【论文解读】DeepSeek-V4
Categories: Paper
目录
- 概览
- 一、模型架构
- 二、基础设施
- 三、预训练
- 四、后训练
- 五、实验结果
- 六、总结
概览
DeepSeek-V4 系列是 DeepSeek-AI 推出的下一代大语言模型,包括 DeepSeek-V4-Pro(1.6T 参数,49B 激活)和 DeepSeek-V4-Flash(284B 参数,13B 激活),均原生支持一百万 token 的上下文长度。其核心贡献在于:通过混合注意力架构(CSA + HCA)大幅提升超长上下文的计算效率——在 1M token 场景下,DeepSeek-V4-Pro 的单 token 推理 FLOPs 仅为 DeepSeek-V3.2 的 27%,KV cache 仅为 10%。
DeepSeek-V4 系列在模型架构和优化方法上包含几项关键升级。第一,它采用一种混合 attention 架构,将 Compressed Sparse Attention(CSA)和 Heavily Compressed Attention(HCA)结合起来,以提升长上下文效率。第二,它引入 Manifold-Constrained Hyper-Connections(mHC),用于增强传统 residual connection。第三,它使用 Muon optimizer,以获得更快收敛和更高训练稳定性。在后训练阶段,采用领域专家独立训练 + On-Policy Distillation (OPD) 的两阶段范式。DeepSeek-V4-Pro-Max 在多项基准上重新定义了开源模型的 SOTA。
原文链接:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
从零手撕和训练一个 Mini DeepSeek-V4 ,参考本人仓库:Mini-LLM
一、模型架构
总体而言,DeepSeek-V4 系列保留 Transformer 架构和 Multi-Token Prediction(MTP)模块,同时相对 DeepSeek-V3 引入若干关键升级。第一,引入了 Manifold-Constrained Hyper-Connections(mHC)来强化传统 residual connections。第二,设计了一种混合 attention 架构,通过 Compressed Sparse Attention 和 Heavily Compressed Attention 显著提升长上下文效率。第三,使用 Muon 作为 optimizer。对于 Mixture-of-Experts(MoE)组件,仍采用 DeepSeekMoE 架构,只相对 DeepSeek-V3 做少量调整,MTP 配置与 DeepSeek-V3 完全一致。所有未特别说明的细节都沿用 DeepSeek-V3 的设置。下图为 DeepSeek-V4 的整体架构:
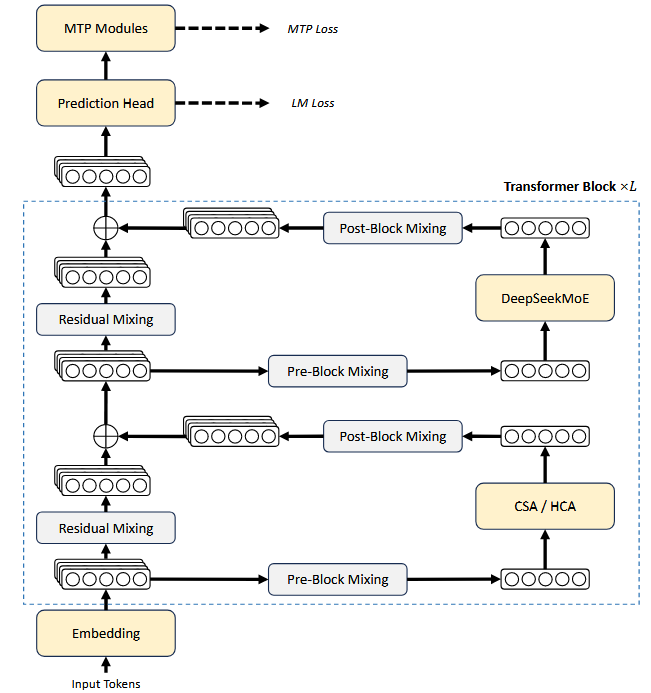
(一)DeepSeek-V3 继承设计
1. Mixture-of-Experts
DeepSeek-V4 沿用了 DeepSeekMoE 范式,其核心特点是设置细粒度的路由专家和共享专家。每个 MoE 层包含 1 个共享专家和数百个路由专家(V4-Flash 为 256 个,V4-Pro 为 384 个),每个 token 激活 6 个路由专家。
与 DeepSeek-V3 的不同之处在于:
- 激活函数从 $\text{Sigmoid}(\cdot)$ 改为 $\sqrt{\text{Softplus}(\cdot)}$,其中 $\text{Softplus}(x) = \log (1+e^x)$
- 仍然采用无辅助损失的负载均衡策略,并辅以轻量的序列级辅助损失,但取消了对路由目标节点数量的约束,并重新精心设计并行策略,以维持训练效率
- 相比 DeepSeek-V3,把初始几层的 dense FFN 替换为使用 Hash routing 的 MoE 层(根据 token ID 的哈希函数确定目标专家)
2. Multi-Token Prediction
鉴于 MTP 模块已在 DeepSeek-V3 中得到验证,DeepSeek-V4 的 MTP 模块和目标函数与 DeepSeek-V3 完全一致,预测深度设为 1。
(二)流形约束超连接
本小节也可参考 mHC 论文解读:DeepSeek mHC
DeepSeek-V4 引入 Manifold-Constrained Hyper-Connections(mHC),用于强化传统残差连接。与 Hyper-Connections(HC)相比,mHC 的核心思想是把残差映射矩阵约束到特定流形上,从而在保持模型表达力的同时增强跨层信号传递的稳定性。
1. 标准 Hyper-Connections
标准 HC 将残差流的宽度扩展 $n_{\mathrm{hc} }$ 倍。具体来说,残差状态的形状从 $\mathbb{R}^d$ 扩展为 $\mathbb{R}^{n_{\mathrm{hc} } \times d}$,其中 $d$ 是层输入的隐藏维度。设第 $l$ 层之前的残差状态为:
\[\begin{equation} X_l = [\mathbf{x}_{l,1}; \ldots; \mathbf{x}_{l,n_{\mathrm{hc} }}]^T \in \mathbb{R}^{n_{\mathrm{hc} } \times d} \end{equation}\]HC 引入三个线性映射:
- 输入映射 $A_l \in \mathbb{R}^{1 \times n_{\mathrm{hc} }}$:将扩展的残差状态压缩为 $d$ 维的实际层输入
- 残差变换 $B_l \in \mathbb{R}^{n_{\mathrm{hc} } \times n_{\mathrm{hc} }}$:变换残差流自身
- 输出映射 $C_l \in \mathbb{R}^{n_{\mathrm{hc} } \times 1}$:将层输出扩展回 $n_{\mathrm{hc} } \times d$
残差状态的更新公式为:
\[\begin{equation} X_{l+1} = B_l X_l + C_l \mathcal{F}_l(A_l X_l) \end{equation}\]其中 $\mathcal{F}_l$ 表示第 $l$ 层,它的输入和输出形状都是 $\mathbb{R}^d$。因此实际层输入 $A_l X_l \in \mathbb{R}^d$ 仍然是 $d$ 维的,扩展的残差宽度不影响内部层的设计。HC 将残差宽度与实际隐藏维度解耦,以极小的计算开销($n_{\mathrm{hc} }$ 通常远小于 $d$)提供了一个互补的扩展维度。
然而,HC 在多层堆叠时训练会频繁出现数值不稳定,阻碍了其规模化应用。
2. 流形约束的残差映射
mHC 的核心创新是将残差映射矩阵 $B_l$ 约束到双随机矩阵的流形,也就是 Birkhoff 多面体 $\mathcal{M}$ 上:
\[\begin{equation} B_l \in \mathcal{M} := \{M \in \mathbb{R}^{n \times n} \mid M\mathbf{1}_n = \mathbf{1}_n, \; \mathbf{1}_n^T M = \mathbf{1}_n^T, \; M \geqslant 0\} \label{eq:birkhoff} \end{equation}\]双随机矩阵的每一行和每一列之和都等于 1,且所有元素非负。这个约束确保了映射矩阵的谱范数 $|B_l|_2$ 有界于 1,使得残差变换是非扩张的(non-expansive),从而增强了前向和反向传播中的数值稳定性。双随机矩阵集合 $\mathcal{M}$ 在乘法下是封闭的——两个双随机矩阵的乘积仍然是双随机矩阵。这保证了多层 mHC 深度堆叠时的稳定性,这是比单层约束更强的性质。此外,输入变换 $A_l$ 和输出变换 $C_l$ 也通过 Sigmoid 函数约束为非负有界,避免信号抵消的风险。
3. 动态参数化
三个线性映射的参数是动态生成的,分解为依赖输入的动态分量和不依赖输入的静态分量。给定输入 $X_l \in \mathbb{R}^{n_{\mathrm{hc} } \times d}$,首先将其展平并归一化:
\[\begin{equation} \hat{X}_l = \text{RMSNorm}(\text{vec}(X_l)) \in \mathbb{R}^{1 \times n_{\mathrm{hc} }d} \end{equation}\]然后沿用常规 HC 的方式,生成未经约束的原始参数 $\tilde{A}_l \in \mathbb{R}^{1 \times n_{hc} }, \tilde{B}_l \in \mathbb{R}^{n_{hc} \times n_{hc} }, \tilde{C}_l \in \mathbb{R}^{n_{hc} \times 1}$:
\[\begin{align} \tilde{A}_l &= \alpha_l^{\mathrm{pre} } \cdot (\hat{X}_l W_l^{\mathrm{pre} }) + S_l^{\mathrm{pre} } \\ \tilde{B}_l &= \alpha_l^{\mathrm{res} } \cdot \text{Mat}(\hat{X}_l W_l^{\mathrm{res} }) + S_l^{\mathrm{res} } \\ \tilde{C}_l &= \alpha_l^{\mathrm{post} } \cdot (\hat{X}_l W_l^{\mathrm{post} })^T + S_l^{\mathrm{post} } \end{align}\]其中 $W_l^{\mathrm{pre} }, W_l^{\mathrm{post} } \in \mathbb{R}^{n_{\mathrm{hc} }d \times n_{\mathrm{hc} }}$ 和 $W_l^{\mathrm{res} } \in \mathbb{R}^{n_{\mathrm{hc} }d \times n_{\mathrm{hc} }^2}$ 是可学习参数;$\text{Mat}(\cdot)$ 将 $1 \times n_{\mathrm{hc} }^2$ 的向量重塑为 $n_{\mathrm{hc} } \times n_{\mathrm{hc} }$ 的矩阵;$S_l^{\mathrm{pre} } \in \mathbb{R}^{1 \times n_{hc} }, S_l^{\mathrm{res} } \in \mathbb{R}^{n_{hc} \times n_{hc} }, S_l^{\mathrm{post} } \in \mathbb{R}^{n_{hc} \times 1}$ 是静态偏置;$\alpha_l^{\mathrm{pre} }, \alpha_l^{\mathrm{res} }, \alpha_l^{\mathrm{post} } \in \mathbb{R}$ 是初始化为小值的可学习门控因子。
4. 施加参数约束
得到原始参数 $\tilde{A}_l,\tilde{B}_l,\tilde{C}_l$ 之后,对它们施加前述约束以增强数值稳定性。对于输入和输出映射,使用 Sigmoid 函数确保非负性和有界性:
\[\begin{equation} A_l = \sigma(\tilde{A}_l), \quad C_l = 2\sigma(\tilde{C}_l) \end{equation}\]这里为什么 $\tilde{A}_l$ 使用 $\sigma$ 而 $\tilde{C}_l$ 使用 $2\sigma$?可能的原因是:前者更像是读入时各 stream 的加权,用于把 n 条 stream 聚合成一个 layer input,它是一个多到一的过程, $\sigma$ 使权重落在 0 到 1 之间,防止聚合爆炸。后者更像是把一个 layer output 写回各 stream,默认强度与标准 residual 一致,是一个一到多的过程,零初始化时,$2\sigma$ 会使得权重在 1 附近。具体可以参见 mHC 原论文的 Table 1 中,做消融实验时对 fixed mapping 的对比设置。
对于残差映射 $\tilde{B}_l$,通过 Sinkhorn-Knopp 算法将其投影到双随机矩阵流形 $\mathcal{M}$ 上。首先对 $\tilde{B}_l$ 取指数确保为正:$M^{(0)} = \exp(\tilde{B}_l)$,然后交替进行行归一化和列归一化: \(\begin{equation} M^{(t)} = \mathcal{T}_r(\mathcal{T}_c(M^{(t-1)})) \end{equation}\)
其中 $\mathcal{T}_r$ 和 $\mathcal{T}_c$ 分别表示行归一化和列归一化。迭代会收敛到约束的双随机矩阵 $B_l = M^{(t_{\max})}$,实际中取 $t_{\max} = 20$。
(三)混合注意力架构:CSA + HCA
当上下文长度达到极端规模时,注意力机制成为模型的主要计算瓶颈。DeepSeek-V4 设计了两种高效注意力架构——Compressed Sparse Attention (CSA) 和 Heavily Compressed Attention (HCA)——并以交替方式混合使用,大幅降低长文本场景下的注意力计算开销。
CSA 同时整合 compression 和 sparse attention 策略。它首先把每 $m$ 个 token 的 Key-Value(KV)cache 压缩为一个 entry,然后应用 DeepSeek Sparse Attention(DSA),使每个 query token 只关注 $k$ 个 compressed KV entries。HCA 则面向极端压缩,它把每 $m’(\gg m)$ 个 token 的 KV cache 聚合成一个 entry。
1. Compressed Sparse Attention (CSA)
CSA 的核心结构如下图所示,它首先将每 $m$ 个 token 的 KV cache 压缩为一个 entry,然后对压缩后的 KV entries 应用 DeepSeek Sparse Attention (DSA) 进行稀疏选择进一步加速。
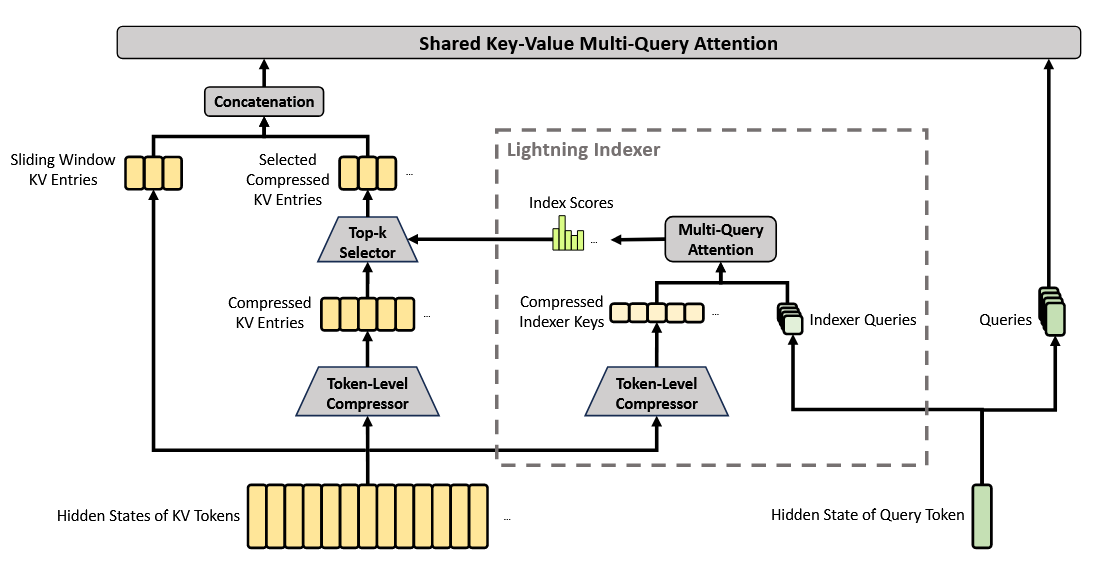
(1)压缩 KV Entries
设 $H \in \mathbb{R}^{n \times d}$ 为输入隐藏状态序列,其中 $n$ 是 sequence length,$d$ 是 hidden size。。CSA 首先计算两组 KV entries $C^a, C^b \in \mathbb{R}^{n \times c}$ 及其对应的压缩权重 $Z^a, Z^b \in \mathbb{R}^{n \times c}$,其中 $c$ 是 head dimension:
\[\begin{align} C^a &= H W^{aKV}, & C^b &= H W^{bKV}\\ Z^a &= H W^{aZ}, & Z^b &= H W^{bZ} \end{align}\]其中 $W^{aKV}, W^{bKV}, W^{aZ}, W^{bZ} \in \mathbb{R}^{d \times c}$ 为可训练参数。接下来,$C^a$ 和 $C^b$ 中每 $m$ 个 KV entries 根据压缩权重和可学习的位置偏置 $B^a, B^b \in \mathbb{R}^{m \times c}$ 压缩为一个 entry,得到 $C^{\text{Comp} } \in \mathbb{R}^{\frac{n}{m} \times c}$。每个压缩 entry $C_i^{\text{Comp} } \in \mathbb{R}^c$ 的计算过程如下:
\[\begin{align} [S_{mi:m(i+1)-1}^a; S_{m(i-1):mi-1}^b] &= \text{Softmax}_{\text{row} }([Z_{mi:m(i+1)-1}^a + B^a; Z_{m(i-1):mi-1}^b + B^b]) \\ C_i^{\text{Comp} } &= \sum_{j=mi}^{m(i+1)-1} S_j^a \odot C_j^a + \sum_{j=m(i-1)}^{mi-1} S_j^b \odot C_j^b \end{align}\]这里 $\odot$ 表示 Hadamard product,$\mathrm{Softmax}_{\mathrm{row} }(\cdot)$ 表示沿 row dimension 执行 softmax,也就是在来自 $Z^a$ 和 $Z^b$ 的总计 $2m$ 个元素上归一化。当 $i=0$ 时,$Z_{m(i-1):mi-1}^b$ 用负无穷填充,$C_{m(i-1):mi-1}^b$ 用 0 填充。这里的关键设计是使用了 $a,b$ 两套分支和重叠压缩:每个压缩 entry $C_i^{\text{Comp} }$ 由 $2m$ 个 KV entries 加权得到,即当前窗口 $[mi, m(i+1)-1]$ 中的 $C^a$ 和前一个窗口 $[m(i-1), mi-1]$ 中的 $C^b$。这种重叠设计使相邻压缩块之间的信息有一定交叉,减少了硬切分导致的信息损失,压缩操作将序列长度降为原来的 $\frac{1}{m}$ 倍。
(2)Lightning Indexer 稀疏选择
得到压缩 KV entries $C^{\text{Comp} }$ 后,CSA 使用 DSA 策略从中选择 top-$k$ 个压缩 KV entries 用于核心注意力计算。
首先,CSA 使用与 $C^{\mathrm{Comp} }$ 相同的压缩操作,得到 compressed indexer keys $K^{\mathrm{IComp} }\in\mathbb{R}^{\frac{n}{m}\times c^I}$,其中 $c^I$ 是 indexer head dimension。然后,对查询 token $t$,以低秩方式生成 indexer queries ${\mathbf{q}_{t,1}^I,\ldots,\mathbf{q}_{t,n_h^I}^I}$:
\[\begin{align} \mathbf{c}_t^Q &= \mathbf{h}_t \cdot W^{DQ} \\ [\mathbf{q}_{t,1}^I; \mathbf{q}_{t,2}^I; \ldots; \mathbf{q}_{t,n_h^I}^I] = \mathbf{q}_t^I &= \mathbf{c}_t^Q \cdot W^{IUQ} \end{align}\]其中 $\mathbf{h}_t\in\mathbb{R}^d$ 是 query token $t$ 的 hidden state;$\mathbf{c}_t^Q\in\mathbb{R}^{d_c}$ 是 query 的压缩潜在向量,$d_c$ 是压缩潜在向量的维度;$n_h^I$ 是 indexer query 头数量,$W^{DQ}\in\mathbb{R}^{d\times d_c}$ 与 $W^{IUQ}\in\mathbb{R}^{d_c\times c^In_h^I}$ 分别是 indexer queries 的下投影和上投影矩阵。接下来,query token $t$ 与它之前的 compressed block $s$($s \lt \text{Floor}(\frac{t}{m})$,其中 $\text{Floor}(\frac{t}{m})$ 表示 query token $t$ 当前所在的压缩块的索引)之间的 index score $I_{t,s}\in\mathbb{R}$ 计算为:
\[\begin{align} [w_{t,1}^I;w_{t,2}^I;\ldots;w_{t,n_h^I}^I]&=\mathbf{w}_t^I=\mathbf{h}_t \cdot W^w\\ I_{t,s}&=\sum_{h=1}^{n_h^I}w_{t,h}^I\cdot \mathrm{ReLU}(\mathbf{q}_{t,h}^I\cdot \mathbf{K}_s^{\mathrm{IComp} }) \end{align}\]其中 $W^w \in \mathbb{R}^{d \times n_h^I}$ 是可学习矩阵,$w_{t,h}^I \in \mathbb{R}$ 是第 $h$ 个 indexer head 的权重。对于 query token $t$,给定 index scores $I_{t,:}$ 后,使用 top-$k$ selector 只保留一部分 compressed KV entries,作为后续 attention 的输入:
\[\begin{equation} C_t^{\text{SprsComp} } = \{C_s^{\text{Comp} } \mid I_{t,s} \in \text{Top-k}(I_{t,:})\} \end{equation}\](3)Shared Key-Value MQA
选出稀疏 KV entries 后,CSA 以 Multi-Query Attention (MQA) 方式执行注意力计算,每个 $C_t^{\text{SprsComp} }$ 中的压缩 KV entry 同时充当注意力计算的 key 和 value。具体来说,对 query token $t$,首先从压缩潜在向量 $\mathbf{c}_t^Q$ 中产生出执行注意力计算的 queries:
\[\begin{equation} [\mathbf{q}_{t,1}; \mathbf{q}_{t,2}; \ldots; \mathbf{q}_{t,n_h}] = \mathbf{q}_t = \mathbf{c}_t^Q \cdot W^{UQ} \end{equation}\]其中 $n_h$ 是 query heads 数量,$W^{UQ}\in\mathbb{R}^{d_c\times cn_h}$ 是 query 的上投影矩阵。注意,这里的潜在向量 $\mathbf{c}_t^Q$ 与 indexer queries 使用的潜在向量是共享的。随后,对每个 head 执行:
\[\begin{equation} \mathbf{o}_{t,i} = \text{CoreAttn}(\text{query} = \mathbf{q}_{t,i}, \; \text{key} = C_t^{\text{SprsComp} }, \; \text{value} = C_t^{\text{SprsComp} }) \end{equation}\]因此,这里有两个共享:
a. 执行注意力计算时,key 和 value 均使用的是 $C_t^{\text{SprsComp} }$;
b. 执行注意力计算的 query 和 indexer query 均从潜在向量 $\mathbf{c}_t^Q$ 中产生。
(4)分组输出投影
在 DeepSeek-V4 的配置中,由于 $cn_h$ 很大,因此如果直接将 attention 输出 $[\mathbf{o}_{t,1};\ldots;\mathbf{o}_{t,n_h}]\in\mathbb{R}^{cn_h}$ 投影回 $d$ 维 hidden state,会产生很大计算负担。为降低这部分成本,CSA 采用分组输出投影策略。具体来说,先把 $n_h$ 个输出分成 $g$ 组(即 $n_h$ 个头,每 $\frac{n_h}{g}$ 个头为一组,共 $g$ 组),每组输出 $\mathbf{o}_{t,i}^{G}\in\mathbb{R}^{c\frac{n_h}{g} }$ 会先投影到 $d_g$ 维的中间输出 $\mathbf{o}_{t,i}^{G’}\in\mathbb{R}^{d_g}$,其中 $d_g<c\frac{n_h}{g}$。最后,将 $[\mathbf{o}_{t,1}^{G’};\ldots;\mathbf{o}_{t,g}^{G’}]\in\mathbb{R}^{d_gg}$ 投影为最终的 attention output $\hat{\mathbf{o} }_t\in\mathbb{R}^{d}$。
2. Heavily Compressed Attention (HCA)
HCA 的核心结构如下图所示,它的整体流程与 CSA 类似,但采用更激进的压缩率 $m’(\gg m)$,且不使用稀疏注意力。
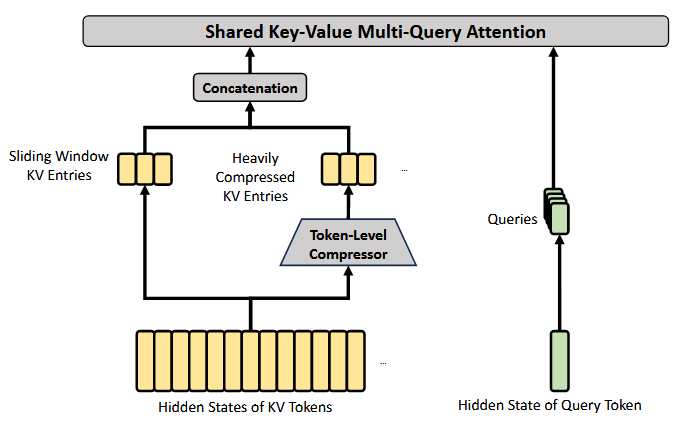
(1)压缩 KV Entries
HCA 的压缩策略与 CSA 类似,但使用更大的压缩率 $m’(\gg m)$,且不执行重叠压缩。令 $H\in\mathbb{R}^{n\times d}$ 为输入 hidden states 序列,HCA 先计算原始 KV entries $C\in\mathbb{R}^{n\times c}$ 和对应的压缩权重 $Z\in\mathbb{R}^{n\times c}$: \(\begin{equation} C=HW^{KV},\qquad Z=HW^Z \end{equation}\) 其中 $W^{KV},W^Z\in\mathbb{R}^{d\times c}$ 是可训练参数。接下来,$C$ 中每 $m’$ 个 KV entries 会根据压缩权重和可学习偏置 $B\in\mathbb{R}^{m’\times c}$ 压缩为一个 entry,得到 $C^{\mathrm{Comp} }\in\mathbb{R}^{\frac{n}{m’}\times c}$。每个 compressed entry 计算为: \(\begin{align} S_{m'i:m'(i+1)-1} &= \text{Softmax}_{\text{row} }(Z_{m'i:m'(i+1)-1} + B) \\ C_i^{\text{Comp} } &= \sum_{j=m'i}^{m'(i+1)-1} S_j \odot C_j \end{align}\)
通过这种压缩,HCA 将序列长度降为原来的 $\frac{1}{m’}$ 倍。
在 V4-Flash 和 V4-Pro 中,$m=4$(CSA),$m’=128$(HCA)。HCA 的压缩率是 CSA 的 32 倍,因此 HCA 层的 KV cache 极小,但使用 dense attention 关注所有的 KV Entries。CSA 则相反,压缩率较低但使用 sparse attention 关注选中的部分 KV Entries。
(2)Shared Key-Value MQA 和分组输出投影
HCA 也像 CSA 一样使用 shared KV MQA 和分组输出投影。KV 压缩后,对于 query token $t$,HCA 同样先以低秩方式生成 attention queries: \(\begin{align} \mathbf{c}_t^Q&=\mathbf{h}_t \cdot W^{DQ}\\ [\mathbf{q}_{t,1};\mathbf{q}_{t,2};\ldots;\mathbf{q}_{t,n_h}]=\mathbf{q}_t&=\mathbf{c}_t^Q \cdot W^{UQ} \end{align}\) 随后,HCA 在 queries ${\mathbf{q}_{t,i}}$ 和全部 $C^{\mathrm{Comp} }$ 上执行 MQA: \(\begin{equation} \mathbf{o}_{t,i}=\mathrm{CoreAttn}(\mathtt{query}=\mathbf{q}_{t,i},\mathtt{key}=C^{\mathrm{Comp} },\mathtt{value}=C^{\mathrm{Comp} }) \end{equation}\) 最后,HCA 与 CSA 一样把 $n_h$ 个输出分为 $g$ 组,每组先投影到 $d_g$ 维中间输出,再合并投影为最终 attention output,这里不再赘述。
