【手撕系列】手撕Qwen3-Next
Categories: Code
目录
概览
Qwen3-Next 是阿里发布的下一代大模型基础架构,通过混合注意力架构、极致稀疏MoE、 训练稳定性友好设计、Multi-Token Prediction等机制,实现了长上下文能力和计算效率的突破。
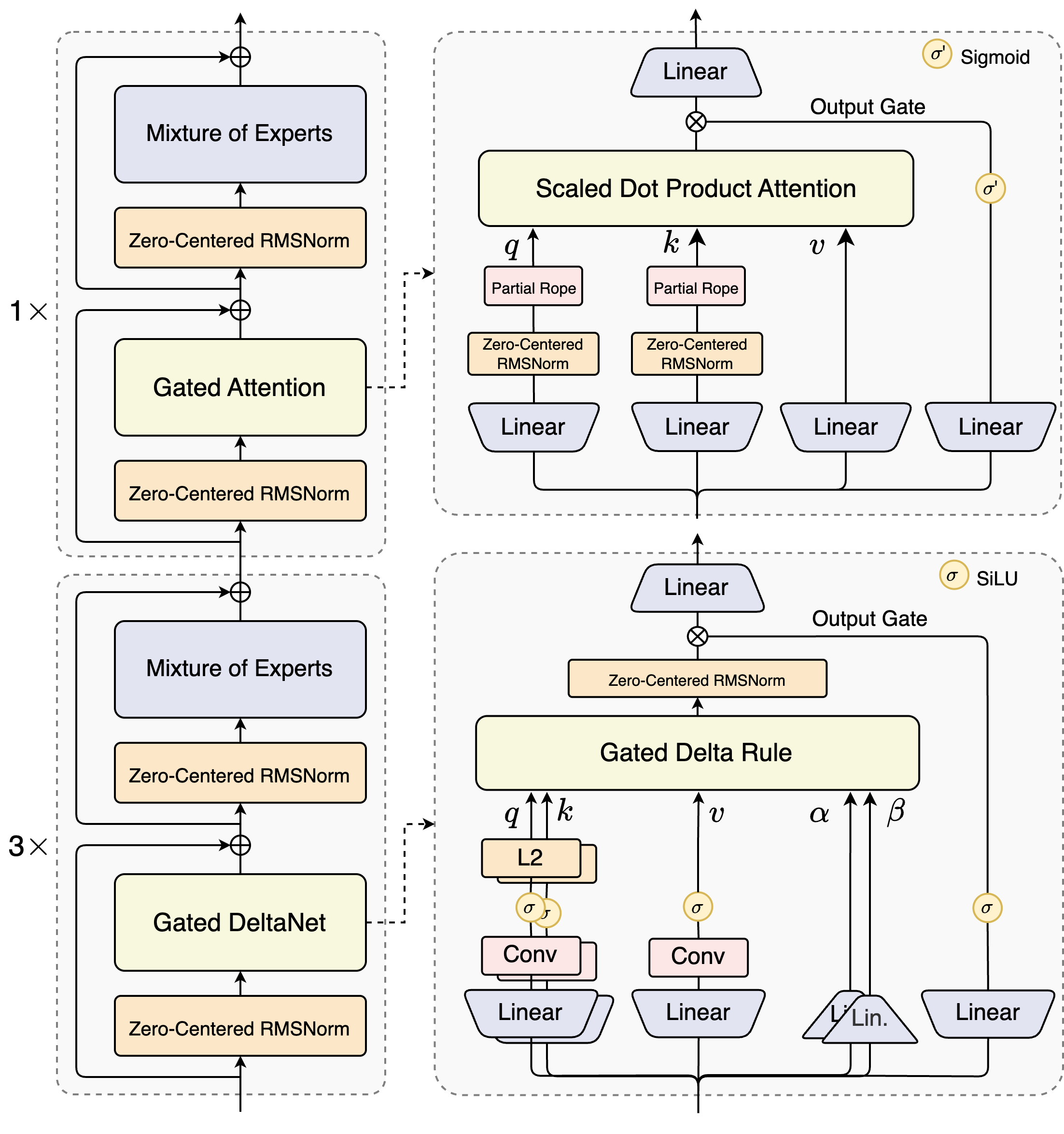
本文将按照官方博客所列举的要点来介绍:
- 混合架构 Gated DeltaNet + Gated Attention
- 极致稀疏 MoE
- 训练稳定性友好设计
- Multi-Token Prediction
其中,相比通常完全使用标准注意力的模型,Qwen3-Next 的主要改进在于引入了 Gated DeltaNet 和标准注意力的混合注意力架构,这将是本手撕代码要实现的核心模块,也是本文重点介绍的内容。官方博客见:Qwen3-Next。阅读本文前,请确保已经基本了解线性注意力的相关理论,具体可以参考:
完整的手撕代码请参考:Mini-LLM,如果对您有所帮助,欢迎 Star🌟
关于本手撕代码的几点说明:
- 本手撕代码简化了 transformers 源码,没有使用 fla、causal_conv1d 等库来加速,而是采用了原生 pytorch 实现来加强理解。
- 源代码仅对注意力头前 25% 的位置维度添加旋转位置编码,本仓库仍对全部维度添加。
- 本仓库修改了源代码中的负载均衡损失函数的实现,具体见本文 MoE 部分。
- 本仓库在进行 sft 数据训练时,使用的数据是未经 packing 的,因为如果使用 packing 数据,那么在一个 batch 中会存在不同样本,为了避免跨样本注意,需要将样本间隔处的状态矩阵置零。但在 chunkwise 递推时,只会用到 chunk 的初始状态矩阵并计算出 chunk 的末尾状态矩阵。如果样本间隔位于 chunk 中间,将其状态矩阵置零会比较复杂,因此本项目就简单使用未 packing 的数据来进行 sft。
- mini_qwen3_next 偷个懒,暂未实现 MTP,可以参考 mini_deepseekv3 中 MTP 的实现 【手撕系列】手撕DeepSeek-V3。
一、混合架构
(一)Gated DeltaNet
Gated DeltaNet 通过 GatedDeltaNet 类实现,其结构如下图所示:
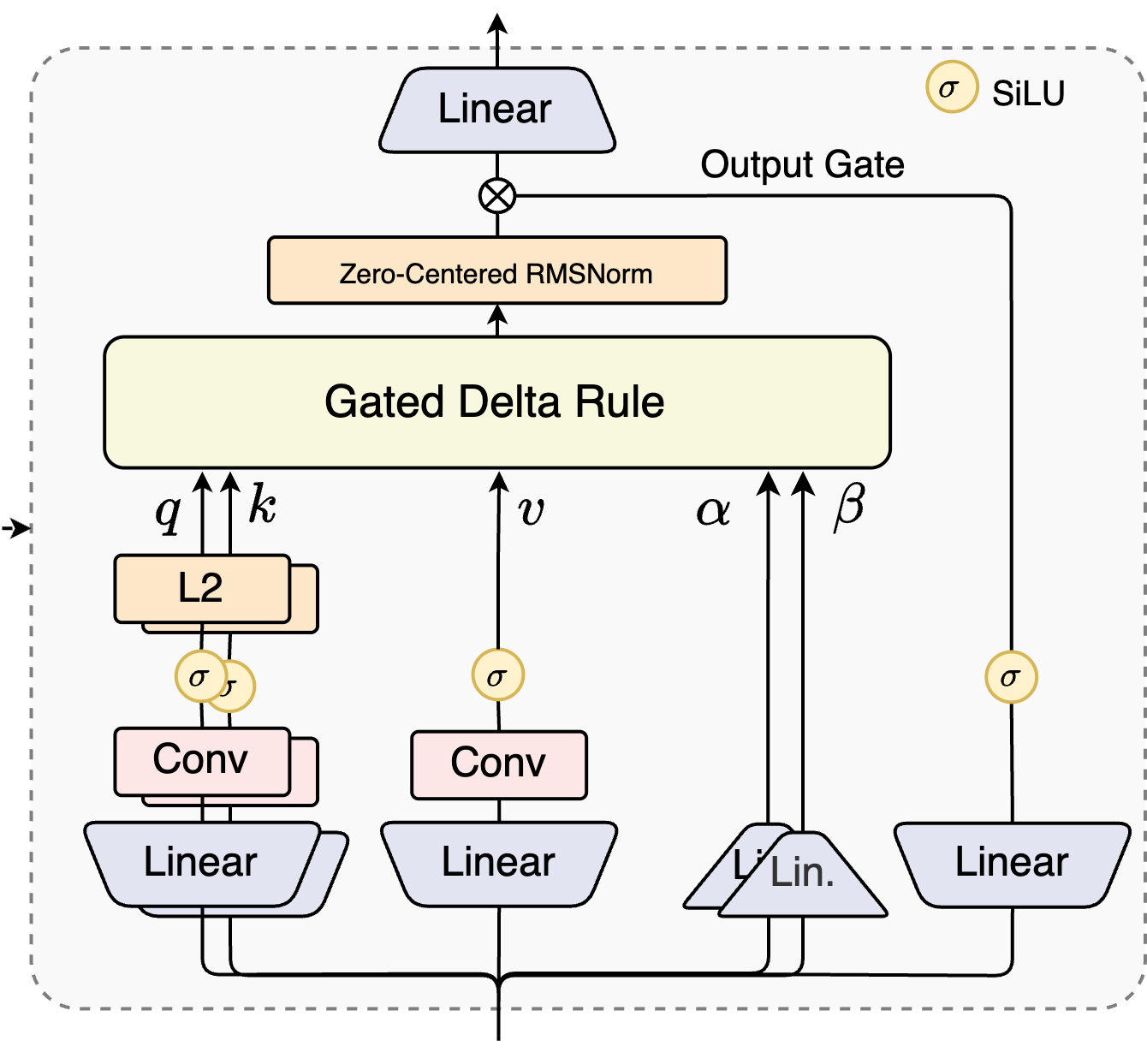
1. 初始化
首先 GatedDeltaNet 初始化如下:
class GatedDeltaNet(nn.Module):
def __init__(
self,
layer_idx: int,
hidden_size: int,
num_k_heads: int,
num_v_heads: int,
head_k_dim: int,
head_v_dim: int,
conv_kernel_size: int,
layer_norm_epsilon: float,
):
super().__init__()
self.layer_idx = layer_idx
self.hidden_size = hidden_size
self.num_k_heads = num_k_heads # q,k 头数
self.num_v_heads = num_v_heads # v,z 头数
self.head_k_dim = head_k_dim
self.head_v_dim = head_v_dim # 要求 num_v_heads % num_k_heads == 0
self.key_dim = self.num_k_heads * self.head_k_dim
self.value_dim = self.num_v_heads * self.head_v_dim
self.conv_kernel_size = conv_kernel_size
self.layer_norm_epsilon = layer_norm_epsilon
# 卷积
self.conv_dim = self.key_dim * 2 + self.value_dim
self.conv1d = nn.Conv1d(
in_channels=self.conv_dim, # 输入通道数
out_channels=self.conv_dim, # 输出通道数
bias=False,
kernel_size=self.conv_kernel_size, # 卷积核大小 k
groups=self.conv_dim, # 每个通道进行独立的卷积操作,因此不存在跨通道信息交换
padding=self.conv_kernel_size - 1, # 在序列两侧各 padding k-1 个 0
)
# 输入投影
projection_size_qkvz = self.key_dim * 2 + self.value_dim * 2
projection_size_ba = self.num_v_heads * 2
self.in_proj_qkvz = nn.Linear(self.hidden_size, projection_size_qkvz, bias=False)
self.in_proj_ba = nn.Linear(self.hidden_size, projection_size_ba, bias=False)
# 定义衰减相关参数
self.dt_bias = nn.Parameter(torch.ones(self.num_v_heads)) # 时间偏置
A = torch.empty(self.num_v_heads).uniform_(0, 16) # 衰减基数
self.A_log = nn.Parameter(torch.log(A))
# 输出投影前的 RMSNorm + Gate
self.norm = RMSNormGated(self.head_v_dim, eps=self.layer_norm_epsilon)
self.out_proj = nn.Linear(self.value_dim, self.hidden_size, bias=False)
# 定义函数
self.causal_conv1d_update = torch_causal_conv1d_update
self.chunk_gated_delta_rule = torch_chunk_gated_delta_rule
self.recurrent_gated_delta_rule = torch_recurrent_gated_delta_rule
对其中的部分参数做简要说明:
hidden_states将主要转换为q、k、v、b、a、z几个分支,其中qkv就是 query、key、value,ba用于产生 $\alpha$ 和 $\beta$,z则用于门控。num_k_heads表示q、k的头数,num_v_heads表示b、a、z的头数,且要求num_v_heads % num_k_heads == 0。- 对
qkv应用了卷积操作,这里是一个通道分离卷积,因此不存在跨通道信息交换。假设卷积核大小为 k,序列长度为 L,在进行卷积操作时,会对序列的两边各 padding k-1 个 0,这样输入长度会变为 L+2*(k-1),卷积核步长为 1,输出长度将变为 L+k-1,最后会把输出序列长度截取为 L。 dt_bias和A_log是用于计算 $\alpha$ 的参数,后面会进一步细讲。- 这里的
RMSNormGated类综合了输出投影前的 RMSNorm 和 Gate 操作。虽然这部分的 RMSNorm 在官方图中标注的是 Zero-Centered RMSNorm,但在 transformers 的源码实现中,RMSNormGated类里仍然是常用的初始参数化为 1 的 RMSNorm,不过这里问题不大。
在大致了解初始化涉及的参数后,我们来分块一步一步看其 forward 部分。
2. 输入投影部分
首先给出此部分的代码:
def forward(
self,
hidden_states: torch.Tensor,
cache_params: Optional[MiniQwen3NextDynamicCache] = None,
cache_position: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
):
hidden_states = apply_mask_to_padding_states(hidden_states, attention_mask)
batch_size, seq_len, _ = hidden_states.shape
# ------------------------- 1. 输入投影 -------------------------
projected_states_qkvz = self.in_proj_qkvz(hidden_states) # (batch_size, seq_len, key_dim*2 + value_dim*2)
projected_states_ba = self.in_proj_ba(hidden_states) # (batch_size, seq_len, num_v_heads*2)
query, key, value, z, b, a = self.fix_query_key_value_ordering(projected_states_qkvz, projected_states_ba)
query, key, value = (x.reshape(x.shape[0], x.shape[1], -1) for x in (query, key, value)) # (batch_size, seq_len, key_dim/value_dim)
mixed_qkv = torch.cat((query, key, value), dim=-1) # (batch_size, seq_len, key_dim + key_dim + value_dim)
mixed_qkv = mixed_qkv.transpose(1, 2) # (batch_size, key_dim + key_dim + value_dim, seq_len)
