【手撕系列】手撕DeepSeek-V3
Categories: Code
目录
概览
完整的DeepSeek-V3涉及到庞大的工程优化和算力资源,本项旨在基于较小的算力,实现基本的DeepSeek-V3训练和推理demo,并编写一个能够复用的demo框架。后续在学习其他模型时,只需添加模型模块即可,从而能够将主要精力聚焦在模型架构的学习上。
对本项目的手撕内容做以下几点说明:
- 主要从MLA、DeepSeekMoE、MTP、无辅助损失的负载均衡策略、序列级辅助损失等核心架构来实现一个mini-deepseekv3架构模型
- 由于模型较小,不考虑通过YaRN来扩展上下文长度,使用原始的RoPE
- 由于模型参数量较少,采用单卡或ddp的方式训练
- 训练方法包含预训练、SFT
- 不考虑原文中FP8混合精度训练、DualPipe等复杂的工程优化
- 根据以上几点对DeepSeek-V3源代码进行一定修改与简化,无需修改的地方尽量与源码保持一致
- 核心部分尽量做到每一步都与原文公式相对应,并标出计算过程的张量形状
- 请确保已经基本了解了DeepSeek-V3的相关理论,具体可参考【论文解读】DeepSeek-V3
- 本文主要讲解核心代码部分,全部代码地址:Mini-LLM,如果对您有所帮助,欢迎Star🎉
- 本人也还处于学习的过程,难免有错误和理解不到位的地方,欢迎指出问题和探讨交流
一、MLA实现
首先预定义以下类和函数,后续的代码讲解中会直接使用,具体实现本文不再过多介绍。RMSNorm、RoPE、KV Cache的相关理论可以参考:【手撕系列】手撕Llama3,其中有较为详细的阐述。其中,模型配置参数中涉及到的参数含义列出,后续代码中可能会涉及到。
@dataclass
class DeepSeekV3ModelArgs(BaseModelArgs):
"""
配置模型参数
Attributes:
max_batch_size (int): 最大批量大小
max_seq_len (int): 最大序列长度
vocab_size (int): 词典大小
dim (int): 嵌入维度
inter_dim (int): MLP层的中间维度
moe_inter_dim (int): MoE层专家的中间维度
n_layers (int): Transformer层的数量
n_dense_layers (int): 模型中密集层的数量, 前几层负载均衡收敛慢, 因此设置为密集层
n_heads (int): 注意力头数
n_routed_experts (int): MoE层中路由的专家数量
n_shared_experts (int): MoE层中共享的专家数量
n_activated_experts (int): MoE层中激活的专家数量
n_expert_groups (int): 专家的分组数量
n_limited_groups (int): 路由限制, 每次最多从限制的专家组里选择专家
route_scale (float): 路由权重的缩放因子
use_noaux_tc (bool): 是否使用无辅助损失的负载均衡策略
bias_update_speed (float): 偏置更新速度
use_seq_aux (bool): 是否使用序列级别的辅助损失
seq_aux_alpha (float): 序列级别的辅助损失的权重
q_lora_rank (int): query 的下投影维度【对应论文中的 d_c'】
kv_lora_rank (int): key/value 的下投影维度【对应论文中的 d_c】
qk_nope_head_dim (int): 没有位置编码的 q_t^C 和 k_t^C 的每个头的维度【对应论文中的 d_h】
qk_rope_head_dim (int): 解耦的带 RoPE 的 q_t^R 和 k_t^R 的每个头的维度【对应论文中的 d_h^R】
v_head_dim (int): value 的每个头的维度, 可以与 qk_nope_head_dim 不同【但在论文中也同样设定为 d_h】
rope_theta (float): 旋转位置编码的基底【即 θ_d=b^(-2d/D) 中的 b】
use_mtp (bool): 是否使用 MTP 策略
mtp_loss_lambda (float): MTP 损失的权重
"""
...
class RMSNorm(nn.Module):
"""RMS归一化"""
...
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
"""应用RoPE位置编码"""
...
为了解释清楚MLA的具体实现,我们将代码拆解成小块逐个讲解。首先,回顾一下MLA的架构图,对照理解:
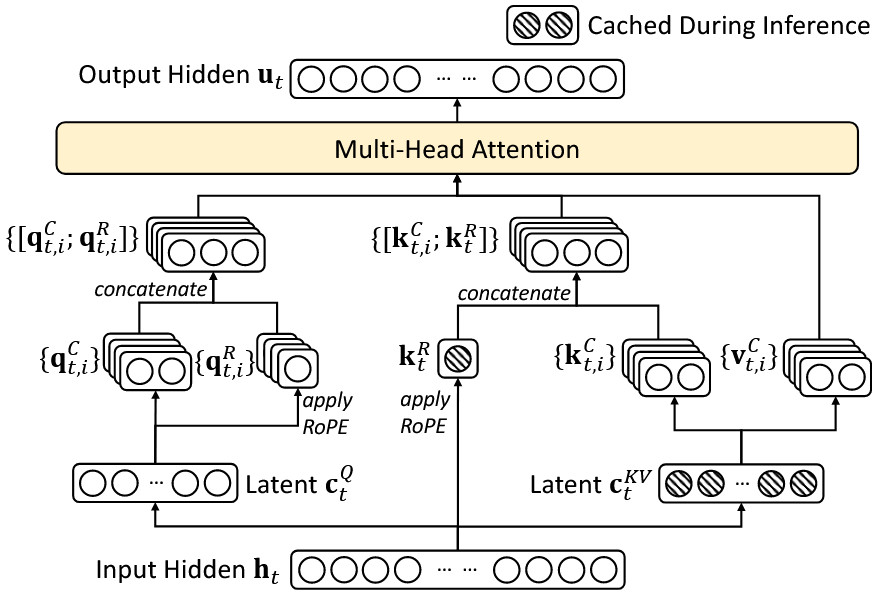
进一步给出更详细的代码实现框架:
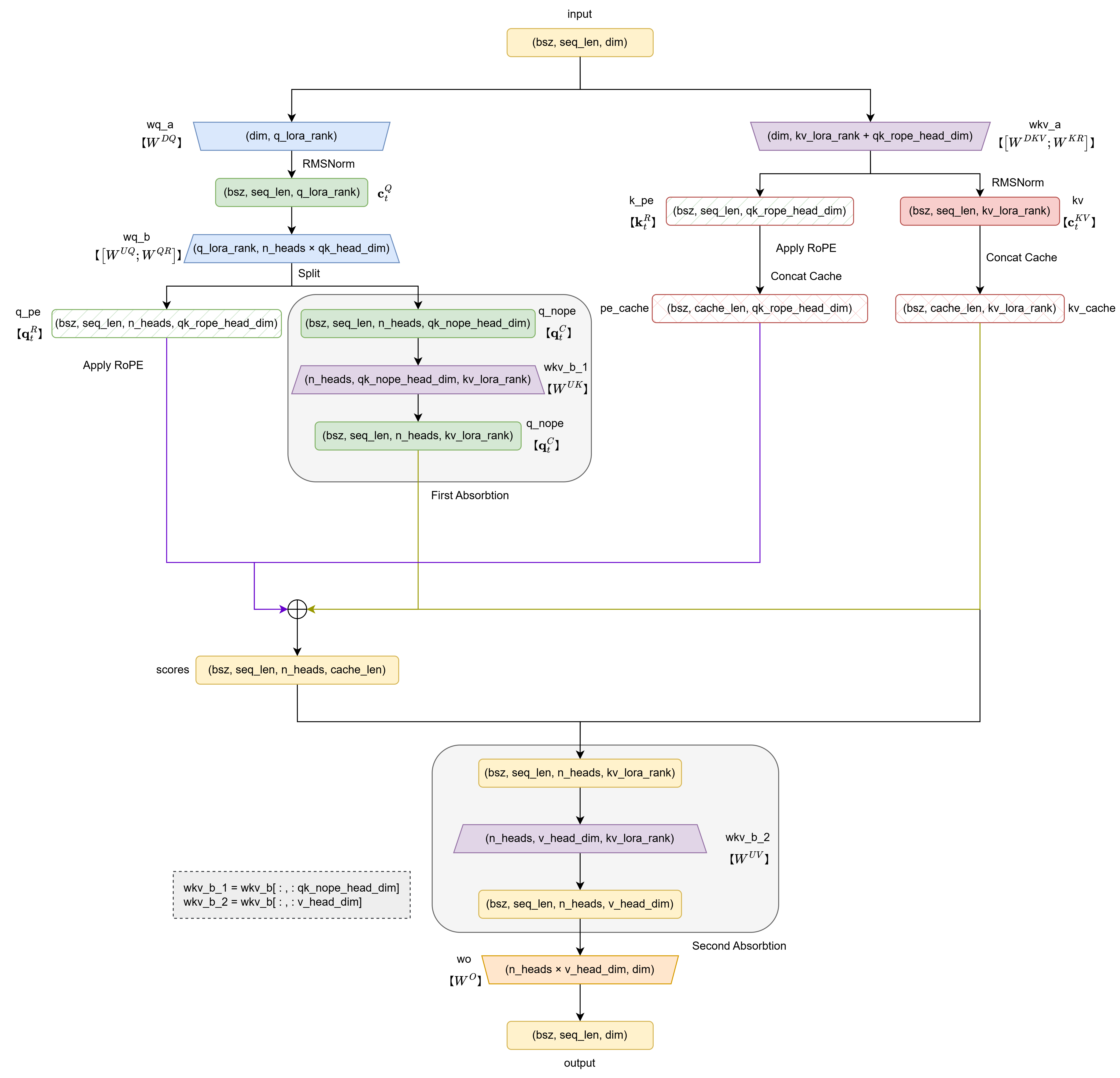
(一)定义和初始化
首先创建MLA类,所需要传入的参数如下:
class MLA(nn.Module):
"""
多头潜在注意力: Multi-Headed Latent Attention Layer (MLA)
Attributes:
dim (int): 嵌入维度【对应论文中的 d】
n_heads (int): 注意力头数【对应论文中的 n_h】
q_lora_rank (int): query 的下投影维度【对应论文中的 d_c'】
kv_lora_rank (int): key/value 的下投影维度【对应论文中的 d_c】
qk_nope_head_dim (int): 没有位置编码的 q_t^C 和 k_t^C 的每个头的维度【对应论文中的 d_h】
qk_rope_head_dim (int): 解耦的带 RoPE 的 q_t^R 和 k_t^R 的每个头的维度【对应论文中的 d_h^R】
qk_head_dim (int): 最终执行注意力计算的 query 和 key 的每个头的维度【即 d_h + d_h^R】
v_head_dim (int): value 的每个头的维度, 可以与 qk_nope_head_dim 不同【但在论文中也同样设定为 d_h】
softmax_scale (float): 注意力计算的缩放因子【即 1/sqrt(d_h + d_h^R)】
"""
def __init__(self, args: ModelArgs):
super().__init__()
self.dim = args.dim
self.n_heads = args.n_heads
# 定义 query/key/value 维度
self.q_lora_rank = args.q_lora_rank
self.kv_lora_rank = args.kv_lora_rank
self.qk_nope_head_dim = args.qk_nope_head_dim
self.qk_rope_head_dim = args.qk_rope_head_dim
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim
self.v_head_dim = args.v_head_dim
# 低秩压缩 query
self.wq_a = nn.Linear(self.dim, self.q_lora_rank, bias=False)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = nn.Linear(self.q_lora_rank, self.n_heads * self.qk_head_dim, bias=False)
# key / value 的维度变换
self.wkv_a = nn.Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim, bias=False)
self.kv_norm = RMSNorm(self.kv_lora_rank)
self.wkv_b = nn.Linear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim), bias=False)
# 输出的维度变换
self.wo = nn.Linear(self.n_heads * self.v_head_dim, self.dim, bias=False)
self.softmax_scale = self.qk_head_dim ** -0.5 # 注意力缩放因子
# 缓存 c_t^KV 和 k_t^R
self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False)
self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
下面的表格更加直观的列出上述参数和论文中变量的对应关系:
| 变量含义 | 代码中的变量 | 论文中的变量 |
|---|---|---|
| 嵌入维度 | dim | $d$ |
| 注意力头数 | n_heads | $n_h$ |
| query的下投影维度,即潜在向量$\mathbf{c}_t^Q$的维度 | q_lora_rank | $d_c’$ |
| key / value的下投影维度,即潜在向量$\mathbf{c}_t^{KV}$的维度 | kv_lora_rank | $d_c$ |
| 不带位置编码部分($\mathbf{q}_t^C,\mathbf{k}_t^C$)的每个头的维度 | qk_nope_head_dim | $d_h$ |
| 带位置编码部分(解耦的$\mathbf{q}_t^R,\mathbf{k}_t^R$)的每个头的维度 | qk_rope_head_dim | $d_h^R$ |
| 最终执行注意力计算的 query 和 key 的每个头的维度 | qk_head_dim | $d_h+d_h^R$ |
| value的每个头的维度,论文中也设为 $d_h$ | v_head_dim | $d_h$ |
| 注意力计算的缩放因子 | softmax_scale | $1/\sqrt{(d_h + d_h^R)}$ |
| 对原始向量执行$\mathbf{c}_t^Q$下投影的矩阵 | self.wq_a | $W^{DQ}\in\mathbb{R}^{d_c’\times d}$ |
| 同时对$\mathbf{c}_t^Q$执行$\mathbf{q}_t^C$上投影($W^{UQ}\in \mathbb{R}^{d_h n_h \times d_c’}$)和$\mathbf{q}_t^R$解耦($W^{QR} \in \mathbb{R}^{d_h^R n_h \times d_c’}$)的矩阵 | self.wq_b | $[W^{UQ};W^{QR}]\in \mathbb{R}^{(d_h+d_h^R) n_h \times d_c’}$ |
| 同时对原始向量进行$\mathbf{c}_t^{KV}$下投影($W^{DKV} \in \mathbb{R}^{d_c \times d}$)和$\mathbf{k}_t^R$解耦($W^{KR} \in \mathbb{R}^{d_h^R \times d}$)的矩阵 | self.wkv_a | $[W^{DKV};W^{KR}]\in \mathbb{R}^{(d_c+d_h^R) \times d}$ |
| 同时对$\mathbf{c}_t^{KV}$执行$\mathbf{k}_t^C$上投影($W^{UK}\in \mathbb{R}^{d_h n_h \times d_c}$)和$\mathbf{v}_t^C$上投影($W^{UV}\in \mathbb{R}^{d_h n_h \times d_c}$)的矩阵 | self.wkv_b | $[W^{UK};W^{UV}]\in \mathbb{R}^{(d_h+d_h) n_h \times d_c}$ |
| 输出维度变换矩阵 | self.wo | $W^O \in \mathbb{R}^{d \times d_h n_h}$ |
通过捋清楚这些变量的含义,结合MLA的理论,就基本可以构想出后续forward方法的实现。因此,弄清变量的含义这一步非常重要。另外需说明的是,源代码中的线性层是使用模型分布的方法自定义实现的,由于我们只使用单卡或ddp实现一个较小的模型,因此将线性层简化为nn.Linear实现,且偏置均设置为bias=False。
(二)MLA的前向传播
首先给出前向传播的完整代码:
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