3. 其他技术细节
除了上面描述的 CSA 与 HCA 核心结构之外,混合 attention 还包含若干其他技术。为了叙述清晰,前面的介绍省略了这些附加的技术细节,本小节进行一并介绍。
(1)Query 和 KV Entry 的归一化
对 CSA 和 HCA,都会在 core attention 操作之前,对每个 query head 和唯一的 compressed KV entry head 额外执行 RMSNorm。这个 normalization 可以避免 attention logits 爆炸,提升训练稳定性。
(2)部分 RoPE
在 CSA 和 HCA 中,对 attention queries、KV entries 和 core attention outputs 部分使用 RoPE。具体而言,对 CSA/HCA 中使用的每个 query vector 和 KV entry vector,只在最后 64 个维度上应用 RoPE。由于 KV entries 同时作为 attention keys 和 values,因此 core attention outputs ${\mathbf{o}_{t,i}}$ 会携带绝对位置信息(RoPE 是用绝对位置的旋转来编码,因此加权的 KV entries 里是有绝对位置信息的)。因此,还会在每个 $\mathbf{o}_{t,i}$ 的最后 64 个维度上应用位置为 $-t$ 的 RoPE(原文中写的是 position $-i$ 应该是笔误)。这样,core attention 的输出也会携带相对位置信息:每个 KV entry 对 core attention output 的贡献会与 query 和 KV entry 之间的距离相关。
(3)滑动窗口注意力
为了严格保持因果性,CSA 和 HCA 中每个 query 只能 attend 到前面的压缩 KV 块,无法访问当前压缩块内其他 token 的信息。同时,最近的 token 对当前 query 通常最重要。因此,引入一个额外的滑动窗口注意力,具体来说,对于每个 query token,额外生成 $n_{\mathrm{win} }$ 个未压缩 KV entries,对应最近的 $n_{\mathrm{win} }$ 个 token。在 CSA 和 HCA 的 core attention 中,这些 sliding window KV entries 会与 compressed KV entries 一起使用。
(4)Attention Sink
在 CSA 和 HCA 的 core attention 中,我们使用 attention sink 技巧。具体而言,设置一系列可学习 sink logits ${z’_1,\ldots,z’_{n_h}}$。对于第 $h$ 个 attention head,$\exp(z’_h)$ 会被加入 attention score 的分母:
\[\begin{equation} s_{h,i,j} = \frac{\exp(z_{h,i,j})}{\sum_k \exp(z_{h,i,k}) + \exp(z_h')} \end{equation}\]其中 $s_{h,i,j}$ 和 $z_{h,i,j}$ 分别表示第 $h$ 个 attention head 在第 $i$ 个 query token 和第 $j$ 个 preceding token 或 compressed block 之间的 attention score 与 attention logit。这相当于 attention score 的一部分被 sink 吸收了,且这部分不参与 value 加权输出: \(\begin{equation} s_{h,i}^{sink} = \frac{\exp(z_h')}{\sum_k \exp(z_{h,i,k}) + \exp(z_h')} \end{equation}\) 它的作用类似给每个 head 学一个固定的默认空读倾向。如果某个 head 的 $z’_h$ 学得比较大,这个 head 更容易把注意力分给 sink,实际 KV 的 attention weight 总和就更小;如果 $z’_h$ 较小,sink 影响就弱。该技术允许每个 query head 的 total attention scores 不等于 1,甚至接近 0。sink 使得模型可以选择这一头这次不太需要看任何 KV,如果没有 sink 的话,softmax 必须把 1 的权重分配给某些 key,即便它们不那么相关。此外,虽然 $z’_h$ 固定,但 sink 占比不是固定的,因为它还取决于当前 query 对 KV 的 logits。如果当前 token 对 KV 的匹配越强,$\sum_k \exp(z_{h,i,k})$ 越大,sink 占比越小;反之,sink 占比越大。
4. 效率分析
通过混合 CSA 和 HCA,加上低精度计算和存储优化,DeepSeek-V4 的注意力模块在 FLOPs 和 KV cache 大小上都实现了显著的效率提升:
- 混合精度 KV 存储:RoPE 维度使用 BF16,其余维度使用 FP8,相比纯 BF16 减少近一半 KV cache
- FP4 Indexer 计算:Lightning indexer 的注意力计算使用 FP4 精度
- 更小的 attention top-k:相比 V3.2 选择更少的 KV entries
- 压缩注意力:CSA 和 HCA 从根本上减少 KV cache 和 FLOPs
以 BF16 GQA8(head 维度 128)为基线,在 1M 上下文场景下,DeepSeek-V4 的 KV cache 大小约为基线的 2%。
(四)Muon Optimizer
1. 预备知识
首先简要串一下几类优化器的关系:
- SGD 直接使用当前梯度更新参数:
其中 $\eta$ 是学习率,$g_t$ 是当前梯度。
- Momentum 在 SGD 上加入历史梯度累积,使更新方向更平滑:
其中 $m_t$ 是动量项,$\beta$ 是动量系数。
- Adam 进一步维护梯度的一阶矩和二阶矩,为每个参数提供自适应更新尺度:
其中 $m_t$ 是一阶矩,$v_t$ 是二阶矩,$\hat m_t,\hat v_t$ 是 bias correction 后的结果。
- AdamW 将 weight decay 从 Adam 的梯度更新中解耦出来,是当前 Transformer / LLM 训练中最常用的优化器之一:
其中 $\lambda$ 是 weight decay 系数。
- Muon 则走了另一条思路:它不主要做逐元素自适应缩放,而是针对二维矩阵参数,对 momentum update 矩阵做正交化,使更新矩阵的奇异值更加均衡。其基本形式可以写成:
DeepSeek-V4 中使用的是带 Nesterov trick、Hybrid Newton-Schulz、RMS rescale 和 decoupled weight decay 的 Muon 变体:
\[\begin{equation} \begin{aligned} O'_t &=\text{HybridNewtonSchulz}(\mu M_t+G_t) \\ O_t &=O'_t\cdot \sqrt{\max(n,m)}\cdot \gamma \\ W_t &=W_{t-1}(1-\eta\lambda)-\eta O_t \end{aligned} \end{equation}\]2. 基本配置
DeepSeek-V4 对以下模块仍使用 AdamW:
- Embedding 模块
- Prediction head 模块
- mHC 的静态偏置和门控因子
- 所有 RMSNorm 模块的权重
其他模块使用 Muon 优化器,应用权重衰减、Nesterov trick,并对更新矩阵的 Root Mean Square(RMS)重新缩放,以复用 AdamW 的超参数。此外,使用 hybrid Newton-Schulz iterations 执行正交化。Muon 的主要步骤如下:

Muon 首先计算当前梯度:
\[\begin{equation} G_t = \nabla_W L_t(W_{t-1}) \end{equation}\]然后维护 momentum buffer:
\[\begin{equation} M_t = \mu M_{t-1} + G_t \end{equation}\]这里和普通 Momentum 类似,目的是平滑 batch 梯度噪声。但 DeepSeek-V4 并没有直接使用 $M_t$ 作为更新方向,而是使用 Nesterov trick:
\[\begin{equation} \mu M_t + G_t \end{equation}\]这可以理解为在已有动量方向上做一个前瞻式的更新估计。随后,Muon 对该更新矩阵执行正交化:
\[\begin{equation} O'_t = \text{HybridNewtonSchulz}(\mu M_t + G_t) \end{equation}\]最后对正交化后的更新重新缩放:
\[\begin{equation} O_t = O'_t \cdot \sqrt{\max(n,m)} \cdot \gamma \end{equation}\]并执行 decoupled weight decay 形式的参数更新:
\[\begin{equation} W_t = W_{t-1}(1-\eta\lambda)-\eta O_t \end{equation}\]这里的形式和 AdamW 类似,weight decay 没有混进梯度中,而是直接作用在参数 $W$ 上。
另外,上面的重新缩放为什么要乘 $\sqrt{\max(n,m)}$ ?论文中提到,对正交化后的更新矩阵重新缩放其 Root Mean Square(RMS),以复用 AdamW 的超参数。这里的 RMS 指矩阵元素的均方根。
对一个矩阵 $A \in \mathbb{R}^{n \times m}$,其 RMS 定义为:
\[\begin{equation} \text{RMS}(A) = \sqrt{ \frac{1}{nm} \sum_{i=1}^{n} \sum_{j=1}^{m} A_{ij}^2 } \end{equation}\]也可以写成:
\[\begin{equation} \text{RMS}(A) = \frac{\|A\|_F}{\sqrt{nm} } \end{equation}\]其中:
\[\begin{equation} \|A\|_F = \sqrt{ \sum_{i,j}A_{ij}^2 } \end{equation}\]因此,RMS 衡量的是矩阵中每个元素的平均更新幅度。在 Muon 中,更新矩阵经过 Newton-Schulz 正交化后得到:
\[\begin{equation} O'_t = \text{HybridNewtonSchulz}(\mu M_t + G_t) \end{equation}\]理论上,若对更新矩阵做精确正交化,结果会是半正交矩阵;实际 Muon 使用有限步 Newton-Schulz 迭代,因此 $O’_t \in \mathbb{R}^{n \times m}$ 是近似半正交矩阵,那么它大约有 $\min(n,m)$ 个奇异值接近 1。如果一个矩阵有奇异值:
\(\begin{equation} \sigma_1,\sigma_2,\ldots,\sigma_r \end{equation}\) 那么有一个重要性质: \(\begin{equation} \|A\|_F^2 = \sum_i \sigma_i^2 \end{equation}\) 也就是说,矩阵所有元素平方和,等于所有奇异值平方和。因此: \(\begin{equation} \|O'_t\|_F^2 \approx \min(n,m) \end{equation}\)
于是:
\[\begin{equation} \text{RMS}(O'_t) = \frac{\|O'_t\|_F}{\sqrt{nm} } \approx \sqrt{ \frac{\min(n,m)}{nm} } \end{equation}\]由于:
\[\begin{equation} \frac{\min(n,m)}{nm} = \frac{1}{\max(n,m)} \end{equation}\]所以:
\[\begin{equation} \text{RMS}(O'_t) \approx \frac{1}{\sqrt{\max(n,m)} } \end{equation}\]这说明,正交化后的更新矩阵 RMS 会随着矩阵最大维度变大而变小。对于大模型中的大矩阵,如果直接使用 $O’_t$ 更新参数,在相同学习率下,实际更新幅度会偏小。因此,DeepSeek-V4 使用:
\[\begin{equation} O_t = O'_t \cdot \sqrt{\max(n,m)} \cdot \gamma \end{equation}\]其中:
- $\sqrt{\max(n,m)}$:将正交化后更新矩阵的 RMS 拉回到约 1;
- $\gamma$:额外的 update rescaling factor,用于调节 Muon 更新的整体幅度。
乘上 $\sqrt{\max(n,m)}$ 后,Muon 的更新尺度与 AdamW 的归一化更新尺度接近,因此可以继续沿用 AdamW 中常见的训练超参数设置。但这并不意味着 AdamW 的所有超参数都能直接复用。例如 AdamW 的 $\beta_2$ 在 Muon 中没有对应,因为 Muon 不维护二阶矩;Muon 自身仍有 momentum 系数 $\mu$、rescale factor $\gamma$、Newton-Schulz 迭代次数和系数等额外配置。
3. Hybrid Newton-Schulz 迭代
对给定矩阵 $M$,令其奇异值分解(Singular Value Decomposition,SVD)为:
\[\begin{equation} M=U\Sigma V^T \end{equation}\]其中,$\Sigma$ 中的奇异值表示矩阵在不同主方向上的拉伸强度。Muon 的核心目标不是直接使用原始更新矩阵 $M$,而是将它近似正交化为:
\[\begin{equation} UV^T \end{equation}\]更准确地说,是保留左右奇异向量 $U,V$,但将奇异值 $\Sigma$ 中的非零奇异值压到接近 1。也就是:
\[\begin{equation} M = \sum_i \sigma_i u_i v_i^T \end{equation}\]被近似变为:
\[\begin{equation} \text{Orthogonalize}(M) \approx \sum_i u_i v_i^T \end{equation}\]这样做的含义是:削弱少数大奇异值方向对更新的主导作用,让矩阵更新在不同方向上更均衡。通常,先将 $M$ 归一化为:
\[\begin{equation} M_0=M/\|M\|_F \end{equation}\]保证其最大奇异值不超过 1。随后,每一次 Newton-Schulz iteration 执行:
\[\begin{equation} M_k = aM_{k-1} + b(M_{k-1}M_{k-1}^T)M_{k-1} + c(M_{k-1}M_{k-1}^T)^2 M_{k-1} \end{equation}\]该迭代本质上是通过矩阵乘法近似调整 $M$ 的奇异值,而不是显式计算 SVD。这样可以避免每一步训练都做昂贵的 SVD 分解。Hybrid Newton-Schulz 在两个不同阶段共执行 10 次迭代。前 8 步使用系数:
\[(a,b,c)=(3.4445,-4.7750,2.0315)\]推动快速收敛,使奇异值接近 1。最后 2 步切换到:
\[(a,b,c)=(2,-1.5,0.5)\]使奇异值更精确地稳定在 1。此外,DeepSeek-V4 系列的 attention 架构直接对 attention queries 和 KV entries 应用 RMSNorm,这能有效防止 attention logits 爆炸。因此,没有在 Muon optimizer 中使用 QK-Clip 技术。
二、基础设施
本部是大量工程优化,简要带过。
(一)细粒度 EP 通信-计算重叠
MoE 的 Expert Parallelism (EP) 需要复杂的跨节点通信。DeepSeek-V4 的关键洞察是:在一个 MoE 层中,通信总时间小于计算总时间,因此通信延迟可以被隐藏在计算之下。
具体方案:将专家划分为多个 wave,每个 wave 包含少量专家。一旦某个 wave 的通信完成,计算立即开始,无需等待其他专家。在稳态下,当前 wave 的计算、下一个 wave 的通信、已完成专家的结果发送同时进行,形成细粒度流水线。
相比非融合基线,该方案在一般推理负载下实现 $1.50 \sim 1.73\times$ 加速,在延迟敏感场景(如 RL rollout)下最高达 $1.96\times$。
(二)使用 TileLang 进行灵活高效的 Kernel 开发
DeepSeek-V4 的复杂架构会产生大量细粒度 Torch ATen 算子,如果直接用普通 PyTorch 实现,会带来明显的 kernel launch、Python 调度和中间访存开销。因此,DeepSeek-V4 使用 TileLang 这种 DSL 来开发融合 kernel。
TileLang 的作用是兼顾开发效率和运行效率:一方面可以快速原型验证 attention 变体等新算子,另一方面也能逐步优化到生产可用的高性能 kernel。论文中特别强调三点:通过 Host Codegen 将 Python 侧检查下沉到生成的 host launcher,降低 CPU 调度开销;通过 Z3 SMT solver 加强整数索引分析,帮助编译器做向量化、边界分析和 barrier 插入;同时默认关闭 fast-math,并提供 IEEE-compliant intrinsics,以保证数值精度和 bitwise reproducibility。