这里在前向时传入的 cache_params 实际上相当于 past_key_values,用于缓存状态矩阵等。cache_position 代表当前输入序列的位置序号,它的位置范围是 [past_seen_tokens, past_seen_tokens + seq_len]。
在传入 hidden_states 后,首先通过 apply_mask_to_padding_states 把其中的 padding 部分的 token 置零,其函数实现如下:
def apply_mask_to_padding_states(hidden_states: torch.Tensor, attention_mask: torch.Tensor | None) -> torch.Tensor:
# 仅在 attention_mask 存在且 batch_size 和 seq_len 均大于 1 时才计算
if attention_mask is not None and attention_mask.shape[1] > 1 and attention_mask.shape[0] > 1:
dtype = hidden_states.dtype
hidden_states = (hidden_states * attention_mask[:, :, None]).to(dtype)
return hidden_states
而后经过联合投影得到 projected_states_qkvz 和 projected_states_ba,然后使用 fix_query_key_value_ordering 来获得正确形状的 q、k、v、b、a、z。在 transformers 的 Qwen-Next 源码中,该函数的逻辑是首先将 projected_states_qkvz 和 projected_states_ba 按照 num_k_heads view 成 4D,然后再进行 split 和 reshape。这里没有直接把 3D 的最后一维按 [key_dim, key_dim, value_dim, value_dim] 或 [num_v_heads, num_v_heads] split,然后再 reshape。个人猜测是因为:在实现 transformers 版本代码时,为了兼容他们内部训练好的模型权重,于是添加此函数用于按训练实现约定的布局去解码。由于我们是重新开始训练模型,理论上这里也可以直接拆分维度,再各自 reshape 成想要的形状即可,但为了尽可能与 transformers 版本保持一致,这里不做修改。总之,经过输入投影,最终得到的形状为:
# query: (batch_size, seq_len, key_dim)
# key: (batch_size, seq_len, key_dim)
# value: (batch_size, seq_len, value_dim)
# z: (batch_size, seq_len, num_v_heads, head_v_dim)
# b: (batch_size, seq_len, num_v_heads)
# a: (batch_size, seq_len, num_v_heads)
此外,还在最后一维拼接了 qkv 并进行转置,为下一步的卷积做好准备:
mixed_qkv = torch.cat((query, key, value), dim=-1) # (batch_size, seq_len, key_dim + key_dim + value_dim)
mixed_qkv = mixed_qkv.transpose(1, 2) # (batch_size, key_dim + key_dim + value_dim, seq_len)
3. qkv 卷积部分
卷积部分代码如下:
# 用于判断当前是 prefill 阶段还是 decode 阶段
use_precomputed_states = (
cache_params is not None # 缓存参数不为空
and cache_params.has_previous_state # 存在之前的缓存状态
and seq_len == 1 # 输入序列长度为 1
and cache_position is not None # 缓存位置不为空
)
# 获取卷积状态和循环状态
if cache_params is not None:
conv_state = cache_params.conv_states[self.layer_idx] # (batch_size, key_dim + key_dim + value_dim, conv_kernel_size)
recurrent_state = cache_params.recurrent_states[self.layer_idx] # (batch_size, key_dim + key_dim + value_dim, conv_kernel_size)
if use_precomputed_states:
# decode 阶段
# 利用之前的 conv_state 计算新卷积输出,并更新 conv_state
mixed_qkv = self.causal_conv1d_update(
mixed_qkv, # (batch_size, key_dim + key_dim + value_dim, seq_len)
conv_state, # (batch_size, key_dim + key_dim + value_dim, conv_kernel_size)
self.conv1d.weight.squeeze(1), # (key_dim + key_dim + value_dim, conv_kernel_size)
self.conv1d.bias, # (key_dim + key_dim + value_dim,)
)
else:
# prefill 阶段
if cache_params is not None:
# (batch_size, key_dim + key_dim + value_dim, conv_kernel_size)
conv_state = F.pad(mixed_qkv, (self.conv_kernel_size - mixed_qkv.shape[-1], 0))
cache_params.conv_states[self.layer_idx] = conv_state
# 每个通道进行独立的卷积,因此 qkv 可以拼接后一起执行,卷积输出后,将多余的 k-1 部分截断
mixed_qkv = F.silu(self.conv1d(mixed_qkv)[:, :, :seq_len])
这里会分为 prefill 和 decode 两个阶段,通过 use_precomputed_states 来判定。前面我们介绍过,前向时传入的 cache_params 实际上相当于常见的 past_key_values,用于缓存各类参数,它的实现我们后续再介绍。如果 cache_params 不为 None,则读取其中的 conv_state 和 recurrent_state,前者是缓存的用于参与当前 token 卷积计算的隐状态,后者则用于进行后续的 Gated Delta Rule 计算。
我们先来看后半段代码,该部分属于 prefill 阶段。在 prefill 时,通常会传入在外部初始化过的 cache_params 实例,因此它不为 None,但是其中所保存的各层的参数还是 None,因此需要初始化卷积缓存状态:
# (batch_size, key_dim + key_dim + value_dim, conv_kernel_size)
conv_state = F.pad(mixed_qkv, (self.conv_kernel_size - mixed_qkv.shape[-1], 0))
cache_params.conv_states[self.layer_idx] = conv_state # 注意这里 conv_state 保存的是卷积前的状态
以上代码表示在最后一个维度,也就是序列长度维度的左侧,填充 conv_kernel_size - seq_len 个 0。当 seq_len >= conv_kernel_size 时,conv_kernel_size - seq_len 为负数或 0,此时会截断张量,只保留最后 conv_kernel_size 个时间步。当 seq_len < conv_kernel_size 时,左侧填充 0,使总长度达到 conv_kernel_size。可见,这里缓存的 conv_state 实际上是卷积前的 mixed_qkv,长度为 conv_kernel_size。而后,进行的是常见的卷积操作和 silu 激活。
再来看前半段,也就是 decode 部分。decode 是自回归计算部分,它的主要逻辑是利用之前缓存的 conv_state 进行卷积计算,并更新新的 conv_state,核心逻辑通过函数 causal_conv1d_update 实现:
def torch_causal_conv1d_update(
hidden_states: torch.Tensor,
conv_state: torch.Tensor,
weight: torch.Tensor,
bias: torch.Tensor | None = None,
) -> torch.Tensor:
"""
使用 conv1d 实现因果卷积的状态更新
Args:
hidden_states (torch.Tensor): 输入张量 (batch_size, key_dim + key_dim + value_dim, seq_len)
conv_state (torch.Tensor): 卷积状态张量 (batch_size, key_dim + key_dim + value_dim, conv_kernel_size)
weight (torch.Tensor): 卷积权重张量 (key_dim + key_dim + value_dim, conv_kernel_size)
bias (torch.Tensor | None): 卷积偏置张量 (key_dim + key_dim + value_dim,)
Returns:
torch.Tensor: 卷积输出张量 (batch_size, key_dim + key_dim + value_dim, seq_len)