"""
MLA 的前向传播
Args:
x (torch.Tensor): 输入 (batch_size, seq_len, dim)
start_pos (int): 用于指定当前推理步骤的起始位置,即从序列的哪个位置开始计算
freqs_cis (torch.Tensor): 预先计算的复数 RoPE 矩阵
mask (Optional[torch.Tensor]): 掩码
Returns:
torch.Tensor: 输出 (batch_size, seq_len, dim)
"""
bsz, seqlen, _ = x.size()
end_pos = start_pos + seqlen
# -------------------------- query 部分 --------------------------
q = self.wq_b(self.q_norm(self.wq_a(x)))
q = q.view(bsz, seqlen, self.n_heads, self.qk_head_dim)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
# ----------------------- key / value 部分 -----------------------
kv = self.wkv_a(x)
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
# --------------------------- 矩阵吸收 ---------------------------
wkv_b = self.wkv_b.weight
wkv_b = wkv_b.view(self.n_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
# -------------------------- 注意力实现 --------------------------
if self.training: # 训练阶段不使用缓存
kv = self.kv_norm(kv)
k_pe = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, kv) + torch.einsum("bshr,btr->bsht", q_pe, k_pe)) * self.softmax_scale
else: # 推理阶段使用缓存
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
if mask is not None:
scores += mask.unsqueeze(1)
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
# ----------------------- 计算输出+矩阵吸收 -----------------------
if self.training:
x = torch.einsum("bsht,btc->bshc", scores, kv)
else:
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
return x
forward方法接收的参数包括输入序列x、当前推理步骤的起始位置start_pos、复数RoPE矩阵freqs_cis和掩码mask。其中,start_pos和mask需要了解具体的推理实现等过程,在实现后续模型的训练和推理后,自然会对它们的作用进一步了解,先不着急。接下来,分块来一步一步看forward代码,核心代码可分为五部分。
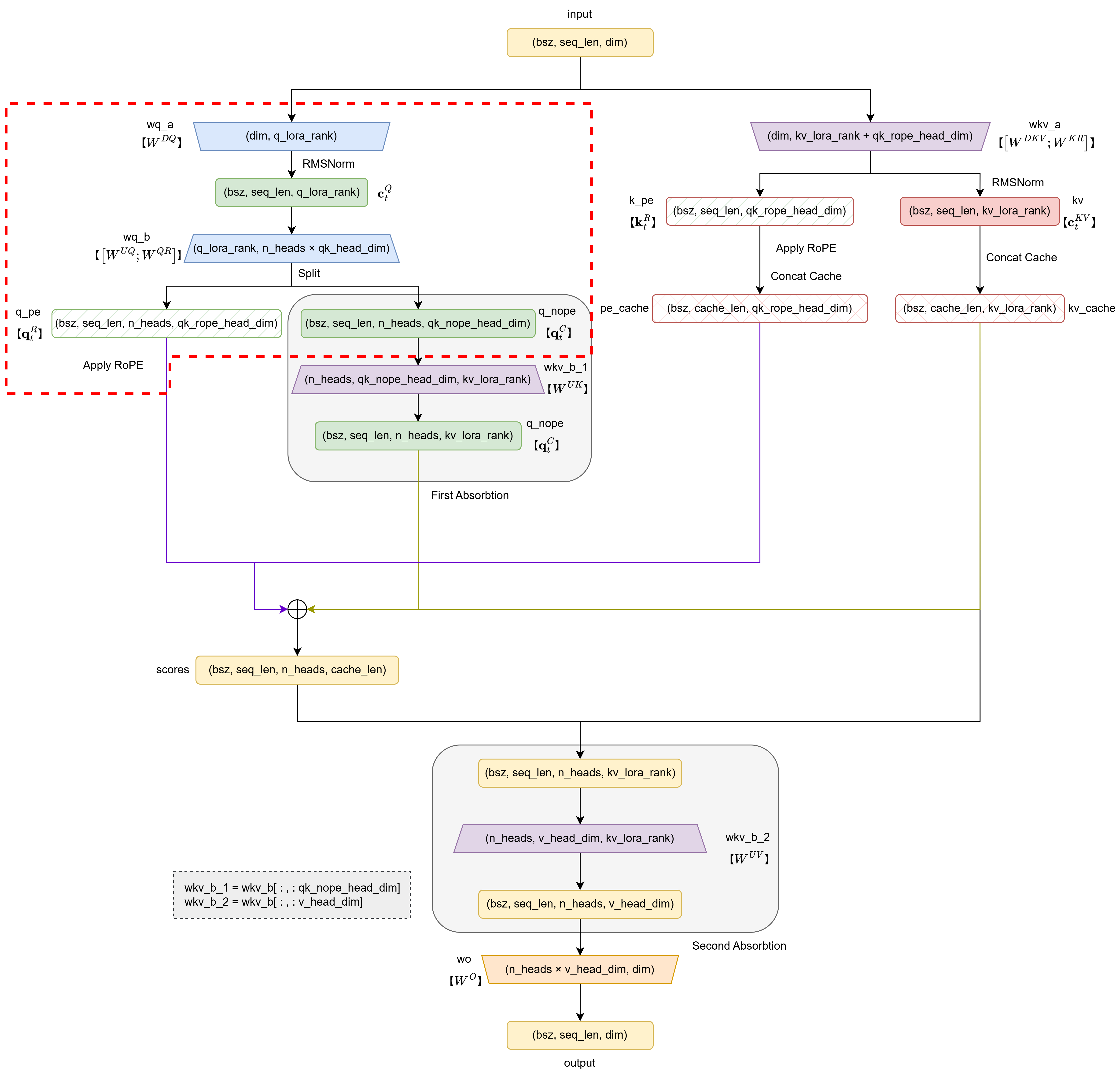
1. query部分
共四行代码:
q = self.wq_b(self.q_norm(self.wq_a(x)))
q = q.view(bsz, seqlen, self.n_heads, self.qk_head_dim)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
第1行:对原始向量$\mathbf{h}_t$依次进行下投影(得到$\mathbf{c}_t^Q$)、RMSNorm和上投影(得到$\mathbf{q}_t^C$)+解耦(得到还未加入位置信息的$\mathbf{q}_t^R$),对应的公式为:
\[\begin{align} \mathbf{c}_t^Q &= W^{DQ} \mathbf{h}_t, &\qquad& \mathbf{c}_t^Q \in \mathbb{R}^{d_c'},W^{DQ}\in\mathbb{R}^{d_c'\times d},\mathbf{h}_t \in \mathbb{R}^d \\ \mathbf{c}_t^Q &= \text{RMSNorm}(\mathbf{c}_t^Q), \\ \mathbf{q}_t^C &= W^{UQ} \mathbf{c}_t^{Q}, &\qquad& \mathbf{q}_t^C \in \mathbb{R}^{d_h n_h},W^{UQ}\in \mathbb{R}^{d_h n_h \times d_c'},\mathbf{c}_t^Q \in \mathbb{R}^{d_c'}\\ \mathbf{q}_t^R &= W^{QR} \mathbf{c}_t^Q, &\qquad& \mathbf{q}_t^R \in \mathbb{R}^{d_h^R n_h},W^{QR} \in \mathbb{R}^{d_h^R n_h \times d_c'},\mathbf{c}_t^Q \in \mathbb{R}^{d_c'} \end{align}\]输入变量x的形状为(batch_size, seq_len, dim),输出变量q实际上是$[\mathbf{q}_t^C;\mathbf{q}_t^R] \in \mathbb{R}^{(d_h+d_h^R)n_h}$,即(batch_size, seq_len, n_heads * qk_head_dim)
第2行:将上一行的输出$[\mathbf{q}_t^C;\mathbf{q}_t^R] \in \mathbb{R}^{(d_h+d_h^R)n_h}$划分注意力头数,即
\[\begin{equation} \left[ {\color{red}{[\mathbf{q}_{t,1}^C;\mathbf{q}_{t,1}^R]} }; {\color{blue}{[\mathbf{q}_{t,2}^C;\mathbf{q}_{t,2}^R]} }; \ldots; {\color{green}{[\mathbf{q}_{t,n_h}^C \mathbf{q}_{t,n_h}^R]} }\right] \leftarrow [\mathbf{q}_t^C;\mathbf{q}_t^R] \in \mathbb{R}^{(d_h+d_h^R)n_h} \end{equation}\]其中,$\mathbf{q}_{t,i}=[\mathbf{q}_{t,i}^C;\mathbf{q}_{t,i}^R]\in \mathbb{R}^{d_h+d_h^R}$是最终执行注意力计算的每个query头,且此时解耦的$\mathbf{q}_{t,i}^R$部分还未加入RoPE。
在这一行,变量q的形状变化为:
(batch_size, seq_len, n_heads * qk_head_dim) -> (batch_size, seq_len, n_heads, qk_head_dim)
第3行:将$\mathbf{q}_{t,i}=[\mathbf{q}_{t,i}^C;\mathbf{q}_{t,i}^R]\in \mathbb{R}^{d_h+d_h^R}$切分为不需携带位置编码的q_nope和需要携带位置编码的q_pe两部分,即$\mathbf{q}_{t,i}^C \in \mathbb{R}^{d_h}$和$\mathbf{q}_{t,i}^R \in \mathbb{R}^{d_h^R}$两部分。
因此,变量形状有:
-
q_nope: (batch_size, seq_len, n_heads, qk_nope_head_dim) -
q_pe: (batch_size, seq_len, n_heads, qk_rope_head_dim)
第4行:为需要携带位置编码的q_pe应用RoPE位置编码,其形状不改变。
至此,完成了下图中红框所示的部分:
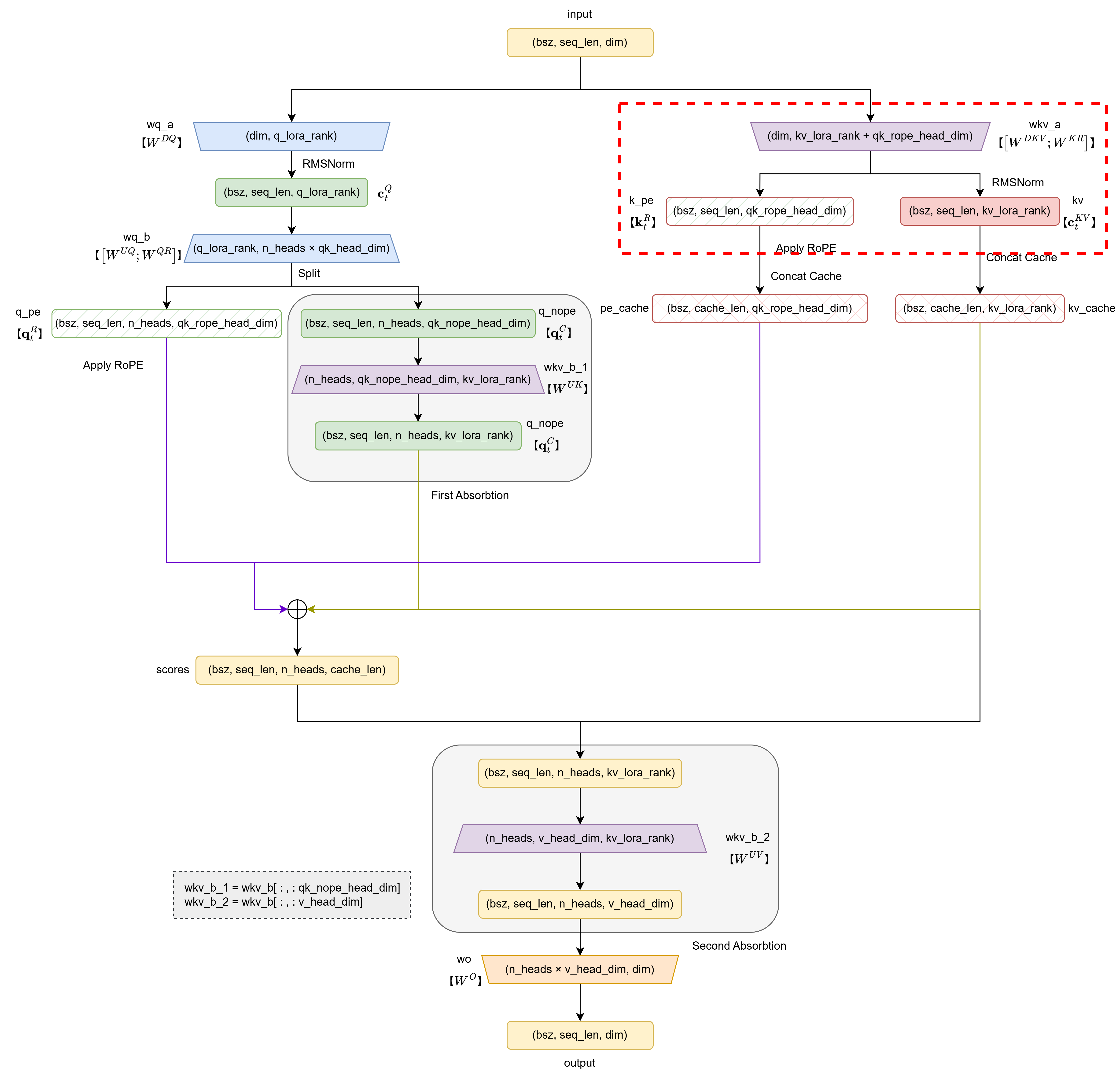
2. key/value部分
共三行代码:
kv = self.wkv_a(x)
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
第1行:对原始向量$\mathbf{h}_t$进行下投影(得到$\mathbf{c}_t^{KV}$)+解耦(得到还未加入位置信息的$\mathbf{k}_t^R$),对应的公式为:
\[\begin{align} \mathbf{c}_t^{KV} &= W^{DKV} \mathbf{h}_t, &\quad& \mathbf{c}_t^{KV} \in \mathbb{R}^{d_c},W^{DKV} \in \mathbb{R}^{d_c \times d},\mathbf{h}_t \in \mathbb{R}^d\\ \mathbf{k}_t^R &= W^{KR} \mathbf{h}_t, &\quad& \mathbf{k}_t^R \in \mathbb{R}^{d_h^R},W^{KR} \in \mathbb{R}^{d_h^R \times d},\mathbf{h}_t \in \mathbb{R}^d \end{align}\]输入变量x的形状为(batch_size, seq_len, dim),输出变量kv实际上是$[\mathbf{c}_t^{KV};\mathbf{k}_t^R]\in\mathbb{R}^{d_c+d_h^R}$,即(batch_size, seq_len, kv_lora_rank + qk_rope_head_dim)
第2行:将$[\mathbf{c}_t^{KV};\mathbf{k}_t^R]\in\mathbb{R}^{d_c+d_h^R}$切分为潜在向量kv和需要携带位置编码的k_pe两部分,即$\mathbf{c}_t^{KV}\in\mathbb{R}^{d_c}$和$\mathbf{k}_t^R\in\mathbb{R}^{d_h^R}$两部分。
因此,变量形状有:
kv: (batch_size, seq_len, kv_lora_rank)k_pe: (batch_size, seq_len, qk_rope_head_dim)
第3行:首先为k_pe添加头数维度,将形状变为(batch_size, seq_len, 1, qk_rope_head_dim),从而适应apply_rotary_emb函数,然后为其应用RoPE位置编码,形状不改变。
至此,完成了下图中红框所示的部分:
3. 第一次矩阵吸收
共三行代码:
wkv_b = self.wkv_b.weight
wkv_b = wkv_b.view(self.n_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
第1行:获取self.wkv_b的权重矩阵,在nn.Linear中,权重矩阵的形状为(out_features, in_features),因此wkv_b的形状为(n_heads * (qk_nope_head_dim + v_head_dim), kv_lora_rank)
第2行:进一步将wkv_b变为(n_heads, qk_nope_head_dim + v_head_dim, kv_lora_rank)。我们知道,wkv_b实际上是$[W^{UK};W^{UV}]\in \mathbb{R}^{(d_h+d_h) n_h \times d_c}$,这一行的目的是为了方便后续切分出$W^{UK}$和$W^{UV}$,它们分别需要吸收到$W^{UQ}$和$W^O$中。
第3行:在query部分的代码实现中,我们得到了q_nope: (batch_size, seq_len, n_heads, qk_nope_head_dim),它实际上是
因此有:
\[\begin{equation} \mathbf{q}_{t,i}^C = W_i^{UQ} \mathbf{c}_t^{Q} \end{equation}\]其中,对于第$i$个注意力头,$W_i^{UQ}\in\mathbb{R}^{d_h \times d_c’}$是$W^{UQ} \in \mathbb{R}^{d_h n_h \times d_c’}$的分块矩阵。同理,正常来说,在key/value部分,本应计算出k_nope,类似的应该有:
当我们聚焦于第$i$个注意力头的计算时,假设位置$t$的query对位置$j$的key做点积计算,会有:
\[\begin{equation}\begin{aligned} {\mathbf{q}_{t,i}^C}^\top \mathbf{k}_{j,i}^C = (W_i^{UQ} \mathbf{c}_t^{Q})^\top W_i^{UK} \mathbf{c}_j^{KV} &= {\mathbf{c}_t^{Q} }^\top ({\color{red}{ {W_i^{UQ} }^\top W_i^{UK} }}) \mathbf{c}_j^{KV}\\ &={\mathbf{c}_t^{Q} }^\top {\color{red}{ {W_i^{UQ'} }^\top} } \mathbf{c}_j^{KV} \\ &= (\underbrace{ {\color{red}{W_i^{UQ'} }} \mathbf{c}_t^{Q} }_{\text{q\_nope} })^\top \mathbf{c}_j^{KV} \end{aligned}\end{equation}\]其中,$W_i^{UQ’}\in \mathbb{R}^{d_c \times d_c’}$是每个注意力头$W_i^{UQ}$吸收了$W_i^{UK}$得到的新矩阵。因此,对所有注意力头而言,有新的$W^{UQ’}\in \mathbb{R}^{d_c n_h \times d_c’}$,那么在矩阵吸收之后,新的q_nope变为$W^{UQ’}\mathbf{c}_t^Q =[W_1^{UQ’} \mathbf{c}_t^Q;W_2^{UQ’} \mathbf{c}_t^Q;\ldots;W_{n_h}^{UQ’} \mathbf{c}_t^Q;]$,即新q_nope的形状变为:
q_nope: (batch_size, seq_len, n_heads, kv_lora_rank)
因此,矩阵吸收后,在key/value部分中是不用计算出k_nope的,直接使用潜在向量kv即可。
上述第3行代码是通过爱因斯坦求和约定:einsum来实现矩阵吸收的。首先从wkv_b中切分出wkv_b[:, :self.qk_nope_head_dim],即形状为(n_heads, qk_nope_head_dim, kv_lora_rank)的部分,它代表了每个头的$W_i^{UK}\in \mathbb{R}^{d_h \times d_c}$。
因此,einsum接收的参数是:
原q_nope: (batch_size, seq_len, n_heads, qk_nope_head_dim) -> (b s h d)wkv_b[:, :self.qk_nope_head_dim]: (n_heads, qk_nope_head_dim, kv_lora_rank) -> (h d c)
对其共享维度d进行求和,得到的输出结果是:
新q_nope: (batch_size, seq_len, n_heads, kv_lora_rank) -> (b s h c)
【思考】:模型训练好后,能否直接将$W^{UQ’}\in \mathbb{R}^{d_c n_h \times d_c’}$保存下来,这样就不用在
forward时重复计算吸收过程?或者能否干脆将它作为初始化的权重来训练,从而省略在forward中进行的矩阵吸收?见【笔记】MLA矩阵吸收分析
至此,完成了下图中红框所示的部分:
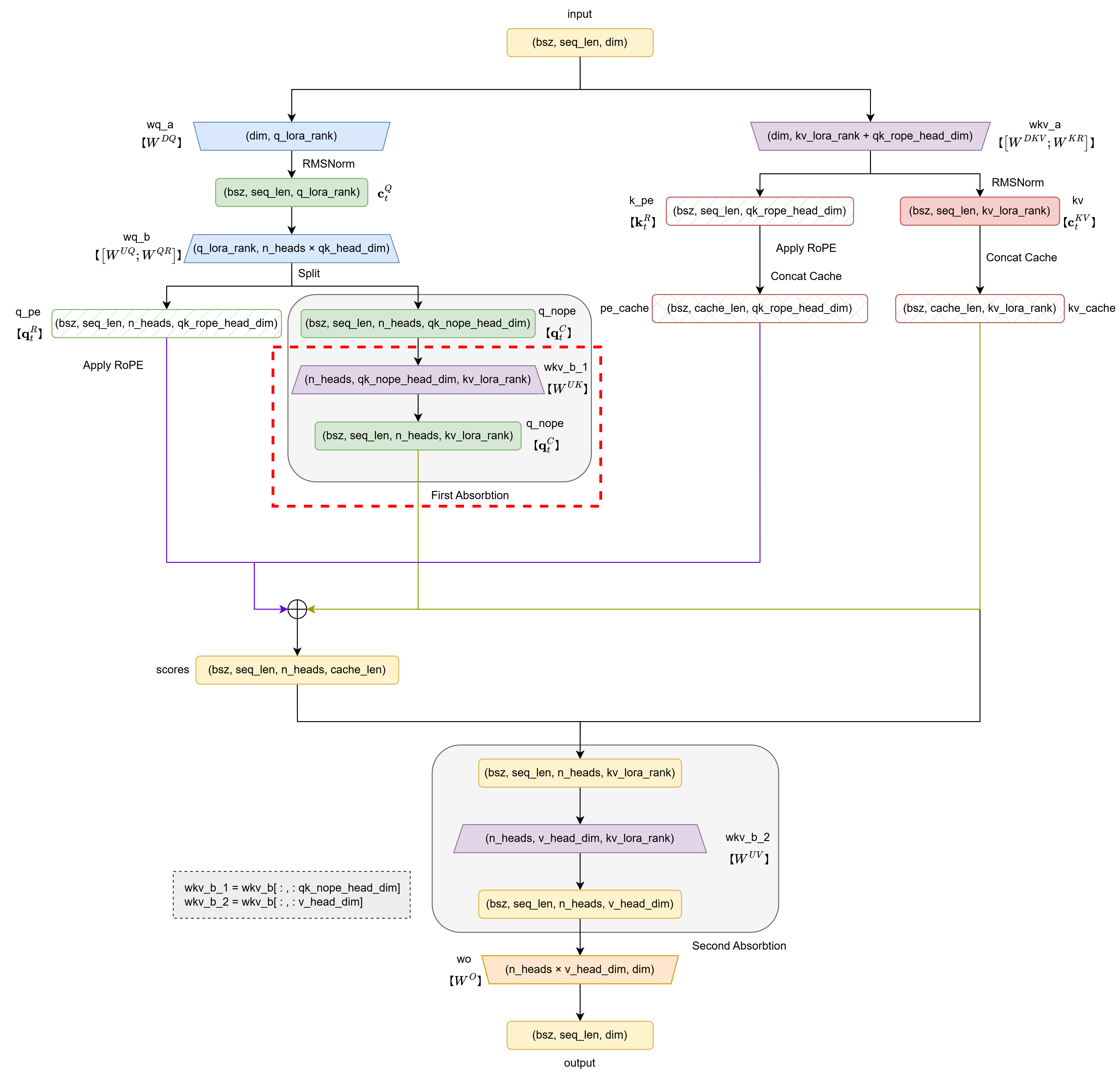
4. 注意力实现
共六行代码:
if self.training: # 训练阶段不使用缓存
kv = self.kv_norm(kv)
k_pe = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, kv) + torch.einsum("bshr,btr->bsht", q_pe, k_pe)) * self.softmax_scale
else: # 推理阶段使用缓存
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
if mask is not None:
scores += mask.unsqueeze(1)
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
从推理计算开始看起:
第6行:为kv应用RMSNorm后,缓存至kv_cache
第7行:在key/value部分中,为了给k_pe添加位置编码,为其添加了head维度,形状变为(batch_size, seq_len, 1, qk_rope_head_dim),因此这里将head维度去除后,缓存至pe_cache
第8、9行:计算注意力分数,这里没有将无位置信息的nope部分和有位置信息的pe部分拼接起来再计算注意力,而是分别计算nope部分和pe部分的点积,然后相加,并乘以注意力计算的缩放因子。这是为了避免不必要的数据移动和冗余计算,从而提高计算效率。
- 对
nope部分:q_nope: (batch_size, seq_len, n_heads, kv_lora_rank) -> (b s h c)kv_cache: (batch_size, cache_len, kv_lora_rank) -> (b t c)score_nope: (batch_size, seq_len, n_heads, cache_len) -> (b s h t)
- 对
pe部分:q_pe: (batch_size, seq_len, n_heads, qk_rope_head_dim) -> (b s h r)pe_cache: (batch_size, cache_len, qk_rope_head_dim) -> (b t r)score_pe: (batch_size, seq_len, n_heads, cache_len) -> (b s h t)
- 因此最终计算的
scores = score_nope + score_pe,形状也为:(batch_size, seq_len, n_heads, cache_len)
通常我们见到的注意力分数形状多为
(batch_size, n_heads, seq_len, cache_len),本质是一样的,只相差一个维度变换操作。
第10、11行:应用掩码mask,后续训练和推理中会详细介绍
第12行:对最后一个维度应用softmax,将点积转换为权重
训练阶段(第1-4行)与推理阶段类似,只是不用进行缓存操作。
至此,完成了下图中红框所示的部分:
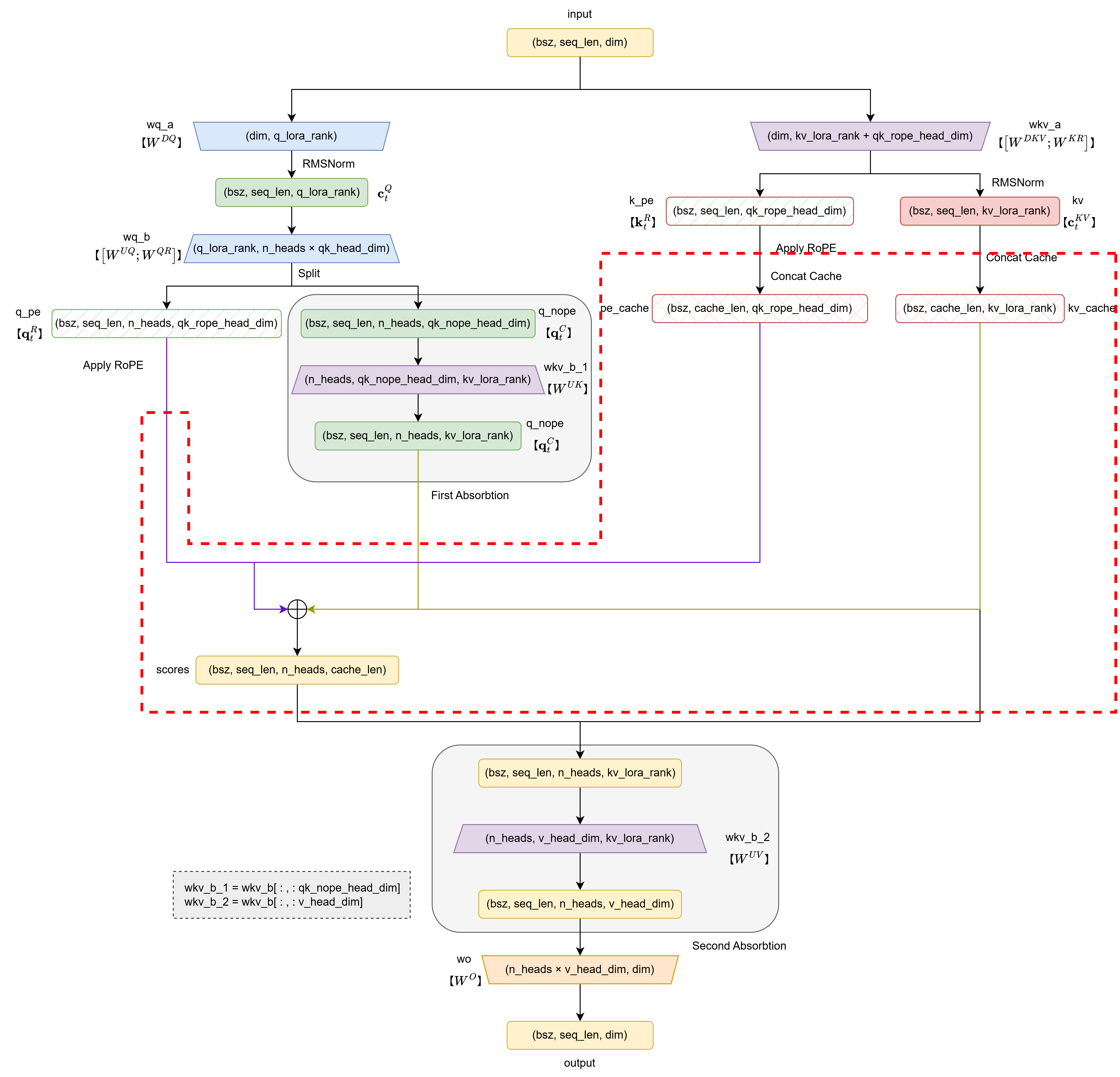
5. 计算输出+第二次矩阵吸收
共三行代码:
if self.training:
x = torch.einsum("bsht,btc->bshc", scores, kv)
else:
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
第二次矩阵吸收同第一次类似,请参考【笔记】MLA矩阵吸收分析。
同样从推理阶段开始看(训练阶段同样只是不用执行缓存操作):
第4行:在计算输出时,会进行$W^{UV}$与$W^O$的矩阵吸收。仍聚焦于第$i$个注意力头,对位置$t$的输出,有:
\[\begin{equation} \begin{aligned} \mathbf{o}_{t,i} &= \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{ {\mathbf{q}_{t,i}^C}^\top \mathbf{k}_{j,i}^C}{\sqrt{d_h} } \right) \mathbf{v}_{j,i}^C \\ &= \sum_{j=1}^{t} \alpha_{j,i} W_i^{UV} \mathbf{c}_j^{KV} \\ &= W_i^{UV} \sum_{j=1}^{t} \alpha_{j,i} \mathbf{c}_j^{KV} \end{aligned} \end{equation}\]其中,$\alpha_{j,i}$ 表示在第 $i$ 个注意力头中,当前位置 $t$ 对位置 $j$ 计算得到的注意力权重。$\mathbf{o}_{t,i}$ 为每个注意力头的输出向量。因此,最终的输出为:
\[\begin{equation} \begin{aligned} \mathbf{u}_t &= W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; \ldots; \mathbf{o}_{t,n_h}] \\ &= W^O [W_1^{UV} \sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV}; W_2^{UV} \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV}; \ldots; W_{n_h}^{UV} \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV}] \\ &= W_1^O W_1^{UV} \sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV} + W_2^O W_2^{UV} \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV} + \ldots + W_{n_h}^O W_{n_h}^{UV} \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV} \\ &= W_1^{O'} \sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV} + W_2^{O'} \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV} + \ldots + W_{n_h}^{O'} \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV} \\ &= W^{O'} [\sum_{j=1}^{t} \alpha_{j,1} \mathbf{c}_j^{KV}; \sum_{j=1}^{t} \alpha_{j,2} \mathbf{c}_j^{KV}; \ldots; \sum_{j=1}^{t} \alpha_{j,n_h} \mathbf{c}_j^{KV}] \end{aligned} \end{equation}\]其中:
- $W^O \in \mathbb{R}^{d \times d_h n_h}$
- $W_i^O \in \mathbb{R}^{d \times d_h}$
- $W_i^{UV} \in \mathbb{R}^{d_h \times d_c}$
- $W_i^{O’} = W_i^O W_i^{UV} \in \mathbb{R}^{d \times d_c}$
- $W^{O’} \in \mathbb{R}^{d \times d_c n_h}$
- $\mathbf{u}_t \in \mathbb{R}^{d}$
第4行代码首先计算了scores和kv_cache相乘,einsum接收的参数是:
-
scores: (batch_size, seq_len, n_heads, cache_len) -> (b s h t) -
kv_cache: (batch_size, cache_len, kv_lora_rank) -> (b t c)
由爱因斯坦求和,对共享维度t求和(即对cache_len长度的value进行加权求和),二者得到中间结果x形状为:
x: (batch_size, seq_len, n_heads, kv_lora_rank) -> (b s h c)
第5行:从wkv_b中切分出wkv_b[:, :self.v_head_dim],即形状为(n_heads, v_head_dim, kv_lora_rank)的部分,它代表了每个头的$W_i^{UV} \in \mathbb{R}^{d_h \times d_c}$,因此,einsum接收的参数是:
x: (batch_size, seq_len, n_heads, kv_lora_rank) -> (b s h c)wkv_b[:, :self.v_head_dim]: (n_heads, v_head_dim, kv_lora_rank) -> (h d c)
由爱因斯坦求和,对共享维度c求和,得到中间结果x形状为:
x: (batch_size, seq_len, n_heads, v_head_dim) -> (b s h d)
第6行:将上述结果进行输出维度转换,即:
x: (batch_size, seq_len, n_heads, v_head_dim)
转换为:
x: (batch_size, seq_len, dim)
至此,完成了下图中红框所示的部分,MLA部分代码完成:
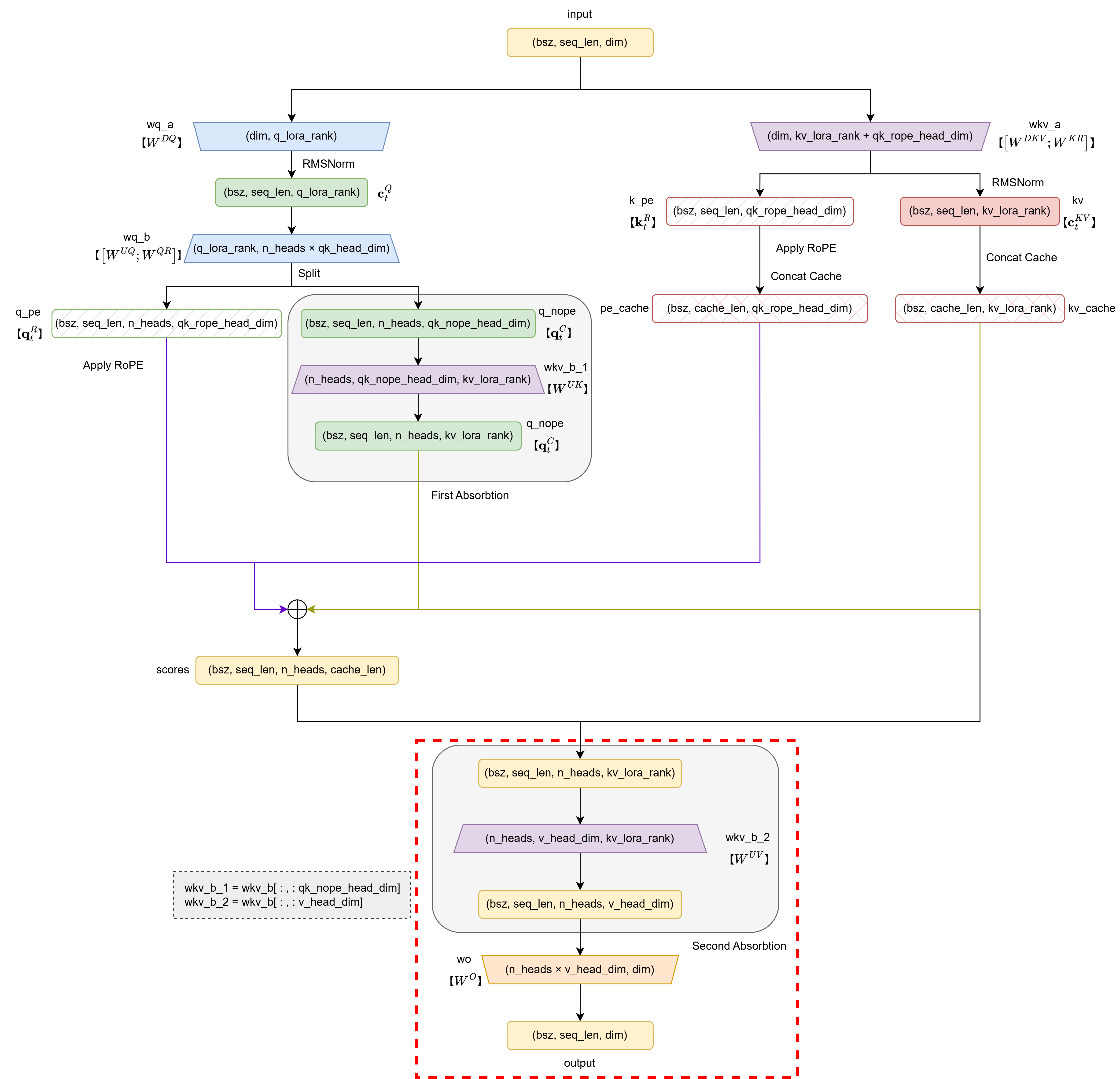
二、MoE实现
MoE部分主要包括四个类,分别是MLP、Expert、Gate和MoE。无辅助损失的负载均衡策略、序列级辅助损失均在此部分实现,由于源代码未开源训练部分,这两块由本人根据论文理解实现。
(一)MLP和Expert
在DeepSeek-V3源码中,MLP和Expert类的结构是完全一致的,只是做了用处的区分。原DeepSeek-V3中,前3层是Dense Layer,这是因为前面几层的负载均衡收敛较慢(DeepSeek 模型架构的特殊选择),MLP用于构建Dense Layer的前馈网络。此外,MLP也用于实例化共享专家。而Expert则专门用于实例化路由专家。这里只列举MLP的代码如下:
class MLP(nn.Module):
"""
前馈层, 前馈方法与Llama3相同
Attributes:
w1 (nn.Module): 实现 input-to-hidden 的转换
w2 (nn.Module): 实现 hidden-to-output 的转换
w3 (nn.Module): 实现 input-to-hidden 的转换
"""
def __init__(self, dim: int, inter_dim: int):
"""
MLP 初始化
Args:
dim (int): 嵌入维度
inter_dim (int): 隐藏层维度
"""
super().__init__()
self.w1 = nn.Linear(dim, inter_dim, bias=False)
self.w2 = nn.Linear(inter_dim, dim, bias=False)
self.w3 = nn.Linear(dim, inter_dim, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
MLP 前向传播
Args:
x (torch.Tensor): 输入张量 (batch_size, seq_len, dim)
Returns:
torch.Tensor: 输出张量 (batch_size, seq_len, dim)
"""
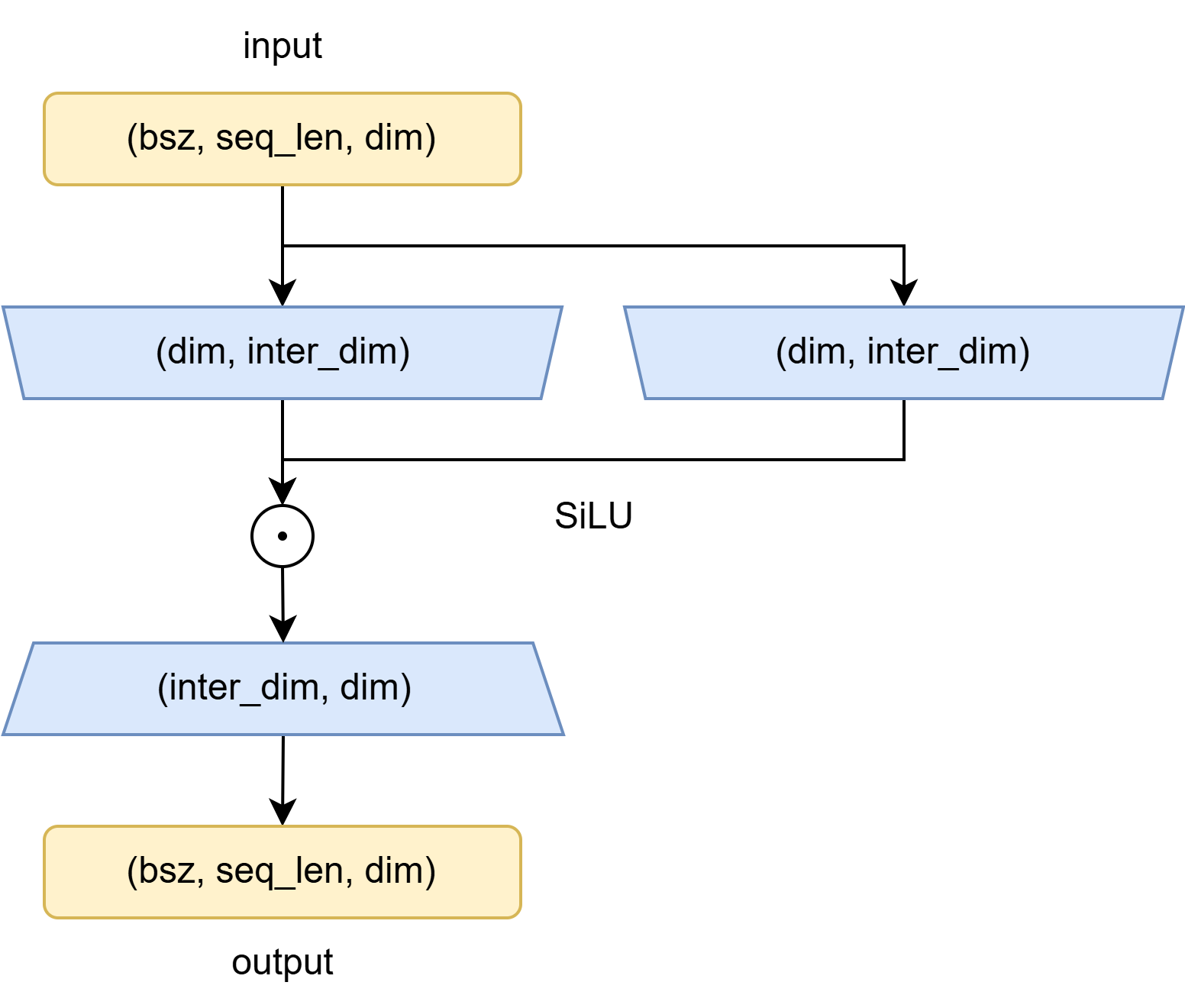
return self.w2(F.silu(self.w1(x)) * self.w3(x))
其中,F.silu函数是$\beta=1$时的SwiGLU。SwiGLU结合了Swish和GLU两者的特点。
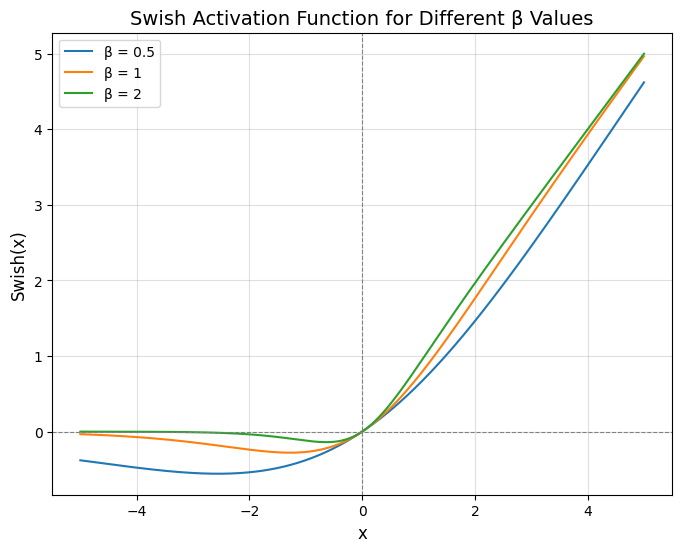
- Swish是一个非线性激活函数,定义如下:
其中,$\beta$为可学习参数。Swish可以比ReLU激活函数更好,因为它在0附近提供了更平滑的转换,这可以带来更好的优化。下图为不同$\beta$值对应的Swish激活函数图像:
- GLU(Gated Linear Unit)定义为两个线性变换的分量积,其中一个线性变换由sigmoid激活。它其实不算是一种激活函数,而是一种神经网络层。它是一个线性变换后面接门控机制的结构。其中门控机制是一个sigmoid函数用来控制信息能够通过多少,定义如下:
LLM中常用的SwiGLU其实就是采用Swish作为激活函数的GLU变体:
\(\begin{equation}\text{SwiGLU}(x)=\text{Swish}(Wx+b)\otimes(Vx+c)\end{equation}\) 使用SwiGLU函数构造一个前馈网络,不使用偏置项,有:
\(\begin{equation} \text{FFNSwiGLU}(x)=W_2(\text{Swish}(W_1x)\otimes(W_3x)) \end{equation}\) 其结构如下图所示:
(二)Gate
Gate主要用于动态路由,其代码如下:
class Gate(nn.Module):
"""
即 Router, MoE 中的门控网口, 用于动态路由
Attributes:
dim (int): 嵌入维度
topk (int): 每个输入激活的专家数量
n_groups (int): 专家的分组数量
topk_groups (int): 选中 topk 个分组
route_scale (float): 路由权重的缩放因子
n_routed_experts (int): 路由的专家数量
weight (torch.nn.Parameter): 门控的可学习权重参数
bias (Optional[torch.nn.Parameter]): 门控的偏置项
original_scores (Optional[torch.Tensor]): 原始的亲和度得分, 形状为 (batch_size * seq_len, n_routed_experts)
"""
def __init__(self, args: DeepSeekV3ModelArgs):
"""
门控网络初始化
Args:
args (ModelArgs): 模型配置参数
"""
super().__init__()
self.dim = args.dim
self.topk = args.n_activated_experts
self.n_groups = args.n_expert_groups
self.topk_groups = args.n_limited_groups
self.route_scale = args.route_scale
self.n_routed_experts = args.n_routed_experts
self.weight = nn.Parameter(torch.empty(args.n_routed_experts, args.dim))
self.bias = nn.Parameter(torch.empty(args.n_routed_experts), requires_grad=False) if args.use_noaux_tc else None
self.original_scores = None
self.reset_parameters()
def reset_parameters(self) -> None:
"""
初始化参数
"""
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
nn.init.zeros_(self.bias)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
门控网络的前向传播
Args:
x (torch.Tensor): 输入张量 (batch_size * seq_len, dim), 在输入前已经调整好形状
Returns:
Tuple[torch.Tensor, torch.Tensor]: 路由权重和选择的专家索引, 形状均为 (batch_size * seq_len, topk)
"""
# -------------------------- 计算亲和度分数 --------------------------
scores_logits = F.linear(x, self.weight, None)
scores = scores_logits.sigmoid()
self.original_scores = scores
scores_for_topk = scores
if self.bias is not None:
scores_for_topk = scores_for_topk + self.bias
# -------------------------- 专家分组 --------------------------
if self.n_groups > 1:
scores_view = scores_for_topk.view(x.size(0), self.n_groups, -1)
if self.bias is None:
group_scores = scores_view.amax(dim=-1)
else:
group_scores = scores_view.topk(2, dim=-1)[0].sum(dim=-1)
indices_groups = group_scores.topk(self.topk_groups, dim=-1)[1]
mask = torch.ones(x.size(0), self.n_groups, dtype=torch.bool, device=x.device)
mask.scatter_(dim=1, index=indices_groups, value=False)
scores_for_topk = scores_view.masked_fill(mask=mask.unsqueeze(-1), value=float("-inf")).flatten(1)
# -------------------------- 计算权重和索引 --------------------------
_, indices = torch.topk(scores_for_topk, self.topk, dim=-1)
weights = scores.gather(dim=1, index=indices)
weights_sum = weights.sum(dim=-1, keepdim=True)
weights = weights / (weights_sum + 1e-6)
weights = weights * self.route_scale
return weights.type_as(x), indices
在Gate类中,我们的目标是返回当前token选中专家的门控权重,和选中专家对应的索引,从而进行下一步计算。同时,在选中专家的过程中,我们会应用无辅助损失的负载均衡策略,即为亲和度得分添加一个根据过往专家负载情况来更新的偏置bias。此外,原文中除了使用无辅助损失的负载均衡策略,还使用了节点路由限制,一方面是为了保证不同节点的负载均衡,另一方面也是为了节省通信开销。由于本项目的模型可以装进单卡,因此所有专家都在一个GPU上。但仍可以通过节点路由限制使用的分组方法来实现专家选择上的负载均衡。
我们首先列出Gate运算的大致过程:
- 对专家进行分组, 共
n_groups个组 - 每个组计算 2 个最大亲和度得分之和,其中,亲和度得分可以使用
bias来调整 - 根据上述结果,选出得分最大的
topk_groups个组 - 从上述
topk_groups个组的所有专家中, 选出topk个专家,也就是最终需要激活的专家
需要注意的是,Gate中的无辅助损失的负载均衡策略属于应用部分,即只负责给亲和度得分加入bias,bias的更新部分的逻辑我们在MoE中实现。bias使用nn.Parameter初始化为0,因此它会作为模型参数的一部分,但是它是不需要梯度的,因为bias的更新逻辑实际上是根据过往的专家负载情况来动态更新的,而不是通过loss。
我们主要看前向传播部分的代码,可以大致分为三个部分:
1. 计算亲和度分数
forward的输入张量形状为(batch_size * seq_len, dim),在输入前已经在外部调整好了形状,后续代码中我们会看到。
scores_logits = F.linear(x, self.weight, None)
scores = scores_logits.sigmoid()
令 $\mathbf{u}_t$ 为第 $t$ 个token的输入,这两行代码对应的公式为:
\[\begin{equation} s_{i,t} = \text{Sigmoid}(\mathbf{u}_t^T \mathbf{e}_i) \end{equation}\]其中:
- $s_{i,t}$ :token与第$i$个专家之间的亲和度得分,即某个token被分配给某个专家的概率或权重