(三)批量不变与确定性计算内核
DeepSeek-V4 构建了一套高性能 kernel 库,目标不仅是快,还要保证训练、后训练和推理之间的 bitwise 对齐。
Batch-invariant:同一个 token 的输出不应因为它处在不同 batch 位置、或和不同样本一起组成 batch 而发生 bit 级变化。为此,DeepSeek-V4 在 attention decoding 中避免普通 split-KV 带来的非固定累加顺序,并设计 dual-kernel 策略兼顾吞吐和尾部 wave 延迟;在矩阵乘法中,则用 DeepGEMM 替代不保证 batch invariance 的 cuBLAS。
Deterministic 则主要解决 backward 中的非确定性累加问题。例如 attention backward 中避免直接 atomicAdd 到共享 KV 梯度,而是让每个 SM 使用独立累加 buffer,再做确定性归约;MoE backward 中通过 token 顺序预处理和跨 rank buffer 隔离固定写入顺序;mHC 中的小维度矩阵乘则把 split-k 的各部分单独输出,再做确定性 reduction。
(四)FP4 量化感知训练
在后训练阶段引入 FP4 (MXFP4) 量化,应用于两个组件:
- MoE 专家权重:FP32 master weights → FP4 量化 → FP4-to-FP8 无损反量化 → FP8 计算
- CSA indexer 的 QK 路径:QK 激活在 FP4 下缓存、加载和计算
此外,DeepSeek-V4 还将 CSA indexer 的 index scores 从 FP32 量化到 BF16,使 top-k selector 获得 $2\times$ 加速,同时保持 $99.7\%$ 的 KV entry recall。
(五)训练框架
DeepSeek-V4 的训练框架继承自 DeepSeek-V3,但针对新组件做了专门扩展,主要包括 Muon、mHC、长上下文注意力和激活 checkpointing。
对于 Muon,传统 ZeRO 会把参数矩阵切开,但 Muon 需要完整梯度矩阵来做更新,因此 DeepSeek-V4 设计了 hybrid ZeRO bucket assignment:dense 参数限制 ZeRO 并行规模并用 knapsack 做负载均衡,MoE 参数则按 expert 独立优化并展平分发。同时,MoE 梯度同步可用 BF16 随机舍入减少通信量。
对于 mHC,由于它会增加激活内存和 pipeline 通信量,DeepSeek-V4 使用 fused mHC kernel、选择性 recomputation,以及调整 DualPipe 1F1B 重叠策略,将额外 wall-time overhead 控制在 $6.7\%$。
对于 CSA/HCA 长上下文注意力,传统 Context Parallelism 会遇到压缩块跨 rank 边界、不同 rank 压缩 KV 长度不一致的问题。DeepSeek-V4 采用两阶段通信:先把边界处未压缩 KV 发给相邻 rank,再 all-gather 压缩后的 KV,并用 fused select-and-pad 整理成统一布局。
此外,DeepSeek-V4 扩展了自动微分框架,实现 tensor-level activation checkpointing。开发者只需标注需要 checkpoint/recompute 的 tensor,框架通过 TorchFX 找到最小重算子图,在 backward 中自动插入重算逻辑。
(六)推理框架
DeepSeek-V4 的推理框架主要变化在 KV cache 管理。由于 CSA、HCA、SWA 和 lightning indexer 都有不同的 KV cache 形态,传统 PagedAttention 统一 block 管理方式不再适用。
DeepSeek-V4 将 KV cache 分成两类:一类是 state cache,用于管理 SWA 最近窗口内的 KV,以及 CSA/HCA 中还没凑满压缩块的未压缩尾部 token;另一类是 classical KV cache,用于存放已经压缩完成的 CSA/HCA KV entries。为了同时兼容 CSA 和 HCA,不同 cache block 的原始 token 覆盖范围按 $\operatorname{lcm}(m,m’)$ 的倍数设计,其中 $m$ 和 $m’$ 分别是 CSA 和 HCA 的压缩率。
此外,DeepSeek-V4 还引入 on-disk KV cache,用于复用共享前缀,减少重复 prefill。CSA/HCA 的压缩 KV 可以直接存盘;SWA 因为体积约为压缩 KV 的 8 倍,论文提出三种策略:Full SWA Caching、Periodic Checkpointing 和 Zero SWA Caching,分别在存储开销和重算开销之间做不同取舍。
三、预训练
(一)数据构建
在 DeepSeek-V3 数据基础上构建了更多样、更高质量、更长有效上下文的训练语料,总计超过 32T token。关键改进:
- 过滤批量自动生成和模板化内容,缓解模型坍缩风险
- 增强数学和编程语料,在 mid-training 阶段加入 agentic 数据
- 构建更大的多语言语料
- 特别重视长文档数据(科学论文、技术报告)
- 引入少量用于上下文构建的特殊 token,词表大小保持 128K
- 预训练使用 sample-level attention masking
(二)模型配置
| 配置项 | DeepSeek-V4-Flash | DeepSeek-V4-Pro |
|---|---|---|
| Transformer layers | 43 | 61 |
| Hidden dimension $d$ | 4096 | 7168 |
| 前两层 attention | 纯 Sliding Window Attention | HCA |
| 后续 attention 结构 | CSA / HCA 交错使用 | CSA / HCA 交错使用 |
| CSA compression rate $m$ | 4 | 4 |
| CSA indexer query heads $n_h^I$ | 64 | 64 |
| CSA indexer head dimension $c^I$ | 128 | 128 |
| CSA attention top-k | 512 | 1024 |
| HCA compression rate $m’$ | 128 | 128 |
| CSA/HCA query heads $n_h$ | 64 | 128 |
| CSA/HCA head dimension $c$ | 512 | 512 |
| Query compression dimension $d_c$ | 1024 | 1536 |
| Output projection groups $g$ | 8 | 16 |
| Intermediate attention output dimension $d_g$ | 1024 | 1024 |
| Sliding window size $n_{\mathrm{win} }$ | 128 | 128 |
| Transformer block FFN | 全部使用 MoE layers | 全部使用 MoE layers |
| Hash routing | 前 3 个 MoE layers | 前 3 个 MoE layers |
| Shared experts per MoE layer | 1 | 1 |
| Routed experts per MoE layer | 256 | 384 |
| Expert intermediate hidden dimension | 2048 | 3072 |
| Activated routed experts per token | 6 | 6 |
| MTP depth | 1 | 1 |
| mHC expansion factor $n_{\mathrm{hc} }$ | 4 | 4 |
| Sinkhorn-Knopp iterations $t_{\max}$ | 20 | 20 |
| Total parameters | 284B | 1.6T |
| Activated parameters per token | 13B | 49B |
(三)训练配置
DeepSeek-V4-Flash. 对大多数参数使用 Muon optimizer,但对 embedding module、prediction head module 和所有 RMSNorm modules 的权重使用 AdamW optimizer。对于 AdamW,超参数设为 $\beta_1=0.9$,$\beta_2=0.95$,$\varepsilon=10^{-20}$,weight decay 为 0.1。对于 Muon,momentum 设为 0.95,weight decay 设为 0.1,并将每个 update matrix 的 RMS rescale 到 0.18,以复用 AdamW learning rate。