"""
_, hidden_size, seq_len = hidden_states.shape
state_len = conv_state.shape[-1]
# (batch_size, key_dim + key_dim + value_dim, seq_len + conv_kernel_size)
hidden_states_new = torch.cat([conv_state, hidden_states], dim=-1).to(weight.dtype)
conv_state.copy_(hidden_states_new[:, :, -state_len:]) # 更新 conv_state
# 计算卷积输出
out = F.conv1d(hidden_states_new, weight.unsqueeze(1), bias, padding=0, groups=hidden_size)
out = F.silu(out[:, :, -seq_len:])
out = out.to(hidden_states.dtype)
return out
它的逻辑也比较简单,首先将当前 token 的 mix_qkv 与之前缓存的最后几个 token 的 conv_state 拼接起来,然后截取后 conv_kernel_size 个 token 进行卷积和激活计算,同时将后 conv_kernel_size 的 token 更新为新的 conv_state。
4. 形状调整
接下来是一系列的张量形状调整和变量准备:
mixed_qkv = mixed_qkv.transpose(1, 2)
query, key, value = torch.split(mixed_qkv, [self.key_dim, self.key_dim, self.value_dim], dim=-1)
query = query.reshape(query.shape[0], query.shape[1], -1, self.head_k_dim) # (batch_size, seq_len, num_k_heads, head_k_dim)
key = key.reshape(key.shape[0], key.shape[1], -1, self.head_k_dim) # (batch_size, seq_len, num_k_heads, head_k_dim)
value = value.reshape(value.shape[0], value.shape[1], -1, self.head_v_dim) # (batch_size, seq_len, num_v_heads, head_v_dim)
# 调整 ba
beta = b.sigmoid() # 转化为 0-1 之间的 β (batch_size, seq_len, num_v_heads)
g = -self.A_log.float().exp() * F.softplus(a.float() + self.dt_bias) # (batch_size, seq_len, num_v_heads)
# 调整 qk 头数,类似于 softmax 注意力中的 repeat_kv
if self.num_v_heads // self.num_k_heads > 1:
query = query.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)
key = key.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)
首先将上一步卷积得到的 mixed_qkv 拆分,并按注意力头进行 reshape,得到 query、key、value。
而后调整 ba,前面我们已经得到 ba 的形状均为 (batch_size, seq_len, num_v_heads),即每个 token 的每个注意力头,都会对应一个标量值。它们均由输入的 hidden_states 映射而来,因此它们是输入相关的。
对于 b,直接有 beta = b.sigmoid(),转化为 0-1 之间的 $\beta$。对于 a,其参数化方法为 $\alpha = \exp (A \cdot \Delta t)$,需保证 $A < 0$ 和 $\Delta t > 0$,从而使 $\alpha \in (0,1)$。其中,$A$ 代表每个 head 的基础衰减时间尺度,$\Delta t = \text{softplus}(a + \text{bias})$ 代表时间步长,它通过对 a 和 dt_bias 之和使用 softplus 激活得到。dt_bias 是参数权重,训练后得到的是静态偏置。$\text{softplus}(x) = \log (1+ \exp (x))$,它的导数就是 sigmoid 函数,因而能够使得梯度在一个有界范围内,防止梯度爆炸。此外,它的作用是将 $\Delta t$ 控制为正,其曲线如下图所示:
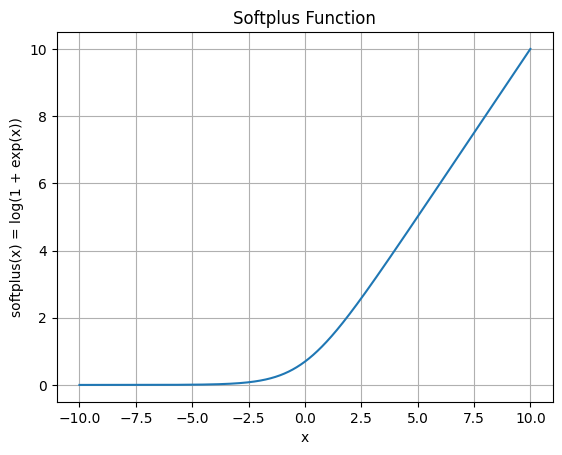
在初始化时,我们将 dt_bias 初始化为 1,将 A 初始化为 [0, 16) 中的均匀采样(直接精确采样到 0 的概率极低)。如果直接把 A 作为可学习参数,梯度有可能把它推成负数。为了使 A 保持正数,我们初始化时将 A_log,也就是 log(A) 设置为可学习参数,因此现在我们通过计算 -self.A_log.float().exp(),首先恢复为正数 A,然后加负号使其恒负(这里的 -A 就是上述公式中的 $A < 0$)。最终我们计算得到 g:
g = -self.A_log.float().exp() * F.softplus(a.float() + self.dt_bias)
随后,g 会通过 exp(g) 使其转化为 $\alpha \in (0, 1)$,综合来看,$\alpha$ 由 A、a、dt_bias 共同决定。
最后,调整 qk 头数,这部分类似于标准 softmax 注意力中常见的 repeat_kv。
5. 应用 Gated Delta Rule 🌟
接下来这部分是 Gated DeltaNet 的核心部分,涉及到逐步递推和 chunkwise 递推两部分,相关公式推导请参考:【论文解读】Gated Delta Network。此外,代码的实现中还涉及到一些等效、高效求逆等操作,接下来逐步讲解。
首先贴出代码:
# prefill 阶段,分 chunk 并行
if not use_precomputed_states:
core_attn_out, last_recurrent_state = self.chunk_gated_delta_rule(
query,
key,
value,
g=g,
beta=beta,
initial_state=None,
output_final_state=cache_params is not None,
use_qk_l2norm_in_kernel=True,
)
# decode 阶段,自回归
else:
core_attn_out, last_recurrent_state = self.recurrent_gated_delta_rule(
query,
key,
value,
g=g,
beta=beta,
initial_state=recurrent_state,
output_final_state=cache_params is not None,
use_qk_l2norm_in_kernel=True,
)
# core_attn_out: (batch_size, seq_len, num_heads, head_v_dim)
# last_recurrent_state: (batch_size, num_heads, head_k_dim, head_v_dim)
# 更新 cache
if cache_params is not None:
cache_params.recurrent_states[self.layer_idx] = last_recurrent_state
这部分代码主要负责区分 prefill 和 decode 两个阶段,具体逻辑分别由 self.chunk_gated_delta_rule (chunkwise)和 self.recurrent_gated_delta_rule 实现(逐步递推)。递推之后,将最后一个状态矩阵 last_recurrent_state 更新到 cache_params 中。
(1) chunkwise 递推
a. 准备工作
首先我们看 self.chunk_gated_delta_rule 部分,它通过函数 torch_chunk_gated_delta_rule 实现,用于 prefill 或高效并行训练:
def torch_chunk_gated_delta_rule(
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
g: torch.Tensor,
beta: torch.Tensor,
chunk_size: int = 64,
initial_state: Optional[torch.Tensor] = None,
output_final_state: bool = False,
use_qk_l2norm_in_kernel: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""
分块 Gated Delta Rule, 用于训练和 prefill 阶段的并行计算, 此时的 num_k_heads 已经经过 repeat 与 num_v_heads 相同, 本函数内均使用 num_heads 表示
Args:
query (torch.Tensor): 查询张量 (batch_size, seq_len, num_heads, head_k_dim)
key (torch.Tensor): 键张量 (batch_size, seq_len, num_heads, head_k_dim)
value (torch.Tensor): 值张量 (batch_size, seq_len, num_heads, head_v_dim)