- $\mathbf{e}_i$ :第 $i$ 个路由专家的质心向量,用于衡量token和专家的匹配程度
可见,这里的质心向量实际上就是初始化的self.weight,它会在训练中学习到。scores的形状为(batch_size * seq_len, n_routed_experts)。
self.original_scores = scores
scores_for_topk = scores
这里对求得的scores进行了两个赋值。第一个赋值是因为在后续的MoE中,实现序列级辅助损失时,需要用到token对专家的原始得分,因此需要保存下来,以便后续使用。第二个赋值是为了避免后续对scores的原地操作,从而导致梯度回传时出现问题。
if self.bias is not None:
scores_for_topk = scores_for_topk + self.bias
这里对原始分数加上了bias,从而能够影响后续对专家的选择。
2. 专家分组
scores_view = scores_for_topk.view(x.size(0), self.n_groups, -1)
若对专家进行了分组,则将原始得分的形状由(batch_size * seq_len, n_routed_experts)变为(batch_size * seq_len, n_groups, n_routed_experts_per_group)。
if self.bias is None:
group_scores = scores_view.amax(dim=-1)
else:
group_scores = scores_view.topk(2, dim=-1)[0].sum(dim=-1)
如果没有应用无辅助损失的负载均衡策略,就选取每一组最大的得分作为这组的得分,如果使用了无辅助损失的负载均衡策略,就选组每一组top 2的得分之和作为这一组的得分。
indices_groups = group_scores.topk(self.topk_groups, dim=-1)[1]
topk函数会返回一个元组,即(values, indicies),这里从所有组的得分中,选出topk_groups个组的索引,后续将从这几个组的所有专家中,选出最终的topk个专家。
mask = torch.ones(x.size(0), self.n_groups, dtype=torch.bool, device=x.device)
mask.scatter_(dim=1, index=indices_groups, value=False)
首先创建一个形状为(x.size(0), self.n_groups),即 (batch_size, n_groups)的全True(全1)的mask张量。然后使用scatter_()函数将选中的组标记为False。scatter_()的作用是:
- 按
index指定的位置,将value的值填充到目标张量。 - 沿
dim维度 进行填充(例如dim=0按行,dim=1按列)。
这样,mask对选中的组为False,对未选中的组为True。
scores_for_topk = scores_view.masked_fill(mask=mask.unsqueeze(-1), value=float("-inf")).flatten(1)
最后,首先将mask增加最后一个维度,变为(batch_size * seq_len, n_groups, 1),以适应分数张量(batch_size * seq_len, n_groups, n_routed_experts_per_group),将对应mask为True的,也就是未选中的组的所有专家得分置为负无穷,这样就只保留了选中组的所有专家的得分,并展平为(batch_size * seq_len, n_routed_experts)。
3. 计算权重和索引
_, indices = torch.topk(scores_for_topk, self.topk, dim=-1)
从选中组的所有专家中,选出topk个专家的索引,这就是最终确定需要激活的专家。
weights = scores.gather(dim=1, index=indices)
weights_sum = weights.sum(dim=-1, keepdim=True)
weights = weights / (weights_sum + 1e-6)
weights = weights * self.route_scale
gather()函数用于按照指定索引index和维度dim提取数据。提取出的数据形状为(batch_size * seq_len, topk),将这topk个专家得分进行归一化,并进行缩放(缩放self.rout_scale默认为1,根据需要调整),就得到了每个专家的权重。最后将权重和选中专家索引返回,用于下一步计算。
(三)MoE
MoE基于上述类构造,并加入了无辅助损失负载均衡策略的bias更新逻辑和序列级辅助损失逻辑,完整代码如下:
class MoE(nn.Module):
"""
Mixture-of-Experts (MoE) 混合专家模块
Attributes:
dim (int): 嵌入维度
n_routed_experts (int): 路由专家数量
n_activated_experts (int): 每个输入激活的专家数
gate (nn.Module): 门控机制
experts (nn.ModuleList): 专家列表
shared_experts (nn.Module): 共享专家
use_seq_aux (bool): 是否使用序列级别的辅助损失
seq_aux_alpha (float): 序列级别的辅助损失的权重
bias_update_speed (float): 偏置更新速度
"""
def __init__(self, args: DeepSeekV3ModelArgs):
"""
MoE 初始化
Args:
args (ModelArgs): 模型配置参数
"""
super().__init__()
self.dim = args.dim
self.n_routed_experts = args.n_routed_experts
self.n_activated_experts = args.n_activated_experts
self.gate = Gate(args)
self.experts = nn.ModuleList([Expert(args.dim, args.moe_inter_dim) for _ in range(self.n_routed_experts)])
self.shared_experts = MLP(args.dim, args.n_shared_experts * args.moe_inter_dim)
self.use_seq_aux = args.use_seq_aux
self.seq_aux_alpha = args.seq_aux_alpha
self.bias_update_speed = args.bias_update_speed
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
"""
MoE 前向传播
Args:
x (torch.Tensor): 输入张量 (batch_size, seq_len, dim)
Returns:
Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]: 输出张量 (batch_size, seq_len, dim), 序列级辅助损失, 全局负载情况
"""
# -------------------- 变量准备 --------------------
shape = x.size()
bsz, seqlen = shape[:2]
x = x.view(-1, self.dim)
weights, indices = self.gate(x)
y = torch.zeros_like(x)
counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts)
global_counts = None
# -------------------- 无辅助损失负载均衡策略 --------------------
if self.gate.bias is not None and self.training:
global_counts = counts.clone()
if dist.is_available() and dist.is_initialized():
dist.all_reduce(global_counts, op=dist.ReduceOp.SUM)
avg_count = sum(global_counts).float() / self.n_routed_experts
is_distributed_and_master = dist.is_initialized() and dist.get_rank() == 0
is_not_distributed = not dist.is_initialized()
if is_distributed_and_master or is_not_distributed:
for i, count in enumerate(global_counts):
error = avg_count - count
self.gate.bias.data[i] += self.bias_update_speed * torch.sign(error)
if dist.is_available() and dist.is_initialized():
dist.broadcast(self.gate.bias.data, src=0)
# -------------------- 序列级别的辅助损失 --------------------
if self.use_seq_aux and self.training:
scores_for_seq_aux = self.gate.original_scores.view(bsz, seqlen, -1)
scores_for_seq_aux = scores_for_seq_aux / scores_for_seq_aux.sum(dim=-1, keepdim=True)
P_i = scores_for_seq_aux.mean(dim=1)
f_i = F.one_hot(indices.view(bsz, -1), num_classes=self.n_routed_experts)
f_i = f_i.sum(dim=1)
f_i = (f_i * self.n_routed_experts) / (self.n_activated_experts * seqlen)
seq_aux_loss = (f_i * P_i).sum() * self.seq_aux_alpha
else:
seq_aux_loss = None
# -------------------- 计算专家输出 --------------------
for i in range(self.n_routed_experts):
if counts[i] == 0:
continue
expert = self.experts[i]
idx, top = torch.where(indices == i)
y[idx] += expert(x[idx]) * weights[idx, top, None]
z = self.shared_experts(x)
return (y + z).view(shape), seq_aux_loss, global_counts
MoE的前向传播部分同样分割为几个部分,逐部分介绍:
1. 变量准备
shape = x.size()
bsz, seqlen = shape[:2]
x = x.view(-1, self.dim)
weights, indices = self.gate(x)
y = torch.zeros_like(x)
global_counts = None
这几行代码均用于准备或初始化后面需要用到的变量,其中x被重新划分为形状(batch_size * seq_len, dim),然后输入到Gate中,获取到的weights和indices形状均为(batch_size * seq_len, topk)。global_counts用于记录每个批次里全局的专家激活次数情况,这里的“全局”意思是,如果使用ddp训练,记录的是所有GPU上专家激活次数的总和。
counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts)
bincount()函数用于计算非负整数张量中每个值的出现次数。indices.flatten()将每个token激活的专家索引由(batch_size * seq_len, topk)展平为(batch_size * seq_len * topk),参数minlength指定了输出张量的最小长度,使在当前的indices.flatten()中,某些专家索引可能一次都没有出现,设置minlength=self.n_routed_experts可以确保输出的counts张量长度一定等于总的专家数量。如果某个专家的索引i(其中i < self.n_routed_experts)在输入中没有出现,那么输出counts张量中对应位置counts[i]的值将是 0。综上,counts保存了一个batch里每个专家对应的激活次数。
2. 无辅助损失负载均衡策略
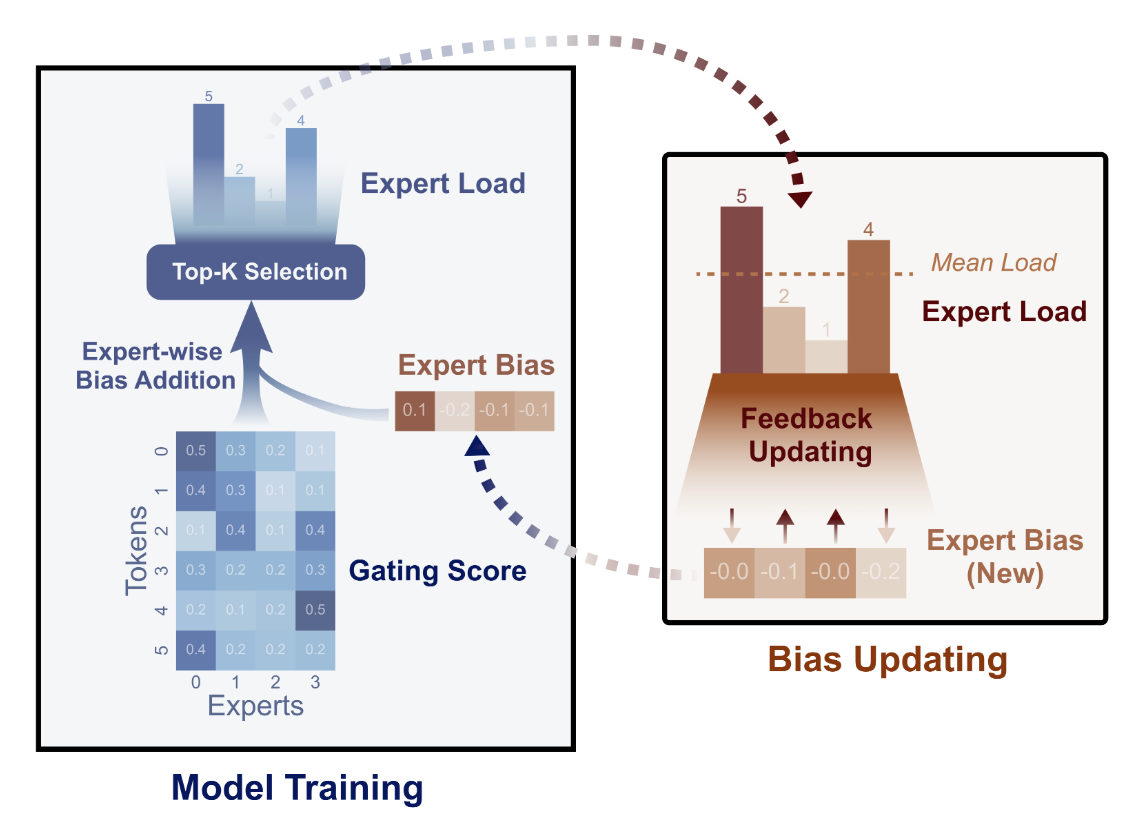
无辅助损失负载均衡策略bias更新的过程如下图所示,该过程只在训练时使用:
global_counts = counts.clone()
if dist.is_available() and dist.is_initialized():
dist.all_reduce(global_counts, op=dist.ReduceOp.SUM)
avg_count = sum(global_counts).float() / self.n_routed_experts
在经过Gate后,本batch的专家负载情况就确定了,因此能够根据本轮的负载情况调整bias的值,从而使下一个batch的负载情况更加均衡。如果当前处于ddp训练环境,那么每个GPU的专家负载情况是不同的,那么每个GPU分别更新bias的值也会不同,因此要基于所有GPU的专家激活情况来统一确定如何更新bias。首先,将本GPU的负载计数counts拷贝给global_counts,如果当前处于ddp训练环境,就收集所有GPU的global_counts,得到全局负载情况。最后计算全局所有专家的平均激活情况avg_counts。
is_distributed_and_master = dist.is_initialized() and dist.get_rank() == 0
is_not_distributed = not dist.is_initialized()
if is_distributed_and_master or is_not_distributed:
for i, count in enumerate(global_counts):
error = avg_count - count
self.gate.bias.data[i] += self.bias_update_speed * torch.sign(error)
if dist.is_available() and dist.is_initialized():
dist.broadcast(self.gate.bias.data, src=0)
如果当前是ddp训练中的主进程,或者当前是使用单卡进行训练,那么计算平均负载情况与每个专家实际激活的差值,并基于此差值和偏置更新速度来计算新的bias值。最后,如果是ddp,就将这个新的bias广播给所有的GPU,这样就确保了每个GPU的模型参数更新是一致的。以上计算流程源于论文Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts中的算法:

3.序列级别的辅助损失
无辅助损失的负载均衡策略主要关注全局的专家负载均衡,确保在整个batch级别上,专家的负载相对均衡。但在序列级别(Sequence-Wise)上,仍然可能出现负载不均衡的情况。例如,一个输入序列中的多个token可能会集中分配给某些专家,导致这些专家在单个序列内负载过高。序列级别的辅助损失只在训练时计算。
首先回顾序列级辅助损失的计算公式:
\[\begin{align} \mathcal{L}_{\text{Bal} } &= \alpha \sum_{i=1}^{N_r} f_i P_i \\ f_i = \frac{N_r}{K_r T} \sum_{t=1}^{T} &\mathbb{I}(s_{i,t} \in \text{Topk}(\{s_{j,t} \mid 1 \leq j \leq N_r\}, K_r)) \\ s_{i,t}' &= \frac{s_{i,t} }{\sum_{j=1}^{N_r} s_{j,t} } \\ P_i &= \frac{1}{T} \sum_{t=1}^{T} s_{i,t}' \end{align}\]其中:
- $\alpha$ :平衡因子,会被设置为一个非常小的值
- $\mathbb{I}(\cdot)$ :指标函数,若符合括号中的情况,则记为1,不符合则记为0
- $T$ :序列中的token数
- $s_{i,t}’$ :第 $t$ 个token在第 $i$ 个专家上的归一化亲和度得分【注意:与gate不同,这是对所有的得分进行归一化】
- $P_i$ :第 $i$ 个专家在每个token上的归一化亲和度得分均值
- $\mathbb{I}(s_{i,t} \in \text{Topk}({s_{j,t} \mid 1 \leq j \leq N_r}, K_r))$ :对于第 $i$ 个专家,若被第 $t$ 个token激活(是top-k之一),则记为1,否则记为0
- $\frac{1}{T} \sum_{t=1}^{T} \mathbb{I}(s_{i,t} \in \text{Topk}({s_{j,t} \mid 1 \leq j \leq N_r}, K_r))$ :第 $i$ 个专家在每个token上的平均激活次数
- $\frac{N_r}{K_r}$ :缩放系数
- $f_iP_i$ :第 $i$ 个专家在每个token上的平均激活次数乘以平均得分
为什么要乘 $\frac{N_r}{K_r}$ ?
在理想完全均匀的情况下:每个 token 会选 $K_r$ 个专家,专家总数是 $N_r$,那么对任意一个专家,被选中的期望概率应该是 $\frac{K_r}{N_r}$ 。也就是说,在均衡状态下,专家 $i$ 的被选中占比应当约等于 $\frac{K_r}{N_r}$。为了让均衡状态对应一个统一的标尺(通常希望均衡时 $f_i \approx 1$ ),因此乘上系数 $\frac{N_r}{K_r}$。
- $f_i>1$:这个专家在该序列里被选得比均匀情况更频繁(过载倾向)
- $f_i<1$:被选得更少(欠载倾向)
scores_for_seq_aux = self.gate.original_scores.view(bsz, seqlen, -1)
scores_for_seq_aux = scores_for_seq_aux / scores_for_seq_aux.sum(dim=-1, keepdim=True)
P_i = scores_for_seq_aux.mean(dim=1)
首先将Gate的原始得分从(batch_size * seq_len, n_routed_experts)变为(batch_size, seq_len, n_routed_experts),此即原始的$s_{i,t}$,沿着n_routed_experts的方向归一化,形成$s_{i,t}’$。而后沿着token的方向求平均,得到$P_i$,形状为(batch_size, n_routed_experts),含义为第$i$个专家在一个序列中每个token上的平均归一化亲和度得分。
f_i = F.one_hot(indices.view(bsz, -1), num_classes=self.n_routed_experts)
f_i = f_i.sum(dim=1)
f_i = (f_i * self.n_routed_experts) / (self.n_activated_experts * seqlen)
seq_aux_loss = (f_i * P_i).sum() * self.seq_aux_alpha
现在来计算$f_i$,即第$i$个专家在一个序列中每个token上的平均激活次数。indices的初始形状为(batch_size * seq_len, topk),表示一个batch中每个token激活了哪些专家。现在我们需要计算的是在一个batch的每个序列中,每个专家被哪些token激活,可以使用one-hot编码来实现这一过程。
- 上述代码第1行:首先将
indices形状变为(batch_size, seq_len * topk),而后使用one-hot编码,类别数为n_routed_experts,得到形状为(batch_size, seq_len * topk, n_routed_experts)的ont-hot编码。 - 上述代码第2行:沿着
seq_len * topk维度相加后,可求出每个专家被多少个token激活,得到形状(batch_size, n_routed_experts),得到了$\sum_{t=1}^{T} \mathbb{I}(s_{i,t} \in \text{Topk}({s_{j,t} \mid 1 \leq j \leq N_r}, K_r))$。 - 上述代码第3行:乘以$\frac{N_r}{K_r T}$系数,得到第$i$个专家在一个序列中每个token上的平均激活次数。
最后,根据$\mathcal{L}_{\text{Bal} } = \alpha \sum_{i=1}^{N_r} f_i P_i$求得当前层的MoE所计算出的序列级辅助损失。直观理解上, $P_i$ 可由调整模型权重来改变,而 $f_i$ 是由 $P_i$ 导致的客观结果,专家 $i$ 的得分大,自然被激活的次数就多。因此,若在一个序列中,各个token最终激活专家 $i$ 的频率 $f_i$ 很大,那么该专家的得分 $P_i$ 就应该减小,反之亦然,从而鼓励每个序列上的专家负载变得均衡。
4. 计算专家输出
for i in range(self.n_routed_experts):
if counts[i] == 0:
continue
expert = self.experts[i]
idx, top = torch.where(indices == i)
y[idx] += expert(x[idx]) * weights[idx, top, None]
遍历counts,如果第i个元素不为0,说明第i个路由专家被激活了。indices的形状为 (batch_size * seq_len, topk),torch.where(indices == i)用于找到激活了第i个专家的token,idx代表行索引(即第几个 token),top代表列索引(即该token的top几选择),idx和top的类型为torch.Tensor。x的形状为(batch_size * seq_len, dim),将x中索引为idx的token输入到它激活的专家expert中,同时乘以其对应的权重weights[idx, top, None],将其赋值给前面初始化的y。遍历完counts之后,y中只保留的激活专家的输出值,未激活的则为0。
z = self.shared_experts(x)
z计算出共享专家的输出,而后将共享专家和路由专家相加,并转换为原始的(batch_size, seq_len, dim)返回。此外,还返回了序列级辅助损失和全局专家负载情况,前者用于后续收集各层的总loss,最终用于梯度计算,后者用于输出到模型外部,记录分析每层专家的负载情况。
三、Transformer Block实现
Transformer Block的实现相对简单,只需将前面的各模块封装起来,代码如下:
class Block(nn.Module):
"""
Transformer Block, 包括 Attention 和 Feed-Forward 部分
Attributes:
attn (nn.Module): 注意力层 (MLA)
ffn (nn.Module): 前馈网络 (MoE)
attn_norm (nn.Module): 注意力层的 Layer Normalization
ffn_norm (nn.Module): 前馈网络的 Layer normalization
"""
def __init__(self, layer_id: int, args: DeepSeekV3ModelArgs):
"""
初始化 Transformer Block