在 32T tokens 上训练 DeepSeek-V4-Flash。与 DeepSeek-V3 一样,使用 batch size scheduling strategy:先从较小 batch size 开始,逐步增加到 75.5M tokens,并在大部分训练中保持 75.5M。learning rate 在前 2000 steps 线性 warm up,随后保持在 $2.7\times10^{-4}$,再按 cosine schedule 衰减到 $2.7\times10^{-5}$。训练长度从 4K 开始,然后逐步扩展到 16K、64K 和 1M。对于 sparse attention 设置,先在前 1T tokens 使用 dense attention warmup,然后在序列长度达到 64K 时引入 sparse attention,并在其余训练中保持 sparse attention。引入 sparse attention 时,先设置一个短阶段来 warm up CSA 的 lightning indexer,然后在大部分训练中使用 sparse attention。对于 auxiliary-loss-free load balancing,bias update speed 设为 0.001。对于 balance loss,loss weight 设为 0.001,以避免单个序列内出现极端不均衡。MTP loss weight 在大部分训练中设为 0.3,在 learning rate decay 开始后设为 0.1。
DeepSeek-V4-Pro. 除具体超参数值外,DeepSeek-V4-Pro 的 training setup 与 DeepSeek-V4-Flash 基本一致。对大多数参数使用 Muon,对 embedding module、prediction head module 和所有 RMSNorm weights 使用 AdamW。AdamW 和 Muon 的超参数与 DeepSeek-V4-Flash 相同。DeepSeek-V4-Pro 在 33T tokens 上训练,也使用 batch size scheduling,最大 batch size 为 94.4M tokens。learning rate schedule 与 DeepSeek-V4-Flash 大体相同,但 peak learning rate 设为 $2.0\times10^{-4}$,end learning rate 设为 $2.0\times10^{-5}$。训练也从 4K 开始,并逐步扩展到 16K、64K 和 1M。相比 DeepSeek-V4-Flash,DeepSeek-V4-Pro 使用更长的 dense attention 阶段;引入 sparse attention 的策略与 Flash 相同,采用两阶段训练。对于 auxiliary-loss-free load balancing,bias update speed 设为 0.001。balance loss weight 设为 0.0001,以避免单个序列内极端不均衡。MTP loss weight 在大部分训练中设为 0.3,在 learning rate decay 开始后设为 0.1。
(四)训练稳定性
训练万亿参数 MoE 模型面临显著的稳定性挑战。DeepSeek-V4 发现 loss spike 始终与 MoE 层的 outlier 相关,路由机制本身会加剧这些 outlier。两个有效的缓解技术:
Anticipatory Routing:将骨干网络和路由网络的更新解耦。在第 $t$ 步,使用当前参数 $\theta_t$ 计算特征,但路由索引使用历史参数 $\theta_{t-\Delta t}$ 计算。实际实现中,为避免两次加载模型参数带来的开销,提前在第 $t-\Delta t$ 步获取第 $t$ 步的数据,并预期性的计算并缓存稍后第 $t$ 步要使用的路由索引。
SwiGLU Clamping:在实际训练中,发现 SwiGLU clamping 能有效消除 outliers,并显著稳定训练过程,同时不损害性能。在 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的训练中,将 SwiGLU 的线性分量限制在 $[-10,10]$ 内,将门控分量上界为设置为 10。
四、后训练
后训练流程大体与 DeepSeek-V3.2 相似,但一个关键变化是,将混合 RL 阶段替换为 On-Policy Distillation(OPD)。主要分为两个阶段:
(一)阶段一:专家训练
每个专家模型都会依次经过初始微调和后续 RL,RL 由领域特定 prompts 与奖励信号引导。RL 阶段使用 GRPO,超参数设置与此前研究大体一致。这种设计的核心是“先分后合”:先让数学、代码、agent、instruction following 等专家在各自领域充分优化,再通过 OPD 合并能力。相比一开始就训练一个全能模型,这种方式能让每个专家在 reward、数据和推理长度配置上更贴近自己的任务。
1. Reasoning Efforts
DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 都支持三种 reasoning effort。对于每种模式,在 RL training 中应用不同 length penalties 和 context windows,从而产生不同长度的 reasoning output tokens。为了整合这些不同 reasoning modes,使用由 <think> 和 </think> tokens 标记的特殊 response formats。此外,对于 “Think Max” 模式,还会在 system prompt 开头加入特定 instruction,以引导模型推理过程。
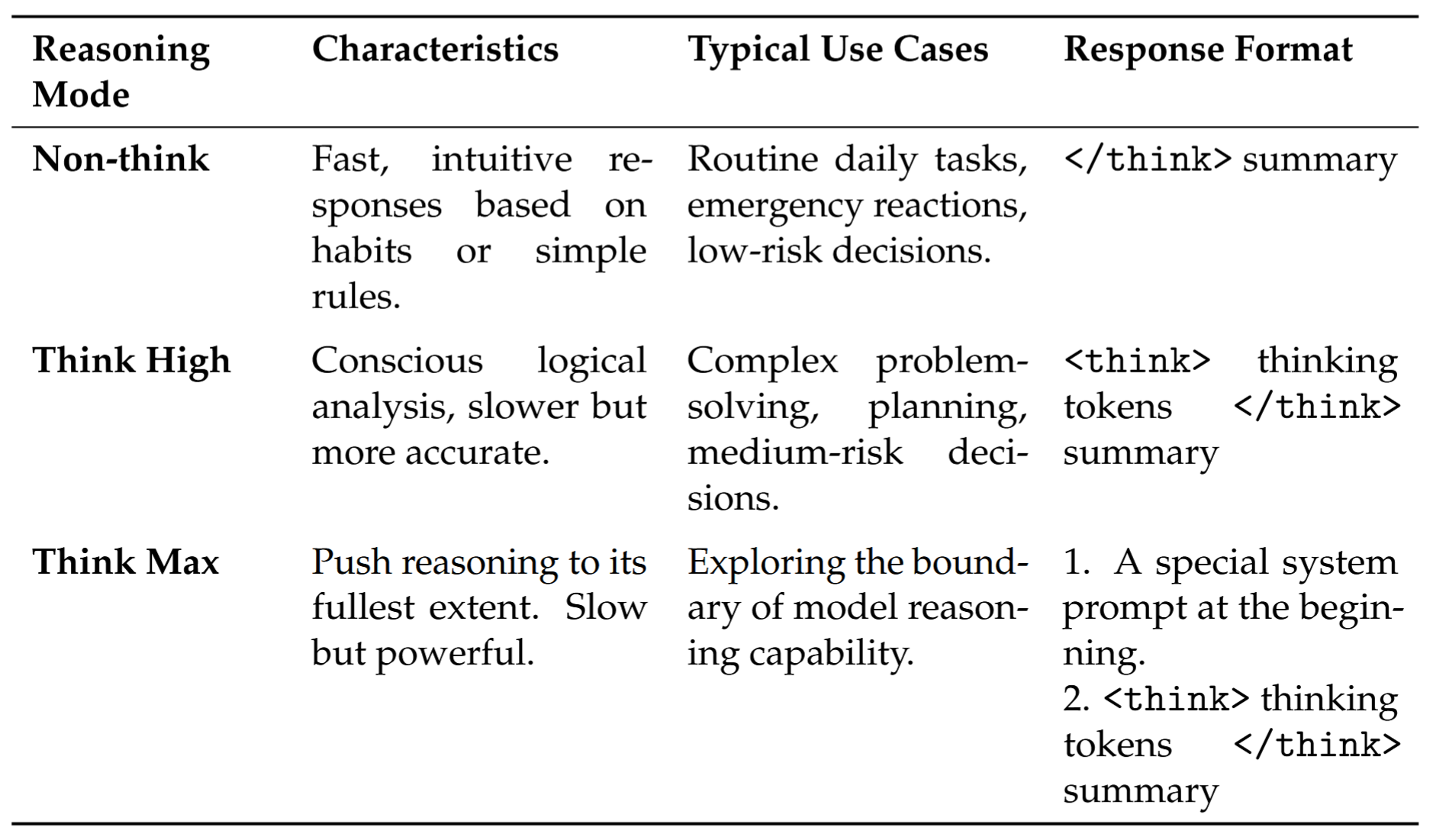
Non-think 模式用于快速、直觉式响应,适合日常简单任务、低风险决策或紧急反应;Think High 模式用于有意识的逻辑分析,速度较慢但更准确,适合复杂问题求解、规划和中等风险决策;Think Max 模式把 reasoning 推到最大程度,速度慢但能力强,用于探索模型 reasoning capability 的边界。Think Max 注入指令要求模型以绝对最大 reasoning effort 工作,不允许走捷径,必须彻底分解问题、压力测试逻辑、考虑边界和对抗情形,并显式写出完整 deliberation process。
2. Generative Reward Model
对容易验证的任务,例如代码测试或数学答案匹配,可以使用规则 verifier 或测试用例作为 reward。但许多任务很难验证,例如复杂写作、开放式 agent 任务、主观质量判断等。传统 RLHF 通常会训练一个 scalar reward model,把回答映射成一个标量分数,但这需要大量人工标注。
DeepSeek-V4 采用 Generative Reward Model(GRM):不是训练一个单独的标量 reward model,而是让 actor model 自身具备评价轨迹的能力。具体做法是构造 rubric-guided RL 数据,让模型以生成式方式评估 policy trajectories,并直接对 GRM 本身做 RL 优化。
这种范式的含义是:模型既是生成者,也是评价者。它在生成答案的同时,也学习如何根据 rubric 判断答案质量。论文认为这能把模型内部推理能力融入评价过程,因此只需要少量多样化人工标注,就能泛化到复杂任务。
3. Tool-Call Schema and Special Token
DeepSeek-V4 继续使用 <think></think> 标记区分 reasoning path,同时引入新的 tool-call schema。这个 schema 使用特殊 token |DSML|,并采用 XML 风格格式调用工具。
这样做的主要目的有两个:
- XML 格式能减少 escaping failure,降低工具调用格式错误。
- 独立的特殊 token 和结构化 schema 能让模型更稳定地区分思考、工具调用和最终回答。
原文还要求:如果 thinking mode 被启用,模型必须先在 <think>...</think> 中输出完整 reasoning,再进行工具调用或最终回答;如果没有启用 thinking mode,则直接在 </think> 之后输出工具调用或回答。
4. Interleaved Thinking
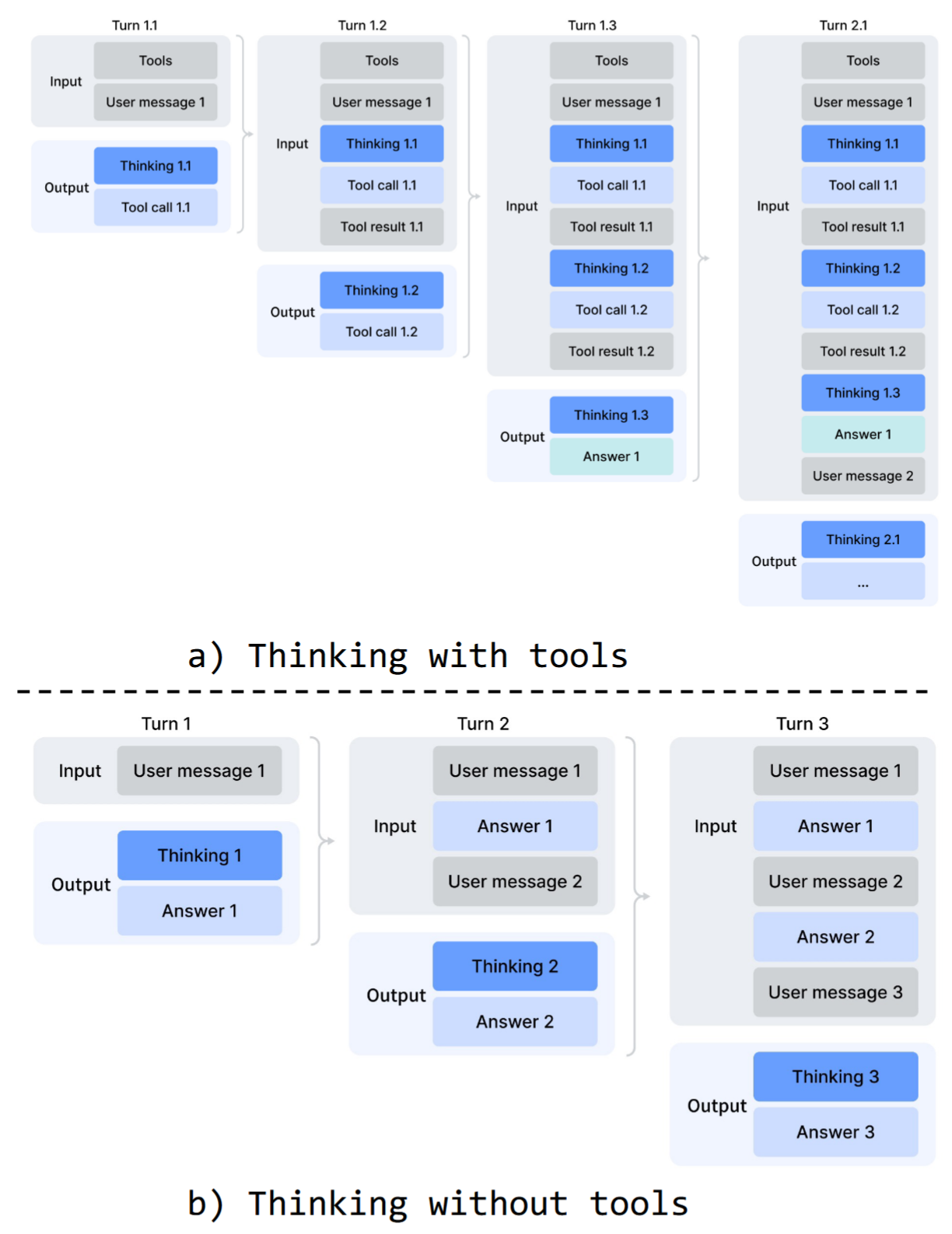
DeepSeek-V3.2 的上下文管理策略是在工具调用结果之间保留 reasoning trace,但当新的 user message 到来时,会丢弃之前的 thinking 内容。这能节省上下文,但在复杂 agent workflow 中会造成浪费:每个新用户轮次都清空已有推理状态,模型需要重新建立问题理解。
DeepSeek-V4 利用 1M token 上下文,把 thinking 管理分成两种场景:
- Tool-calling scenarios:完整保留整个对话中的 reasoning content,包括跨用户消息边界的思考历史。这让模型在长周期 agent 任务中维持连续的问题求解状态。
- General conversational scenarios:保持旧策略,新用户消息到来时丢弃上一轮 reasoning,使普通对话保持简洁。
需要注意的是,如果某些 agent 框架把工具交互模拟成用户消息,而没有走真正 tool-calling path,就可能无法触发这种增强的 reasoning persistence。论文仍建议这类架构使用 non-think models。
5. Quick Instruction
在 chatbot 中,正式回答前常常需要做一些辅助判断,例如是否搜索、意图识别、生成搜索 query、判断权威性和领域等。传统做法通常用一个小模型单独处理,但小模型无法复用主模型已经计算好的 KV cache,会产生重复 prefill。
DeepSeek-V4 引入 Quick Instruction:把一组专用 special tokens 直接追加到输入序列中,每个 token 对应一个辅助任务,例如:
<|action|>:判断是否需要 web search。<|query|>:生成搜索 query。<|authority|>:判断用户问题对来源权威性的要求。<|domain|>:识别问题领域。<|extracted_url|>:判断用户给出的 URL 是否需要抓取阅读。

这样,辅助任务可以直接复用主上下文的 KV cache,并且部分任务可以并行执行,从而降低用户感知的 TTFT(time-to-first-token),也省掉维护额外小模型的工程成本。
(二)阶段二:On-Policy Distillation (OPD)
将多个领域专家的能力融合到一个统一模型中。给定 $N$ 个专家 ${\pi_{E_1}, \ldots, \pi_{E_N}}$,OPD 目标函数为: \(\begin{equation} \label{eq:opd} \mathcal{L}_{\text{OPD} }(\theta) = \sum_{i=1}^N w_i \cdot D_{\text{KL} }(\pi_\theta \| \pi_{E_i}) \end{equation}\)
其中:
- $w_i$ 是第 $i$ 个专家模型的权重,通常由该专家的重要性决定。
- $\pi_\theta$ 是 student model。
- $\pi_{E_i}$ 是第 $i$ 个 expert teacher。
- $\mathrm{D}_{\mathrm{KL} }(\pi_{\theta} | \pi_{E_i})$ 是 reverse KL,即 student 分布相对 teacher 分布的 KL。
这里的 on-policy 指的是:训练轨迹从 student model $\pi_\theta$ 自己采样,而不是从 teacher 或固定数据集中采样。也就是说,student 先生成自己的 response trajectory,然后在这条轨迹上计算 teacher 分布,并学习对齐 teacher。其内在逻辑是,unified policy $\pi_\theta$ 会根据当前 task context 有选择地向相关 specialist expert 学习,例如数学任务更靠近数学专家,代码任务更靠近代码专家。论文强调,这种 logits-level alignment 能把物理上分散在不同专家权重中的能力合并到统一参数空间,绕开传统 weight merging 或 mixed RL 中常见的性能退化。在该阶段,使用了超过十个覆盖不同领域的 teacher models 来蒸馏单个 student model。
另外,以往一些 OPD 或 RL 蒸馏做法会把 full-vocabulary KL 简化为 token-level KL,即只看当前采样 token 的 teacher/student 概率比,并把:
\[\begin{equation} \mathsf{sg}\left[ \log \frac{\pi_{E_i}(y_t|x,y_{<t})}{\pi_\theta(y_t|x,y_{<t})} \right] \end{equation}\]作为 per-token advantage estimate 放进 policy loss 中。其中 $\mathsf{sg}$ 表示 stop-gradient。这种简化更省资源,但梯度估计方差高,容易训练不稳定。因此 DeepSeek-V4 采用 full-vocabulary logit distillation:在每个 token 位置保留完整词表分布来计算 reverse KL。这样梯度更稳定,也能更忠实地蒸馏 teacher 知识。代价是工程成本很高,因为词表超过 $100k$,teacher 又可能有十多个,直接保存所有 teacher logits 会造成极大的显存、内存和磁盘压力。
五、实验结果
(一)预训练评估
V4-Flash-Base(13B 激活,284B 总参数)在多数基准上超过了 V3.2-Base(37B 激活,671B 总参数),展现了架构改进和数据优化带来的效率优势。V4-Pro-Base 进一步全面领先,在 MMLU 90.1、MMLU-Pro 73.5、HumanEval 76.8、LongBench-V2 51.5 等指标上创下 DeepSeek 基座模型新高。
(二)后训练评估
关键结果:
- 知识:V4-Pro-Max 在 SimpleQA-Verified 上以超过 20 个百分点的优势领先所有开源模型;在 Chinese-SimpleQA 上达到 84.4,大幅领先
- 推理:V4-Pro-Max 在 Codeforces 上达到 3206 rating(人类排名第 23),首次开源模型匹配闭源模型;HMMT 2026 Feb 达到 95.2;Apex Shortlist 达到 90.2
- Agent:V4-Pro-Max 在公开基准上与 K2.6、GLM-5.1 相当,在内部评估中超过 Claude Sonnet 4.5,接近 Opus 4.5 水平;SWE-Verified 达到 80.6
- 长上下文:V4-Pro-Max 在 MRCR 1M 和 CorpusQA 1M 上均超过 Gemini-3.1-Pro
- 形式化数学:在 Putnam-2025 上以 hybrid formal-informal reasoning 达到 120/120 满分
- 内部 R&D 编程基准:V4-Pro-Max 通过率 67%,显著超过 Claude Sonnet 4.5 (47%),接近 Opus 4.5 (70%)
V4-Flash-Max 在推理任务上给予足够 thinking budget 时可匹配闭源模型,但在知识评估上因参数规模较小而落后于 V4-Pro。
六、总结
本文提出 DeepSeek-V4 系列预览版本,目标是构建下一代大语言模型,突破超长上下文处理中的效率壁垒。通过结合 CSA 和 HCA 的混合 attention 架构,DeepSeek-V4 系列在长序列效率上实现显著跃迁。架构创新加上广泛基础设施优化,使模型能够高效原生支持 million-token contexts,并为未来 test-time scaling、long-horizon tasks 和 online learning 等 emerging paradigms 建立必要基础。
为了追求极致 long-context efficiency,DeepSeek-V4 系列采用了大胆的架构设计。为了降低风险,保留了许多初步验证过的 components 和 tricks。虽然它们有效,但也让架构相对复杂。未来迭代中,DeepSeek 会进行更全面、更原则化的研究,将架构提炼到最本质设计,使其更优雅,同时不牺牲性能。与此同时,虽然 Anticipatory Routing 和 SwiGLU Clamping 已经被证明能有效缓解 training instabilities,但它们的底层原理仍理解不足。下一步将积极研究训练稳定性的基础问题,并强化内部 metric monitoring,以实现更原则化、更可预测的大规模稳定训练方法。
此外,除了 MoE 和 sparse attention 架构之外,也会主动探索新维度的 model sparsity,例如更 sparse 的 embedding modules(或许后续迭代会加入 Engram 或变体?),以在不损害能力的前提下进一步提升计算和内存效率。还会持续研究 low-latency architectures 和 system techniques,使长上下文部署和交互更具响应性。后续还会增加对 long-horizon、multi-round agentic tasks、multimodal capabilities 的相关研究。最后,致力于发展更好的 data curation 和 synthesis strategies,以在越来越广泛的场景和任务中持续增强模型 intelligence、robustness 和 practical usability。