g (torch.Tensor): 遗忘门 log 值 (batch_size, seq_len, num_heads), exp(g) 为实际衰减系数
beta (torch.Tensor): 写入门 (batch_size, seq_len, num_heads), 控制写入强度
chunk_size (int): 分块大小, 默认 64
initial_state (Optional[torch.Tensor]): 初始循环状态 (batch_size, num_heads, head_k_dim, head_v_dim)
output_final_state (bool): 是否输出最终状态, 用于缓存
use_qk_l2norm_in_kernel (bool): 是否对 query/key 做 L2 归一化
Returns:
Tuple[torch.Tensor, Optional[torch.Tensor]]:
- 注意力输出 (batch_size, seq_len, num_heads, head_v_dim)
- 最终循环状态 (batch_size, num_heads, head_k_dim, head_v_dim), 若 output_final_state=False 则为 None
"""
...
在看代码之前,给出我们推导得到的所有 chunkwise 递推公式,便于与代码进行比对:
\[\begin{align} \mathbf{S}_{[t+1]} &= \overrightarrow{\mathbf{S}_{[t]} } + \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right)^\top \overrightarrow{\mathbf{K}_{[t]} } &\in \mathbb{R}^{d_v \times d_k} \\ \mathbf{O}_{[t]} &= \overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}_{[t]}^\top + \left( \mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top \odot \mathbf{\Gamma} \right) \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right) &\in \mathbb{R}^{C \times d_v} \\ \widetilde{\mathbf{U}_{[t]} } &= \left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{V}_{[t]} &\in \mathbb{R}^{C \times d_v} \\ \mathbf{\Gamma}_{[t]} &= \begin{cases} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} }, & i \leq r \\ 0, & i > r \end{cases} &\in \mathbb{R}^{C \times C} \\ \overleftarrow{\mathbf{W}_{[t]} } &= \text{diag}(\gamma^i_{[t]}) \mathbf{W}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \mathbf{W}_{[t]} &= \left[ \mathbf{I} + \text{strictLower} \left( \text{diag}(\beta_{[t]}) (\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{K}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \overrightarrow{\mathbf{S}_{[t]} } &= \gamma_{[t]}^C \mathbf{S}_{[t]} &\in \mathbb{R}^{d_v \times d_k} \\ \overrightarrow{\mathbf{K}_{[t]} } &= \text{diag}(\frac{\gamma^C_{[t]} }{\gamma^i_{[t]} }) \mathbf{K}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \overleftarrow{\mathbf{Q}_{[t]} } &= \text{diag}(\gamma^i_{[t]}) \mathbf{Q}_{[t]} &\in \mathbb{R}^{C \times d_k} \end{align}\]首先是一些变量准备,这部分比较简单,查看代码注释即可:
initial_dtype = query.dtype
# 使用 L2 Norm
if use_qk_l2norm_in_kernel:
query = l2norm(query, dim=-1, eps=1e-6)
key = l2norm(key, dim=-1, eps=1e-6)
# 将 seq_len 维度与 num_heads 维度互换,并转换为 fp32
query, key, value, beta, g = [x.transpose(1, 2).contiguous().to(torch.float32) for x in (query, key, value, beta, g)]
# 变量准备,此时的 num_k_heads 已经经过 repeat 与 num_v_heads 相同,均使用 num_heads 表示
batch_size, num_heads, sequence_length, k_head_dim = key.shape
v_head_dim = value.shape[-1]
pad_size = (chunk_size - sequence_length % chunk_size) % chunk_size # 计算最后一个 chunk 需要 pad 的数量
# F.pad 的 padding 参数是从最后一维开始,成对指定的
# (0, 0, 0, pad_size) 是指:最后一维 左边 pad 0,最后一维 右边 pad 0,倒数第2维 左边 pad 0,倒数第2维 右边 pad pad_size
# 最终会在 seq_len 维度上 pad 0 到 chunk_size 的整数倍
query = F.pad(query, (0, 0, 0, pad_size))
key = F.pad(key, (0, 0, 0, pad_size))
value = F.pad(value, (0, 0, 0, pad_size))
beta = F.pad(beta, (0, pad_size))
g = F.pad(g, (0, pad_size))
total_sequence_length = sequence_length + pad_size # pad 后的总长度
scale = 1 / (query.shape[-1] ** 0.5) # 缩放因子
query = query * scale
其中需说明的是,虽然不是 softmax 注意力,这里也对 query 进行了缩放,根本原因是高维向量内积会导致放大,因此缩放通常是必要的,它不仅局限于我们常见的 softmax 注意力。
例如,设两个高维向量 $x, y \in \mathbb{R}^d$,内积: \(\begin{equation} s = x^\top y = \sum_{i=1}^d x_i y_i \end{equation}\) 假设两个向量的每个元素期望为 0,方差为 1,且 $x_i$ 与 $y_i$ 之间相互独立,则有 $s$ 的期望为: \(\begin{equation} \mathbb{E}[s] = \mathbb{E}\left[ \sum_{i=1}^d x_i y_i \right] = \sum_{i=1}^d \mathbb{E}[x_i y_i] \end{equation}\) 由于独立,有: \(\begin{equation} \mathbb{E}[x_i y_i] = \mathbb{E}[x_i] \mathbb{E}[y_i] = 0 \end{equation}\) 因此: \(\begin{equation} \mathbb{E}[s] = 0 \end{equation}\) 对于方差,有: \(\begin{equation} \mathrm{Var}(s) = \mathbb{E}[s^2] - \mathbb{E}[s] = \mathbb{E}[s^2] \end{equation}\) 展开平方: \(\begin{equation} s^2 = \left( \sum_{i=1}^d x_i y_i \right)^2 = \sum_{i=1}^d (x_i y_i)^2 + 2 \sum_{i < j} x_i y_i x_j y_j \end{equation}\) 取期望: \(\begin{equation} \mathbb{E}[s^2] = \sum_{i=1}^d \mathbb{E}[x_i^2 y_i^2] + 2 \sum_{i < j} \mathbb{E}[x_i y_i x_j y_j] \end{equation}\) 先看第二项(交叉项),在不同维独立、且期望为 0 的假设下: \(\begin{equation} \mathbb{E}[x_i y_i x_j y_j] = \mathbb{E}[x_i] \mathbb{E}[y_i] \mathbb{E}[x_j] \mathbb{E}[y_j] = 0 \quad (i \neq j) \end{equation}\) 所以交叉项全部为 0,剩下: \(\begin{equation} \mathbb{E}[s^2] = \sum_{i=1}^d \mathbb{E}[x_i^2 y_i^2] \end{equation}\) 若 $x_i$ 与 $y_i$ 独立,则: \(\begin{equation} \mathbb{E}[x_i^2 y_i^2] = \mathbb{E}[x_i^2] \mathbb{E}[y_i^2] \end{equation}\) 又因为期望为 0,方差为 1 $\Rightarrow \mathbb{E}[x_i^2] = \mathrm{Var}(x_i) = 1$,同理 $\mathbb{E}[y_i^2] = 1$。因此: \(\begin{equation} \mathbb{E}[x_i^2 y_i^2] = 1 \end{equation}\) 最终得到: \(\begin{equation} \mathrm{Var}(s) = \mathbb{E}[s^2] = \sum_{i=1}^d 1 = d \end{equation}\) 因此,为了使点积的方差为 1,需要对其缩放 $1 / \sqrt{d}$。
