij} \mathbf{V}_j \right) \end{equation}\)
这一步可以先用一句话理解:旧的 $\mathbf{O}_i$ 已经除过旧分母 $\ell_i$,因此需要先乘回旧分母,把旧结果还原成“未归一化分子”;然后把旧分子和新分块贡献都 rescale 到同一个新最大值 $m_i^{\text{new} }$ 下;最后再除以新分母 $\ell_i^{\text{new} }$。
逐步拆解:
-
$\text{diag}(\ell_i) \cdot \mathbf{O}_i$:反归一化。$\mathbf{O}_i$ 是归一化的输出,乘回 $\ell_i$ 得到未归一化的部分输出 $\tilde{o}_i^{\text{old} } = \ell_i \cdot o_i^{\text{old} }$。
-
$e^{m_i - m_i^{\text{new} }} \cdot (\ldots)$:rescale。全局 max 从 $m_i$ 变为 $m_i^{\text{new} }$,旧的指数项 $e^{s - m_i}$ 变为 $e^{s - m_i^{\text{new} }} = e^{s - m_i} \cdot e^{m_i - m_i^{\text{new} }}$,因此整体乘以 $e^{m_i - m_i^{\text{new} }}$。
-
$e^{\tilde{m}_{ij} - m_i^{\text{new} }} \tilde{\mathbf{P} }_{ij} \mathbf{V}_j$:新块贡献。$\tilde{\mathbf{P} }_{ij} \mathbf{V}_j$ 是 $B_r \times B_c$ 乘 $B_c \times d$ 的矩阵乘法,rescale 到全局 max。
-
$\text{diag}(\ell_i^{\text{new} })^{-1} \cdot (\ldots)$:重新归一化。两部分相加后用新分母归一化。
(四)Line 13-16:写回与返回
Line 13: 将 $\mathbf{O}_i, \ell_i^{\text{new} }, m_i^{\text{new} }$ 写回 HBM($O(B_r d)$ 次写入)
Line 14-16: 结束循环,返回 $\mathbf{O}$
当所有 $T_c$ 个 K/V 块处理完毕,$\mathbf{O}$ 就是 $\text{softmax}(\mathbf{QK}^\top)\mathbf{V}$。
三、循环顺序:FlashAttention v1 与 FlashAttention v2
上面解读的是 FlashAttention 最初论文中的 Algorithm 1。它的循环顺序是:
for each K/V block j:
load K_j, V_j
for each Q block i:
load Q_i, O_i, l_i, m_i
update O_i, l_i, m_i
write back
这个写法的好处是:一次加载 $\mathbf{K}_j,\mathbf{V}_j$ 后,可以复用它们去更新所有 Q block。代价是:每个 $\mathbf{O}_i,\ell_i,m_i$ 会随着外层 K/V block 反复从 HBM 读写。
FlashAttention v2 对 forward 的循环顺序做了调整,更接近:
for each Q block i:
keep O_i, l_i, m_i on chip
for each K/V block j:
load K_j, V_j
update O_i, l_i, m_i
write O_i once
这样不同 Q block 可以更自然地分给不同 thread block 并行处理,同时减少 $\mathbf{O}_i,\ell_i,m_i$ 的反复读写。
四、总结
FlashAttention 的前向本质可以概括为两点:
- Tiling:一次只处理一小块 Q/K/V,让中间 score 和 probability tile 留在片上存储中。
- Online softmax:用 $m,\ell$ 增量维护每一行 softmax 的全局最大值和归一化常数。
局限性方面:FlashAttention 对 kernel 实现要求很高,复杂 attention 变体通常需要专门适配;性能也不完全可移植,往往要针对不同 GPU 架构、head dimension 和数据类型重新调参。