Args:
layer_id (int): Transformer 的层索引
args (ModelArgs): 模型配置参数
"""
super().__init__()
self.attn = MLA(args)
self.ffn = MLP(args.dim, args.inter_dim) if layer_id < args.n_dense_layers else MoE(args)
self.attn_norm = RMSNorm(args.dim)
self.ffn_norm = RMSNorm(args.dim)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
"""
Transformer Block 的前向传播
Args:
x (torch.Tensor): 输入 (batch_size, seq_len, dim)
start_pos (int): 用于指定当前推理步骤的起始位置,即从序列的哪个位置开始计算
freqs_cis (torch.Tensor): 预先计算的复数 RoPE 矩阵
mask (Optional[torch.Tensor]): 掩码
Returns:
Tuple[torch.Tensor, Optional[torch.Tensor]]: 输出 (batch_size, seq_len, dim)
"""
x = x + self.attn(self.attn_norm(x), start_pos, freqs_cis, mask)
if isinstance(self.ffn, MoE):
h, seq_aux_loss, global_counts = self.ffn(self.ffn_norm(x))
return x + h, seq_aux_loss, global_counts
x = x + self.ffn(self.ffn_norm(x))
return x, None, None
其中,需要注意的仅有以下几点:
- FFN的前
n_dense_layers层使用MLP前馈,后面的则使用MoE前馈。 - Attention和FFN前,均需使用
RMSNorm,并应用残差连接。
四、MTP实现
由于DeepSeek-V3未开源训练代码,因此MTP的代码实现仅基于个人理解,未必准确。在【论文解读】DeepSeek-V3中,介绍了MTP的基本原理,然而,个人认为原文中的配图和公式具有一定的迷惑性,在此我们进一步深入剖析。论文原图如下:
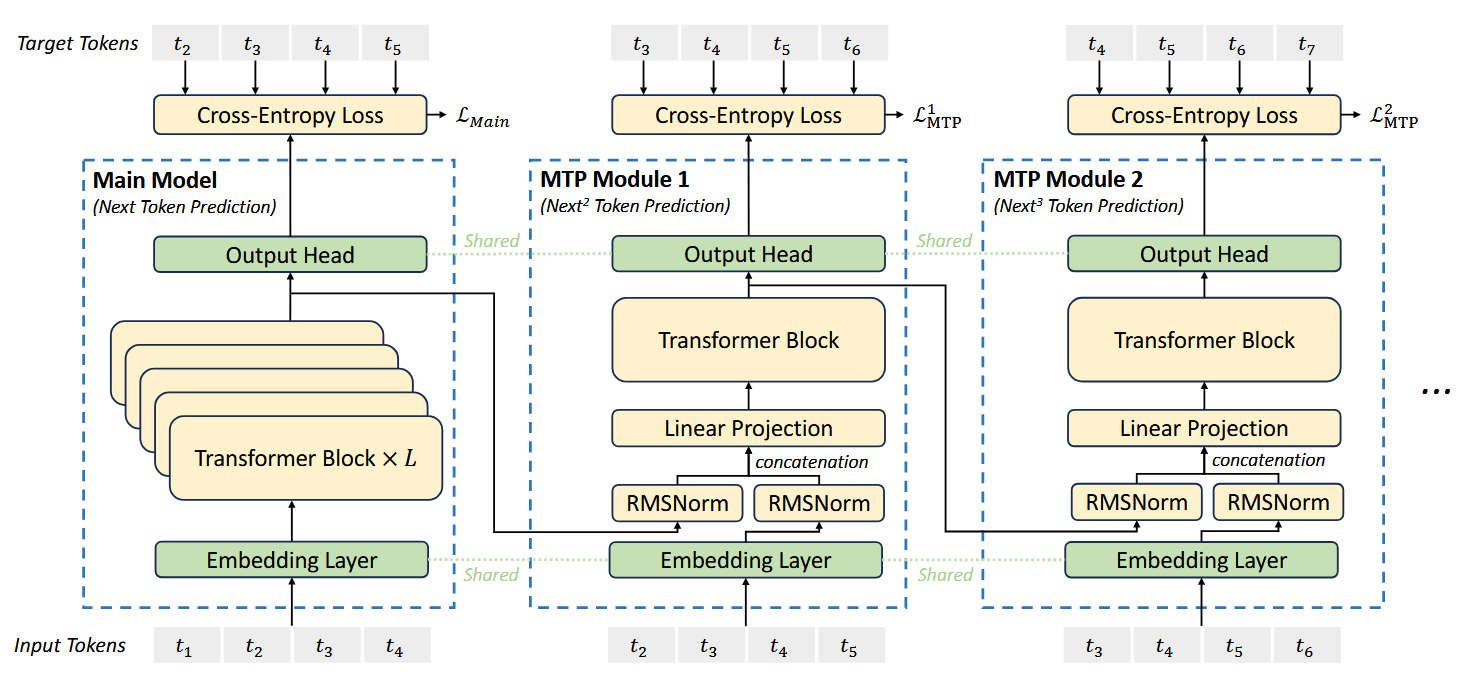
首先结合原文图片看MTP的公式表达。对于输入的第 $i$ 个token $t_i$ ,在预测深度为 $k$ 时,首先通过投影矩阵融合第 $k-1$ 个预测深度的输出表征 $\mathbf{h}_i^{k-1} \in \mathbb{R}^d$ 和第 $i+k$ 个token的Embedding $\text{Emb}(t_{i+k}) \in \mathbb{R}^d$ :
\[\begin{equation} \mathbf{h}_i^{'k} = M_k \left[ \text{RMSNorm}(\mathbf{h}_i^{k-1}); \text{RMSNorm}(\text{Emb}(t_{i+k})) \right] \end{equation}\]其中,$[\cdot ; \cdot]$ 表示拼接操作。特别的,当 $k=1$ 时,$\mathbf{h}_i^{k-1}$ 就是主模型的表征。另外,注意每个MTP模块的Embedding层和输出头,都是与主模型共享的。融合后的 $\mathbf{h}_i^{‘k}$ 作为输入,输入到第 $k$ 个深度的Transformer模块中,产生输出表征 $\mathbf{h}_i^{k}$ :
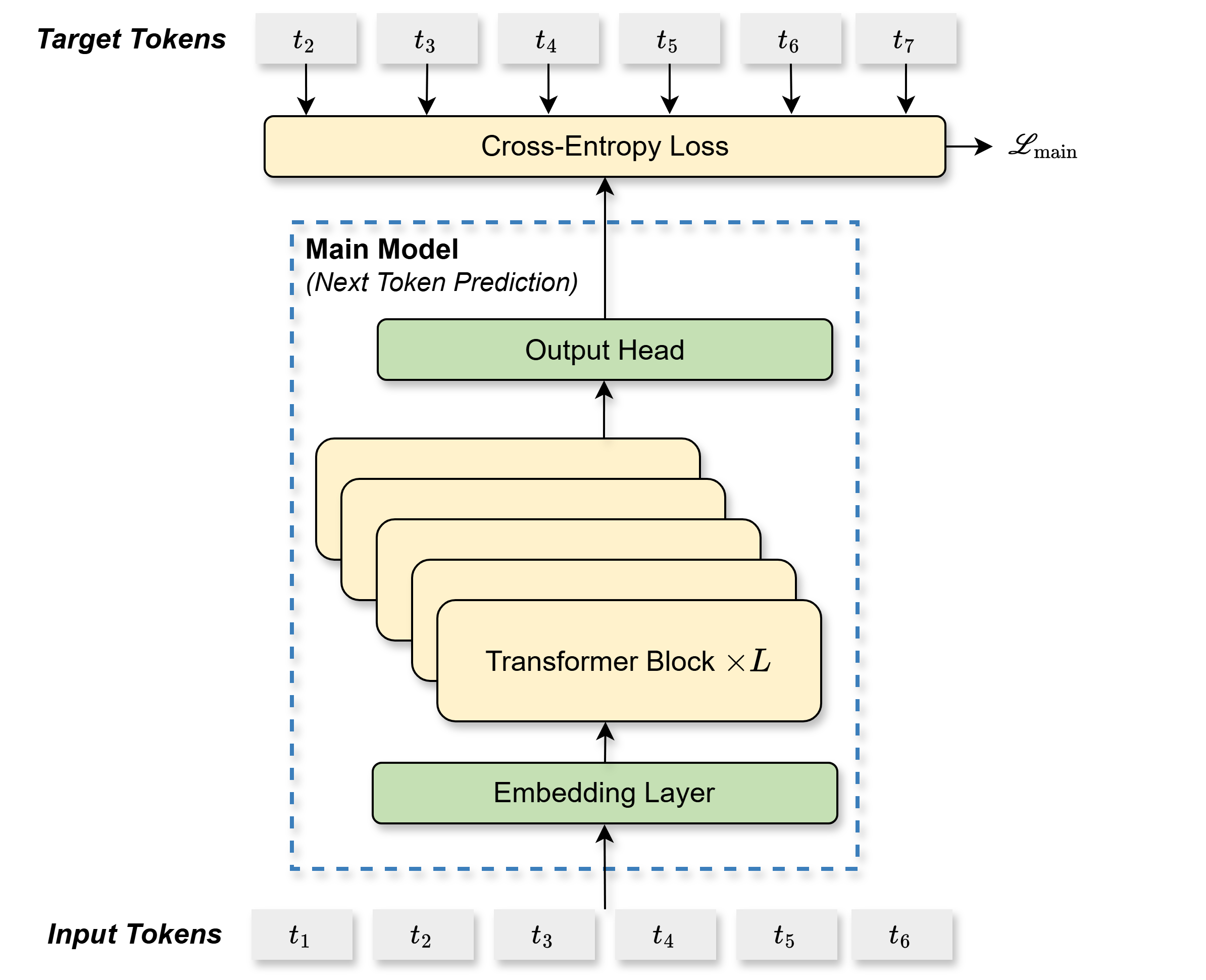
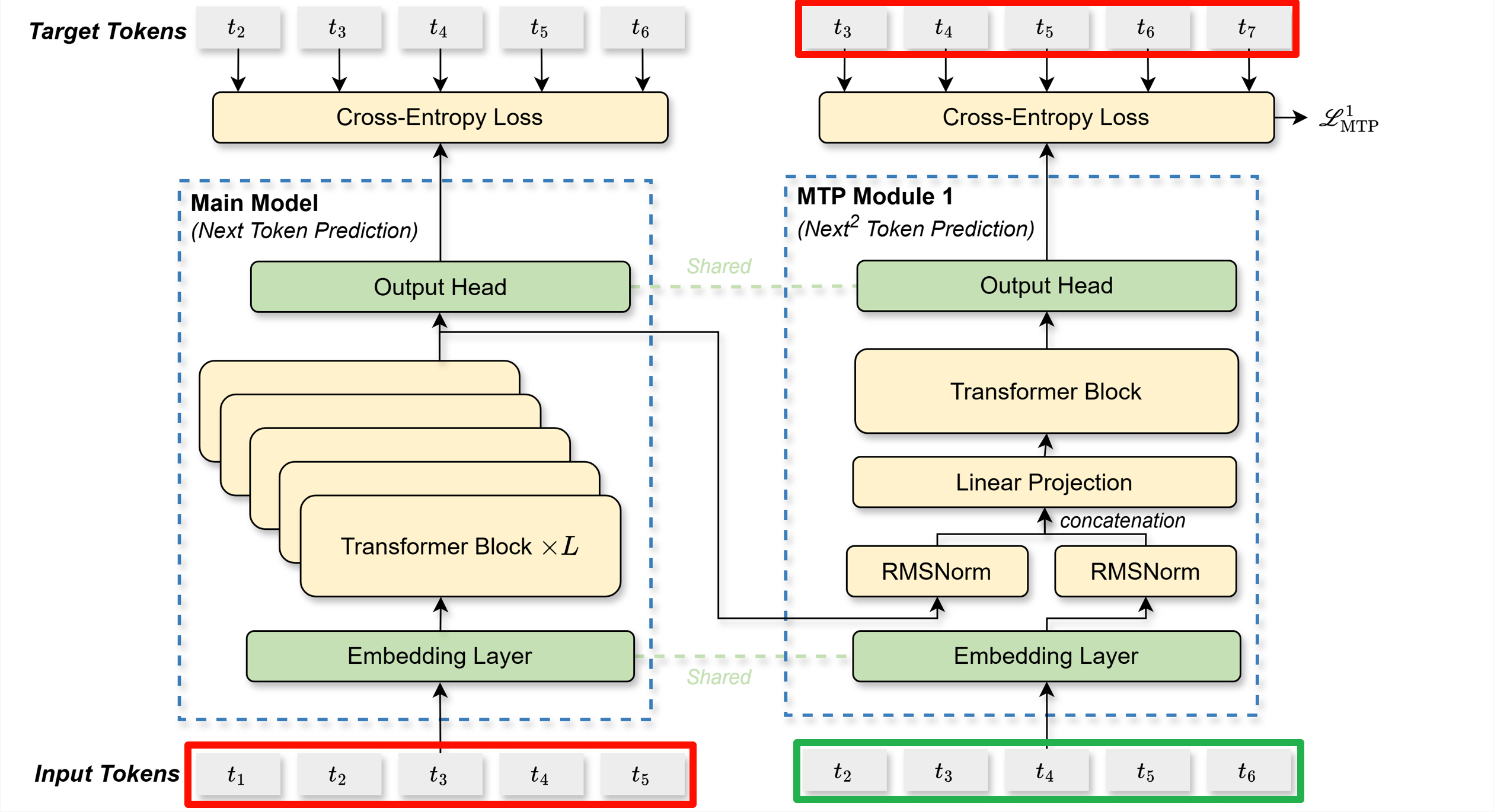
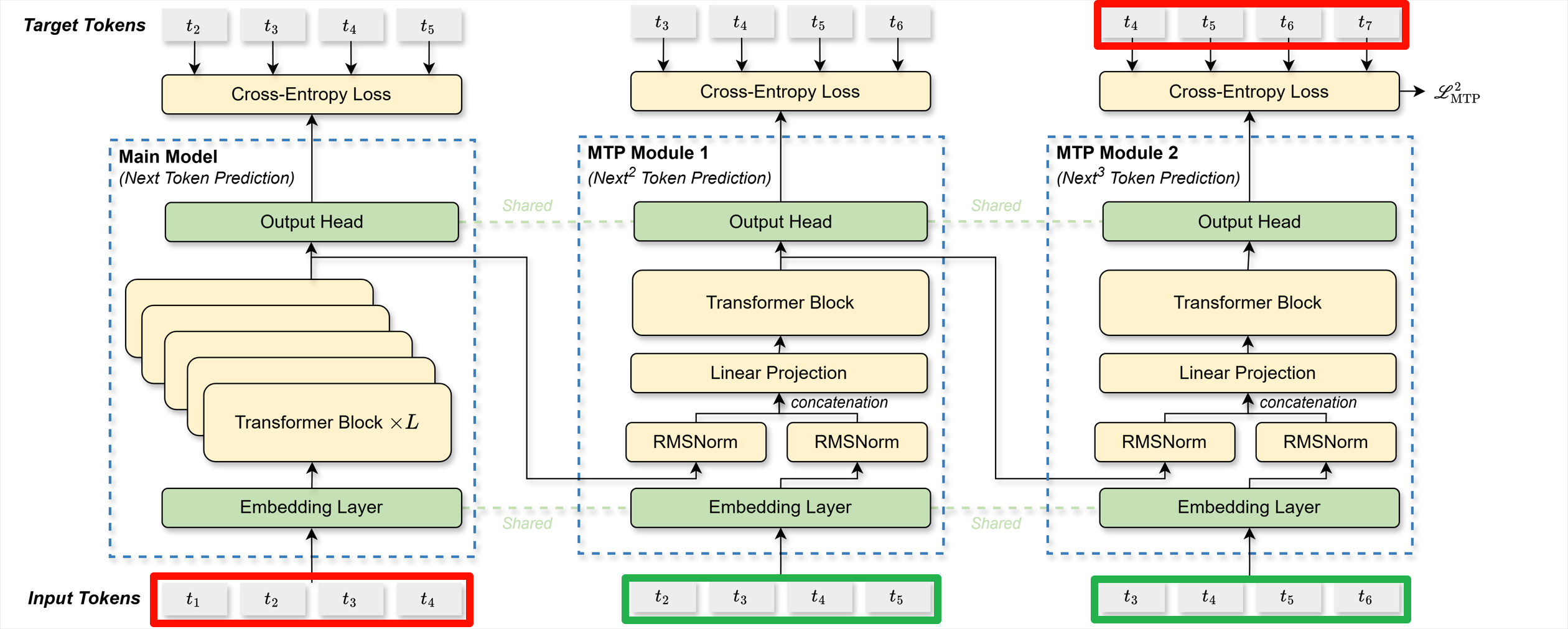
\[\begin{equation} \mathbf{h}_{1:T-k}^k = \text{TRM}_k(\mathbf{h}_{1:T-k}^{'k}) \label{eq:trm} \end{equation}\]这里需要着重理解公式$\eqref{eq:trm}$中的下标$1:T-k$的含义。如果直接看原图,例如$k=1$时,很容易误解为$\text{TRM}_1(\cdot)$的输入是$t_2t_3t_4t_5$,那么公式$\eqref{eq:trm}$的下标为什么从1开始?首先需要理解$T$的含义,这里$T$是输入的序列长度,以原图为例,这里的输入序列长度为6,这个$T$指的是我们在训练时可以真正用作input的长度,$t_7$不计算在$T$里,因为$t_7$永远都要当做target来计算损失。在构造数据时,我们拿到的原始序列为$t_1$~$t _7$,通常为了执行next token预测,我们会将$t_1$~$t_6$作为input,将$t_2$~$t_7$作为target,这样便可以使每一个位置的token预测下1个位置的token。当需要执行多token预测时,作为input的序列就要相应的缩短,例如,如果我们需要预测下2个token,此时$k=1$,我们会将$t_1$~$t_5$作为input,将$t_3$~$t_7$作为target,这样便可以使每一个位置的token预测下2个位置的token。如果我们需要预测下3个token,此时$k=2$,我们会将$t_1$~$t_4$作为input,将$t_4$~$t_7$作为target,这样便可以使每一个位置的token预测下3个位置的token。如下图所示:
- $k=0$时的输入输出:(图一)
- $k=1$时的输入输出:(图二)
- $k=2$时的输入输出:(图三)
因此,不论$k$是几,$\text{TRM}_k(\cdot)$的输入的下标均是$1:T-k$,这实际上是主模型的输入序列,即左下角的红框,而$\text{TRM}_k(\cdot)$的输出则是右上角的红框,这也符合预测下$k+1$个token的逻辑。实际上我们可以将绿框中的部分理解为是一个辅助输入,对于这些辅助输入,$\text{TRM}_k(\cdot)$做的是next token预测,但对于主模型输入,做的则是多token预测。
再来看MTP的损失计算方式,对每个预测深度,计算交叉熵损失:
\[\begin{equation} \mathcal{L}_{\text{MTP} }^k = \text{CrossEntropy}(P_{2+k:T+1}^k, t_{2+k:T+1}) = -\frac{1}{T} \sum_{i=2+k}^{T+1} \log P_i^k[t_i] \end{equation}\]其中:
- $T$ :输入序列长度,在本文的例子中为6
- $t_i$ :第 $i$ 个位置的ground truth token
- $P_i^k[t_i]$ :由第 $k$ 个MTP模块给出的对应 $t_i$ 的预测概率
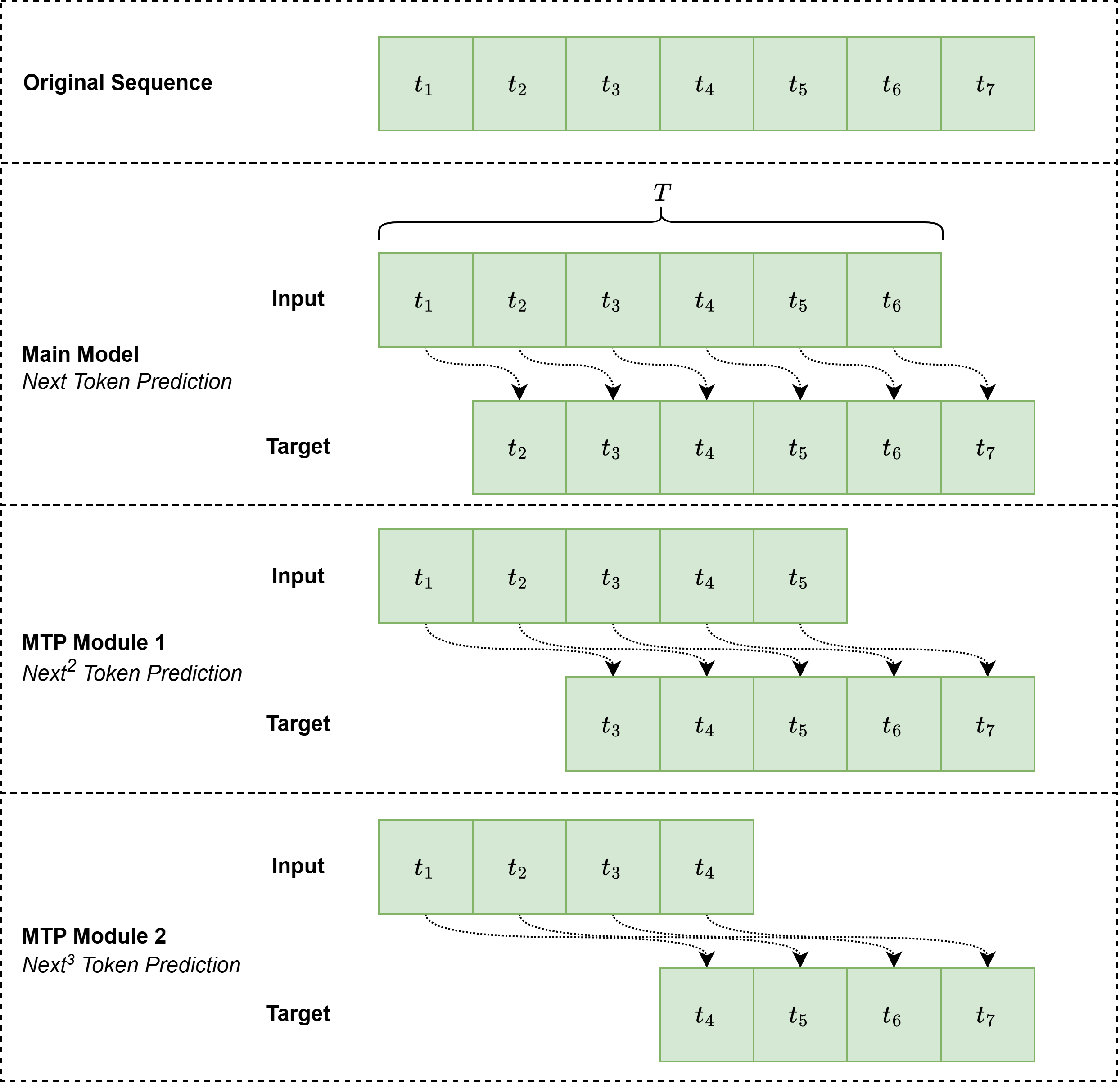
从公式角度来看,第$k$个MTP模块计算的应当是$t_{2+k}$~$t_{T+1}$的交叉熵损失,例如在原图中,$k=2$时,计算的是$t_4$~$t_7$的损失,这没问题。问题在于,原文的图直接将$\mathcal{L}_\text{MTP}^1$标记在了MTP模块1旁边,这是具有迷惑性的,如果根据图中的标识,可能很容易理解为$\mathcal{L}_\text{MTP}^1$是在为$t_3$~$t_6$做损失,如果真是这样的话,对于token $t_5$就丢失了预测下2个token的过程。实际上,根据公式,$k=1$时,应当计算的是$t_3$~$t_7$的损失,即也需要做到$T+1$的token,如图二所示。
从图一至图三来看,$t_1$~$t_6$全部作为输入,均在主模型做了next token预测,计算$t_2$~$t_7$的损失。然后截取主模型$t_1$~$t_5$的输出表征,结合$t_2$~$t_6$辅助(辅助使用的是输入序列的ground truth),在MTP 1中做了下2个token预测,计算$t_3$~$t_7$的损失。然后截取MTP 1 $t_1$~$t_4$的输出表征,结合$t_3$~$t_6$辅助,在MTP 2中做了下3个token的预测,计算$t_4$~$t_7$的损失。下图能很好的展示这一点这一过程:
在DeepSeek-V3中,设置的预测深度为1,即只额外预测1个token,这种情况下,就不存在上述歧义了。为了简化代码逻辑,本项目也将预测深度固定为1,代码如下:
class MTP(nn.Module):
"""
多token预测(Multi-Token Prediction, MTP)
Attributes:
args (ModelArgs): 模型配置参数
embed (nn.Module): 嵌入层
head (nn.Module): 输出投影
h_norm (nn.Module): 对上一个 MTP 模块或主模型输出的 hidden state 应用的 Layer Normalization
x_norm (nn.Module): 对本 MTP 模块输入应用的 Layer Normalization
output_norm (nn.Module): 对本 MTP 模块输出应用的 Layer Normalization
linear_proj (nn.Module): 线性投影层,用于将 MTP 模块的两个输入拼接后进行投影
transformer_block (nn.Module): Transformer Block
"""
def __init__(self, args: DeepSeekV3ModelArgs, embed: nn.Module, head: nn.Module):
"""
初始化 MTP
Args:
args (ModelArgs): 模型配置参数
embed (nn.Module): 嵌入层, 来自于 Transformer 共享
head (nn.Module): 输出投影, 来自于 Transformer 共享
"""
super().__init__()
self.embed = embed
self.head = head
self.h_norm = RMSNorm(args.dim)
self.x_norm = RMSNorm(args.dim)
self.output_norm = RMSNorm(args.dim)
self.linear_proj = nn.Linear(2 * args.dim, args.dim, bias=False)
self.transformer_block = Block(0, args)
def forward(self, x: torch.Tensor, h: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
MTP 的前向传播
Args:
x (torch.Tensor): 输入 token_ids (batch_size, mtp_seq_len)
h (torch.Tensor): 上一个 MTP 模块或主模型的输出 (batch_size, mtp_seq_len, dim)
start_pos (int): 用于指定当前推理步骤的起始位置,即从序列的哪个位置开始计算
freqs_cis (torch.Tensor): 预先计算的复数 RoPE 矩阵
Returns:
Tuple[torch.Tensor, torch.Tensor]: 输出 Logits (batch_size, vocab_size) 和给下一个 MTP 使用的 h (batch_size, mtp_seq_len, dim)
"""
seqlen = x.size(1)
mask = None
x = self.embed(x)
x = self.x_norm(x)
h = self.h_norm(h)
x = self.linear_proj(torch.cat([x, h], dim=-1))
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=x.device).triu_(1)
x, _, _ = self.transformer_block(x, start_pos, freqs_cis, mask)
h = x
x = self.output_norm(x)
logits = self.head(x)
return logits, h