b. 乘入写入强度
接下来,进行的是:
v_beta = value * beta.unsqueeze(-1) # (batch_size, num_heads, seq_len, head_v_dim)
k_beta = key * beta.unsqueeze(-1) # (batch_size, num_heads, seq_len, head_k_dim)
它将写入强度 $\beta$ 与 kv 相乘,具体来说,是每个头的每个 token的所有维度,乘上各自对应的 $\beta$,这两部操作相当于实现的是如下公式中的红色部分:
然后进行形状变换和构造 mask:
# reshape 成 chunks
# (batch_size, num_heads, num_chunks, chunk_size, head_k/v_dim)
query, key, value, k_beta, v_beta = [x.reshape(x.shape[0], x.shape[1], -1, chunk_size, x.shape[-1]) for x in (query, key, value, k_beta, v_beta)]
g = g.reshape(g.shape[0], g.shape[1], -1, chunk_size) # (batch_size, num_heads, num_chunks, chunk_size)
# 创建包含主对角线的上三角矩阵,上三角及对角线为 True,下三角为 False
mask = torch.triu(torch.ones(chunk_size, chunk_size, dtype=torch.bool, device=query.device), diagonal=0)
相当于先分头,再分 chunk,最终我们的计算操作是在大小为 chunk_size 的序列上。此外,构建一个包含主对角线的上三角矩阵,上三角及对角线为 True,下三角为 False,后面会用到。
c. 构造 decay mask
前面我们讲过,g 是用于计算 $\alpha$ 的,只需对其进行 exp 操作即可。但是在公式中,我们没有用到单一的 $\alpha$,用的是累计衰减 $\gamma$,因此这里我们先对 g 进行累加,累加后再进行 exp 则相当于进行了累乘,这把多个矩阵乘法简化为了矩阵加法。
g = g.cumsum(dim=-1) # (batch_size, num_heads, num_chunks, chunk_size)
其中,cumsum 用于计算累计和,例如 g = [g0, g1, g2, ...],则 cumsum(g) = [g0, g0+g1, g0+g1+g2, ...]。注意 g 在此时已经分成了 chunk,因此这里的累计和是从每个 chunk 的起点开始的。而后构造 decay mask $\mathbb{\Gamma}$:
decay_mask = ((g.unsqueeze(-1) - g.unsqueeze(-2)).tril().exp().float()).tril()
这一步相当于:
\(\begin{equation}
\begin{aligned}
\mathbf{\Gamma}_{[t]} &=
\begin{cases}
\frac{\gamma^r_{[t]} }{\gamma^i_{[t]} }, & i \leq r \\
0, & i > r
\end{cases} &\in \mathbb{R}^{C \times C}
\end{aligned}
\end{equation}\)
只看 g 的最后两维度,进行 (g.unsqueeze(-1) - g.unsqueeze(-2)) 操作,相当于 (..., chunk_size, 1) - (..., 1, chunk_size) = (..., chunk_size, chunk_size),得到每个位置对其他各位置的相对累计和。对该相对累计和取下三角,然后取 exp,就得到每个位置对先前位置的衰减比值。注意在 exp 后还需要再进行一次 tril,因为 exp 会把第一次 tril 的上三角 0 变为 exp(0) = 1,因此需要再进行一次 tril 保证上三角为 0。因此对应于上面的公式,decay_mask[r,i] 表示从位置 i 的写入会衰减到当前位置 r。
d. 严格下三角系统求逆
在如下公式中:
\(\begin{equation}
\widetilde{\mathbf{U}_{[t]} } = \left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{V}_{[t]} \in \mathbb{R}^{C \times d_v}
\end{equation}\)
其中,$\text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right)$ 是严格下三角系统,即对角线全 0,且只在对角线下方可能非 0。$\mathbf{\Gamma}_{[t]}$ 是给 $\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}$ 的每个元素乘上对应的衰减比值,$\text{diag}(\beta_{[t]})$ 是给 $\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}$ 的每行乘上对应的 $\beta$,它们都是以相乘的形式作用在 $\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}$ 上的,因此它等价于 $\text{strictLower}\left( \mathbf{\Gamma}_{[t]} \odot \left( \text{diag}(\beta_{[t]}) (\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right)$,也可以写为 $\text{strictLower}\left( \mathbf{\Gamma}_{[t]} \odot \left( \left[ {\color{red}{ \text{diag}(\beta_{[t]}) \mathbf{K}_{[t]} } } \right] \mathbf{K}^\top_{[t]} \right) \right)$,其中的红色部分就是我们先前计算过的 k_beta。因此,这里的严格下三角系统可以通过 k_beta 与 key 的转置相乘,然后再与 decay_mask 相乘得到:
# (batch_size, num_heads, num_chunks, chunk_size, chunk_size)
attn = -((k_beta @ key.transpose(-1, -2)) * decay_mask).masked_fill(mask, 0)
这里对相乘的结果应用了之前构造的 mask,确保结果是严格下三角。此外,在结果前加了一个负号,这是为了方便求逆:$\left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1}$。关于这部分求逆,我们需要详细讲解一下:
首先了解一下 Neumann 级数,对于标量,我们知道当 $|x| < 1$ 时: \(\begin{equation} \frac{1}{1 - x} = 1 + x + x^2 + x^3 + \cdots = \sum_{k=0}^{\infty} x^k \end{equation}\) 把上面的标量 $x$ 换成矩阵 $\mathbf{A}$,就有类似的结果,当谱半径 $\rho(\mathbf{A}) < 1$ 时有: \(\begin{equation} (\mathbf{I} - \mathbf{A})^{-1} = \mathbf{I} + \mathbf{A} + \mathbf{A}^2 + \mathbf{A}^3 + \cdots = \sum_{k=0}^{\infty} \mathbf{A}^k \end{equation}\) 换个角度看,我们定义部分和: \(\begin{equation} \mathbf{S}_N = \sum_{k=0}^{N} \mathbf{A}^k \end{equation}\) 则有: \(\begin{equation} \begin{aligned} (\mathbf{I} - \mathbf{A}) \mathbf{S}_N = \mathbf{S}_N - \mathbf{A} \mathbf{S}_N &= (\mathbf{I} + \mathbf{A} + \cdots + \mathbf{A}^N) - (\mathbf{A} + \mathbf{A}^2 + \cdots + \mathbf{A}^{N+1}) \\ &= \mathbf{I} - \mathbf{A}^{N+1} \end{aligned} \end{equation}\) 因此,只要 $A^{N+1} \to 0$,就有: \(\begin{equation} (\mathbf{I} - \mathbf{A}) \mathbf{S} = \mathbf{I} \quad \Rightarrow \quad \mathbf{S} = (\mathbf{I} - \mathbf{A})^{-1} \end{equation}\) 现在我们假设 $\mathbf{L} \in \mathbb{R}^{n \times n}$ 是严格下三角矩阵。严格下三角矩阵有一个关键性质:它是幂零矩阵,即 $L^n = 0$,因此对 $k > n$ 的项都为 0。在这里我们要求的是 $(\mathbf{I} + \mathbf{L})^{-1}$,我们只需令 $\mathbf{A} = -\mathbf{L}$ 即可,因此有: \(\begin{equation} (\mathbf{I} + \mathbf{L})^{-1} = (\mathbf{I} - (-\mathbf{L}))^{-1} = \mathbf{I} - \mathbf{L} + \mathbf{L}^2 - \mathbf{L}^3 + \cdots + (-1)^{n-1} \mathbf{L}^{n-1} \end{equation}\) 它是一个有限和,从这里我们可以看出,$\mathbf{I} + \mathbf{L}$ 是一个单位下三角矩阵(对角线全为 1),并且 $(\mathbf{I} + \mathbf{L})^{-1}$ 是由 $\mathbf{I}$ 和若干 $\mathbf{L}$ 的高阶进行求和计算,因此也是一个单位下三角矩阵。
然而直接计算会引入多次的矩阵乘法,在实现中通常使用迭代的方法求解。定义 $\mathbf{T} = (\mathbf{I} - \mathbf{A})^{-1}$,其中 $\mathbf{A} = -\mathbf{L}$ 是严格下三角矩阵,此外,由于 $\mathbf{T}$ 是单位下三角矩阵,定义 $\widetilde{\mathbf{T} } = \mathbf{T} - \mathbf{I}$,它是 $\mathbf{T}$ 的严格下三角部分,因此有 $\widetilde{\mathbf{T} }_{i,i} = 0$。可以推出: \(\begin{equation} \begin{aligned} & \quad \mathbf{T} = (\mathbf{I} - \mathbf{A})^{-1} \\ \Rightarrow & \quad (\mathbf{I} - \mathbf{A}) \mathbf{T} = \mathbf{I} \\ \Rightarrow & \quad \mathbf{T} = \mathbf{I} + \mathbf{A} \mathbf{T} \\ \Rightarrow & \quad \widetilde{\mathbf{T} } = \mathbf{A} \widetilde{\mathbf{T} } + \mathbf{A} \end{aligned} \end{equation}\) 其中: \(\begin{align} \widetilde{\mathbf{T} } &= \begin{bmatrix} 0 & 0 & 0 & \cdots & 0 & 0\\ \widetilde{T}_{2,1} & 0 & 0 & \cdots & 0 & 0\\ \widetilde{T}_{3,1} & \widetilde{T}_{3,2} & 0 & \cdots & 0 & 0\\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots\\ \widetilde{T}_{n-1,1} & \widetilde{T}_{n-1,2} & \widetilde{T}_{n-1,3} & \cdots & 0 & 0 \\ \widetilde{T}_{n,1} & \widetilde{T}_{n,2} & \widetilde{T}_{n,3} & \cdots & \widetilde{T}_{n,n-1} & 0 \end{bmatrix} \\ \mathbf{A} &= \begin{bmatrix} 0 & 0 & 0 & \cdots & 0 & 0\\ A_{2,1} & 0 & 0 & \cdots & 0 & 0\\ A_{3,1} & A_{3,2} & 0 & \cdots & 0 & 0\\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots\\ A_{n-1,1} & A_{n-1,2} & A_{n-1,3} & \cdots & 0 & 0 \\ A_{n,1} & A_{n,2} & A_{n,3} & \cdots & A_{n,n-1} & 0 \end{bmatrix} \end{align}\) 对于 $\widetilde{\mathbf{T} } = \mathbf{A} \widetilde{\mathbf{T} } + \mathbf{A}$ 的第 $i$ 行和前 $i-1$ 列(即取第 $i$ 行的严格下三角那段),得到行向量方程: \(\begin{equation} \boxed{ \widetilde{\mathbf{T} }_{i,1:i-1} = \mathbf{A}_{i,1:i-1} + \mathbf{A}_{i,1:i-1} \widetilde{\mathbf{T} }_{1:i-1,1:i-1} } \end{equation}\) 现在来看代码:
for i in range(1, chunk_size):
row = attn[..., i, :i].clone() # row = \mathbf{A}_{i,1:i-1}
sub = attn[..., :i, :i].clone() # sub = \widetilde{\mathbf{T} }_{1:i-1,1:i-1}
attn[..., i, :i] = row + (row.unsqueeze(-1) * sub).sum(-2)
attn = attn + torch.eye(chunk_size, dtype=attn.dtype, device=attn.device)
注意,代码里的 i 从 1 开始循环,相当于公式中 $i$ 从第二行开始(代码中的索引 0 是公式中的 $i=1$,因此索引从 1 开始,是公式中的 $i=2$)。代码里的 sub 就是 $\widetilde{\mathbf{T} }_{1:i-1,1:i-1}$,row 就是 $\mathbf{A}_{i,1:i-1}$,循环开始前,attn 相当于是 $\mathbf{A}$,即 $- \mathbf{L}$,这也就是为什么代码中要给 attn 前加一个负号。循环进行时,左上角 attn[..., :i, :i] 已经被更新为 $\widetilde{\mathbf{T} }_{1:i-1,1:i-1}$,当前行 attn[..., i, :i] 还没更新,仍然是 $\mathbf{A}_{i,1:i-1}$。其中,刚进入循环时,由于 $\widetilde{\mathbf{T} }_{1:1,1:1} = \mathbf{A}_{1:1,1:1} = 0$,这相当于迭代的初值。循环结束后,attn 被逐行替换成了 $\widetilde{\mathbf{T} }$,因此直接再加上单位矩阵把 $\widetilde{\mathbf{T} }$ 变成 $\mathbf{T} = \widetilde{\mathbf{T} } + \mathbf{I}$,这也就求得了 $(\mathbf{I} + \mathbf{L})^{-1}$。
e. 计算 $\widetilde{\mathbf{U}_{[t]} }$ 和 $\overleftarrow{\mathbf{W}_{[t]} }$
当前我们主要是为了求 $\widetilde{\mathbf{U}_{[t]} }$ 和 $\overleftarrow{\mathbf{W}_{[t]} }$,再将其公式写一遍:
\[\begin{align} \widetilde{\mathbf{U}_{[t]} } &= {\color{red}{\left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} }} {\color{green}{\text{diag}(\beta_{[t]}) \mathbf{V}_{[t]} }} &\in \mathbb{R}^{C \times d_v} \\ \overleftarrow{\mathbf{W}_{[t]} } &= \text{diag}(\gamma^i_{[t]}) \mathbf{W}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \mathbf{W}_{[t]} &= \left[ \mathbf{I} + \text{strictLower} \left( \text{diag}(\beta_{[t]}) (\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} {\color{green}{\text{diag}(\beta_{[t]}) \mathbf{K}_{[t]} }} &\in \mathbb{R}^{C \times d_k} \end{align}\]其中,红色部分是我们经过迭代求得的 attn,绿色部分是最开始求得的 k_beta 和 v_beta。可见,$\widetilde{\mathbf{U}_{[t]} }$ 可以很轻松的计算得到,这里代码中用 value 表示:
# (I + strictLower(diag(β)·(Γ⊙(K·K^T))))^(-1) @ (diag(β)·V) 由此得到 U 矩阵
value = attn @ v_beta # (batch_size, num_heads, num_chunks, chunk_size, head_v_dim)
接下来求 $\overleftarrow{\mathbf{W}_{[t]} }$,上面我们实现的是 $(\mathbf{I} + \mathbf{L})^{-1}$ 即 $\left[\mathbf{I} + \text{strictLower}(\text{diag}(\beta)(\mathbf{\Gamma} \odot \mathbf{K} \mathbf{K}^\top))\right]^{-1}$,其中 $\mathbf{\Gamma}$ 是:
\(\begin{equation}
\mathbf{\Gamma}_{ij} =