其实现也比较简单,需要注意以下几点:
- 原文的图中,每个MTP的 Transformer Block在输出head前没有体现出norm,但主模型的源代码有,因此这里也加上
self.output_norm。 - 原文中未说明MTP使用的是否是MoE架构,这里我使用普通MLP作为前馈。
- MTP只在训练时使用,因此这里需添加mask的逻辑。
- 输入序列长度标记为
mtp_seq_len,这是因为当预测深度k=1时,MTP的输入长度比原序列长度少1。 - 最终返回MTP的logits,和用于下一个MTP模块使用的输出表征(由于我固定预测深度为1,所以实际上没有用到它)
五、整体模型实现
最终,我们将上述所有模块构造成整体模型,代码如下:
class DeepSeekV3Model(BaseModel):
"""
Transformer 整体模型
Attributes:
max_seq_len (int): 最大序列长度
embed (nn.Module): 嵌入层
layers (torch.nn.ModuleList): Transformer Blocks 列表
norm (nn.Module): 在最后一个 Transformer Block 后应用 Layer Normalization
head (nn.Module): 输出投影
freqs_cis (torch.Tensor): 预先计算的复数 RoPE 矩阵
use_mtp (bool): 是否使用 MTP
mtp_loss_lambda (float): MTP 损失的权重
MTP (torch.nn.ModuleList): MTP 模块
"""
model_name = "mini_deepseekv3"
def __init__(self, args: DeepSeekV3ModelArgs):
"""
初始化 Transformer
Args:
args (ModelArgs): 模型配置参数
"""
super().__init__()
self.max_seq_len = args.max_seq_len
self.embed = nn.Embedding(args.vocab_size, args.dim)
self.layers = torch.nn.ModuleList()
for layer_id in range(args.n_layers):
self.layers.append(Block(layer_id, args))
self.norm = RMSNorm(args.dim)
self.head = nn.Linear(args.dim, args.vocab_size, bias=False)
self.register_buffer("freqs_cis", precompute_freqs_cis(args), persistent=False)
self.use_mtp = args.use_mtp
self.mtp_loss_lambda = args.mtp_loss_lambda
self.mtp =MTP(args, self.embed, self.head)
def forward(self, input_ids: torch.Tensor, targets: torch.Tensor = None, start_pos: int = 0) -> Tuple[torch.Tensor, torch.Tensor]:
"""
前向传播
Args:
input_ids (torch.Tensor): 输入张量, 内容为 token_ids (batch_size, seq_len)
targets (torch.Tensor): 目标张量, 内容为 token_ids (batch_size, seq_len)
start_pos (int): 起始位置, 默认为 0
Returns:
torch.Tensor: 输出 Logits (batch_size, vocab_size), Loss
"""
# ----------------------- 变量初始化 -----------------------
seqlen = input_ids.size(1)
h = self.embed(input_ids)
freqs_cis = self.freqs_cis[start_pos:start_pos+seqlen]
mask = None
main_loss = 0.0
total_seq_aux_loss = 0.0
mtp_loss = 0.0
all_global_counts = []
# ----------------------- 主模型部分 -----------------------
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=input_ids.device).triu_(1)
for layer in self.layers:
h, seq_aux_loss, global_counts = layer(h, start_pos, freqs_cis, mask)
if seq_aux_loss is not None:
total_seq_aux_loss += seq_aux_loss
if global_counts is not None:
all_global_counts.append(global_counts)
h_for_mtp = h
h = self.norm(h)
logits = self.head(h)
if self.training:
main_loss = F.cross_entropy(logits.reshape(-1, logits.size(-1)), targets.reshape(-1), reduction="mean")
# ----------------------- MTP 部分 -----------------------
if self.use_mtp and self.training:
mtp_logits, _ = self.mtp(input_ids[:, 1:], h_for_mtp[:, :-1], 0, self.freqs_cis[0:seqlen-1])
targets_for_mtp = targets[:, 1:]
mtp_loss = F.cross_entropy(mtp_logits.reshape(-1, mtp_logits.size(-1)), targets_for_mtp.reshape(-1), reduction="mean")
# ----------------------- 计算总损失 -----------------------
loss = main_loss + total_seq_aux_loss + self.mtp_loss_lambda * mtp_loss
return logits, loss, (main_loss, total_seq_aux_loss, self.mtp_loss_lambda * mtp_loss, all_global_counts)
主模型大致也可分为四个部分,这里主要说明一下主模型部分、MTP部分和总损失部分:
1. 主模型部分
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=input_ids.device).triu_(1)
seqlen为1通常是使用KV Cache推理时,此时无需mask,若大于1,则需要使用因果mask。
for layer in self.layers:
h, seq_aux_loss, global_counts = layer(h, start_pos, freqs_cis, mask)
if seq_aux_loss is not None:
total_seq_aux_loss += seq_aux_loss
if global_counts is not None:
all_global_counts.append(global_counts)
前向传播每个Transformer Block,收集各层的序列级辅助损失和专家负载情况。
h_for_mtp = h
h = self.norm(h)
logits = self.head(h)
if self.training:
main_loss = F.cross_entropy(logits.reshape(-1, logits.size(-1)), targets.reshape(-1), reduction="mean")
一方面将主模型输出表征赋值给h_for_mtp,用于输入到MTP模块,另一方面继续进入到RMSNorm和输出头,计算主模型损失。
2. MTP部分
if self.use_mtp and self.training:
mtp_logits, _ = self.mtp(input_ids[:, 1:], h_for_mtp[:, :-1], 0, self.freqs_cis[0:seqlen-1])
targets_for_mtp = targets[:, 1:]
mtp_loss = F.cross_entropy(mtp_logits.reshape(-1, mtp_logits.size(-1)), targets_for_mtp.reshape(-1), reduction="mean")
由于预测深度固定为1,这里截取input_ids为input_ids[:, 1:],充当MTP的辅助输入,截取的h_for_mtp[:, :-1],代表MTP上一个模块的输出表征。target则截取为targets[:, 1:]。最后计算出MTP的损失,该部分只在训练时执行。
3. 总损失部分
loss = main_loss + total_seq_aux_loss + self.mtp_loss_lambda * mtp_loss
return logits, loss, (main_loss, total_seq_aux_loss, self.mtp_loss_lambda * mtp_loss, all_global_counts)
最终,总损失由主模型损失、所有层的序列级辅助损失和MTP损失构成。前向传播返回模型输出的logits、loss和其他需要外部代码收集以进行可视化的数据。这里我将三种损失和专家负载情况传出,用于后续监控训练过程和可视化。
六、训练及结果
项目具体的训练代码等在此不做介绍了,可在https://github.com/WKQ9411/Mini-LLM查看所有代码。这里主要介绍训练的流程和结果。
首先,模型配置参数如下:
max_batch_size: int = 16
max_seq_len: int = 512
vocab_size: int = -1 # 加载模型时传入
dim: int = 768
inter_dim: int = 3072
moe_inter_dim: int = 512
n_layers: int = 12
n_dense_layers: int = 3
n_heads: int = 12
# moe
n_routed_experts: int = 8
n_shared_experts: int = 1
n_activated_experts: int = 2
n_expert_groups: int = 4
n_limited_groups: int = 2
route_scale: float = 1.
use_noaux_tc: bool = True
bias_update_speed: float = 0.001
use_seq_aux: bool = True
seq_aux_alpha: float = 0.0001
# mla
q_lora_rank: int = 384 # 源码中若 q_lora_rank=0, 则不使用下投影,这里我们使用下投影,并略去若 q_lora_rank=0 的逻辑
kv_lora_rank: int = 256 # 论文中 d_c = 4 * d_h
qk_nope_head_dim: int = 64 # d_h
qk_rope_head_dim: int = 32 # 论文中 d_h^R = d_h / 2
v_head_dim: int = 64
# RoPE
rope_theta: float = 10000.0
# MTP
use_mtp: bool = True
mtp_loss_lambda: float = 0.0001
其他详细介绍参考项目README.md。
结果演示如下:
当前Mini-LLM项目代码已经过重构,可能与本文介绍的代码存在细微差异,但原理一致。