\begin{cases}
\gamma_i / \gamma_j, & i \geq j \\
0, & i < j
\end{cases}
\end{equation}\)
但它和 $\left[\mathbf{I} + \text{strictLower}(\text{diag}(\beta)(\mathbf{K} \mathbf{K}^\top))\right]^{-1}$ 仍不同,差了一个 decay_mask,如果再进行一遍类似上述过程的迭代求逆也是可以的,但代码中使用了一个更为巧妙的简化过程。定义对角矩阵:
\(\begin{equation}
\mathbf{D} \triangleq \mathrm{diag}(\gamma_1, \ldots, \gamma_C), \quad \mathbf{D}^{-1} = \mathrm{diag}(1/\gamma_1, \ldots, 1/\gamma_C)
\end{equation}\)
在 $\text{diag}(\beta)(\mathbf{\Gamma} \odot \mathbf{K} \mathbf{K}^\top)$ 中,对任意两个行向量 $k_i,k_j$ 有:
\(\begin{equation}
\frac{\gamma_i}{\gamma_j} (\beta_i k_i^\top k_j) = (\gamma_i \beta_i k_i)^\top \left( \frac{1}{\gamma_j} k_j \right)
\end{equation}\)
因此在矩阵形式下:
\(\begin{equation}
\mathbf{\Gamma} \odot \mathbf{K}_{\beta} \mathbf{K}^\top = (\mathbf{D} \mathbf{K}_{\beta})(\mathbf{D}^{-1} \mathbf{K})^\top = \mathbf{D} \mathbf{K}_{\beta} \mathbf{K}^\top \mathbf{D}^{-1}
\end{equation}\)
其中 $\mathbf{K}_{\beta}$ 是 $\text{diag}(\beta) \mathbf{K}$,也就是 k_beta。因此,求得的 attn 可以写为:
\(\begin{equation}
(\mathbf{I} + \mathbf{L})^{-1} = (\mathbf{I} + \mathbf{D} \mathbf{K}_{\beta} \mathbf{K}^\top \mathbf{D}^{-1})^{-1} = (\mathbf{I} + \mathbf{D} \mathbf{L}_0 \mathbf{D}^{-1})^{-1}
\end{equation}\)
其中,$\mathbf{L}_0 = \mathbf{K}_{\beta} \mathbf{K}^\top$,它就是求 $\overleftarrow{\mathbf{W}_{[t]} }$ 时使用的严格下三角系统 $\text{strictLower}(\text{diag}(\beta)(\mathbf{K} \mathbf{K}^\top))$。根据矩阵求逆的反序律,有:
\(\begin{equation}
\begin{aligned}
(\mathbf{I} + \mathbf{D} \mathbf{L}_0 \mathbf{D}^{-1})^{-1} &= (\mathbf{D} \mathbf{D}^{-1} + \mathbf{D} \mathbf{L}_0 \mathbf{D}^{-1})^{-1} \\
&= (\mathbf{D} (\mathbf{I} + \mathbf{L}_0) \mathbf{D}^{-1})^{-1} \\
&= \mathbf{D} (\mathbf{I} + \mathbf{L}_0)^{-1} \mathbf{D}^{-1}
\end{aligned}
\end{equation}\)
代码中直接用以下方式求 $\overleftarrow{\mathbf{W}_{[t]} }$ :
k_cumdecay = attn @ (k_beta * g.exp().unsqueeze(-1)) # (batch_size, num_heads, num_chunks, chunk_size, head_k_dim)
这是因为:
\(\begin{equation}
\begin{aligned}
(\mathbf{I} + \mathbf{L})^{-1} \mathbf{D} \mathbf{K}_{\beta} &=
(\mathbf{I} + \mathbf{D} \mathbf{K}_{\beta} \mathbf{K}^\top \mathbf{D}^{-1})^{-1} \mathbf{D} \mathbf{K}_{\beta} \\
&= (\mathbf{I} + \mathbf{D} \mathbf{L}_0 \mathbf{D}^{-1})^{-1} \mathbf{D} \mathbf{K}_{\beta} \\
&= \mathbf{D} (\mathbf{I} + \mathbf{L}_0)^{-1} \mathbf{D}^{-1} \mathbf{D} \mathbf{K}_{\beta} \\
& = \mathbf{D} (\mathbf{I} + \mathbf{L}_0)^{-1} \mathbf{K}_{\beta}
\end{aligned}
\end{equation}\)
这就相当于一步得到了:
\(\begin{align}
\overleftarrow{\mathbf{W} }_{[t]} &= \mathrm{diag}(\gamma_{[t]}^i) \mathbf{W}_{[t]} \\
\mathbf{W}_{[t]} &= \left[ \mathbf{I} + \mathrm{strictLower} \left( \mathrm{diag}(\beta_{[t]}) (\mathbf{K}_{[t]} \mathbf{K}_{[t]}^\top) \right) \right]^{-1} \mathrm{diag}(\beta_{[t]}) \mathbf{K}_{[t]}
\end{align}\)
其中,$(\mathbf{I} + \mathbf{L})^{-1}$ 是之前求得的 attn;$\mathbf{D} \mathbf{K}_{\beta}$ 相当于 k_beta * g.exp().unsqueeze(-1);$\mathbf{D}$ 是 $\mathrm{diag}(\gamma_{[t]}^i)$;$(\mathbf{I} + \mathbf{L}_0)^{-1}$ 是 $\left[ \mathbf{I} + \mathrm{strictLower} \left( \mathrm{diag}(\beta_{[t]}) (\mathbf{K}_{[t]} \mathbf{K}_{[t]}^\top) \right) \right]^{-1}$;$\mathbf{K}_{\beta}$ 是 $\mathrm{diag}(\beta_{[t]}) \mathbf{K}_{[t]}$。代码中这样的实现避免了再求一次 $\mathbf{I} + \mathbf{L}_0$ 的逆。
f. 逐 chunk 计算状态和输出
上面我们已经计算完成所有公式中如下标红的部分,接下来是逐 chunk 计算状态矩阵和输出:
\[\begin{align} \mathbf{S}_{[t+1]} &= \overrightarrow{\mathbf{S}_{[t]} } + \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right)^\top \overrightarrow{\mathbf{K}_{[t]} } &\in \mathbb{R}^{d_v \times d_k} \\ \mathbf{O}_{[t]} &= \overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}_{[t]}^\top + \left( \mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top \odot \mathbf{\Gamma} \right) \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right) &\in \mathbb{R}^{C \times d_v} \\ \color{red}{\widetilde{\mathbf{U}_{[t]} }} & \color{red}{= \left[ \mathbf{I} + \text{strictLower}\left( \text{diag}(\beta_{[t]}) (\mathbf{\Gamma}_{[t]} \odot \mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{V}_{[t]} } &\in \mathbb{R}^{C \times d_v} \\ \color{red}{\mathbf{\Gamma}_{[t]} } & \color{red}{= \begin{cases} \frac{\gamma^r_{[t]} }{\gamma^i_{[t]} }, & i \leq r \\ 0, & i > r \end{cases} } &\in \mathbb{R}^{C \times C} \\ \color{red}{\overleftarrow{\mathbf{W}_{[t]} }} & \color{red}{= \text{diag}(\gamma^i_{[t]}) \mathbf{W}_{[t]} } &\in \mathbb{R}^{C \times d_k} \\ \color{red}{\mathbf{W}_{[t]} } & \color{red}{= \left[ \mathbf{I} + \text{strictLower} \left( \text{diag}(\beta_{[t]}) (\mathbf{K}_{[t]} \mathbf{K}^\top_{[t]}) \right) \right]^{-1} \text{diag}(\beta_{[t]}) \mathbf{K}_{[t]} } &\in \mathbb{R}^{C \times d_k} \\ \overrightarrow{\mathbf{S}_{[t]} } &= \gamma_{[t]}^C \mathbf{S}_{[t]} &\in \mathbb{R}^{d_v \times d_k} \\ \overrightarrow{\mathbf{K}_{[t]} } &= \text{diag}(\frac{\gamma^C_{[t]} }{\gamma^i_{[t]} }) \mathbf{K}_{[t]} &\in \mathbb{R}^{C \times d_k} \\ \overleftarrow{\mathbf{Q}_{[t]} } &= \text{diag}(\gamma^i_{[t]}) \mathbf{Q}_{[t]} &\in \mathbb{R}^{C \times d_k} \end{align}\]首先进行初始化和变量准备:
last_recurrent_state = (
torch.zeros(batch_size, num_heads, k_head_dim, v_head_dim).to(value)
if initial_state is None
else initial_state.to(value)
)
# 初始化输出张量 (batch_size, num_heads, num_chunks, chunk_size, head_v_dim)
core_attn_out = torch.zeros_like(value)
# 创建一个不包含主对角线的上三角矩阵(严格上三角),上三角为 True,下三角及对角线为 False
mask = torch.triu(torch.ones(chunk_size, chunk_size, dtype=torch.bool, device=query.device), diagonal=1)
而后逐 chunk 计算:
# 逐 chunk 计算状态和输出
for i in range(0, total_sequence_length // chunk_size):
...
现在进入循环,首先取出每个 chunk 的 qkv 矩阵:
# (batch_size, num_heads, chunk_size, head_k/v_dim)
q_i, k_i, v_i = query[:, :, i], key[:, :, i], value[:, :, i]
而后计算下式中的红色、绿色、蓝色部分:
\[\begin{equation} \mathbf{O}_{[t]} = {\color{blue}{\overleftarrow{\mathbf{Q}_{[t]} } \mathbf{S}_{[t]}^\top} } + {\color{red}{\left( \mathbf{Q}_{[t]} \mathbf{K}_{[t]}^\top \odot \mathbf{\Gamma} \right)} } {\color{green}{\left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right)} } \end{equation}\]红色部分为:
# (batch_size, num_heads, chunk_size, chunk_size)
attn = (q_i @ k_i.transpose(-1, -2) * decay_mask[:, :, i]).masked_fill_(mask, 0)
可见,此时 attn 具有了新的含义,应用 masked_fill_(mask, 0) 是为了严格确保因果关系。
绿色部分为:
# 计算 WS^T,相当于 v_old (batch_size, num_heads, chunk_size, head_v_dim)
v_prime = (k_cumdecay[:, :, i]) @ last_recurrent_state
# U - WS^T,即等效 value (batch_size, num_heads, chunk_size, head_v_dim)
v_new = v_i - v_prime
蓝色部分为:
# 计算 QS^T,其中 Q 是衰减到 chunk 起点的 (batch_size, num_heads, chunk_size, head_v_dim)
attn_inter = (q_i * g[:, :, i, :, None].exp()) @ last_recurrent_state
其中,q_i * g[:, :, i, :, None].exp() 就是在计算:
\(\begin{equation}
\overleftarrow{\mathbf{Q}_{[t]} } = \text{diag}(\gamma^i_{[t]}) \mathbf{Q}_{[t]}
\end{equation}\)
然后计算 chunk 输出 $\mathbf{O}_{[t]}$:
# chunk 输出 (batch_size, num_heads, chunk_size, head_v_dim)
core_attn_out[:, :, i] = attn_inter + attn @ v_new
计算 chunk 结束时的状态矩阵:
# 计算 chunk 的状态 S (batch_size, num_heads, head_k_dim, head_v_dim)
last_recurrent_state = (
last_recurrent_state * g[:, :, i, -1, None, None].exp() # 取 g 在 chunk_size 上的最后一个值,并取 exp,即 \gamma^C,使得 S 衰减到 chunk 终点
+ (k_i * (g[:, :, i, -1, None] - g[:, :, i]).exp()[..., None]).transpose(-1, -2) @ v_new # 这里对 K 进行 \gamma^i 到 \gamma^C 的衰减
)
其中,last_recurrent_state * g[:, :, i, -1, None, None].exp() 是在计算:
\(\begin{equation}
\overrightarrow{\mathbf{S}_{[t]} } = \gamma_{[t]}^C \mathbf{S}_{[t]}
\end{equation}\)
(k_i * (g[:, :, i, -1, None] - g[:, :, i]).exp()[..., None]).transpose(-1, -2) 是在计算:
\(\begin{equation}
\overrightarrow{\mathbf{K}_{[t]} } = \text{diag}(\frac{\gamma^C_{[t]} }{\gamma^i_{[t]} }) \mathbf{K}_{[t]}
\end{equation}\)
最终得到本 chunk 的结束状态,即下一个 chunk 的初始状态:
\(\begin{equation}
\mathbf{S}_{[t+1]} = \overrightarrow{\mathbf{S}_{[t]} } + \left( \widetilde{\mathbf{U}_{[t]} } - \overleftarrow{\mathbf{W}_{[t]} } \mathbf{S}_{[t]}^\top \right)^\top \overrightarrow{\mathbf{K}_{[t]} }
\end{equation}\)
g. 结尾形状变换
最后变换成形状并返回结果,很简单:
if not output_final_state:
last_recurrent_state = None
# 恢复形状为 (batch_size, num_heads, total_seq_len, head_v_dim)
core_attn_out = core_attn_out.reshape(core_attn_out.shape[0], core_attn_out.shape[1], -1, core_attn_out.shape[-1])
core_attn_out = core_attn_out[:, :, :sequence_length] # 裁剪有效输出,去掉 pad 部分
core_attn_out = core_attn_out.transpose(1, 2).contiguous().to(initial_dtype) # (batch_size, seq_len, num_heads, head_v_dim)
(2) 逐步递推
逐步递推即 self.recurrent_gated_delta_rule 部分,它通过函数 torch_recurrent_gated_delta_rule 实现,主要用于 decode 阶段,其完整代码如下:
def torch_recurrent_gated_delta_rule(
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
g: torch.Tensor,
beta: torch.Tensor,
initial_state: Optional[torch.Tensor] = None,
output_final_state: bool = False,
use_qk_l2norm_in_kernel: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""
递归 Gated Delta Rule, 用于 decode 阶段的逐步计算
Args:
query (torch.Tensor): 查询张量 (batch_size, seq_len, num_heads, head_k_dim)
key (torch.Tensor): 键张量 (batch_size, seq_len, num_heads, head_k_dim)
value (torch.Tensor): 值张量 (batch_size, seq_len, num_heads, head_v_dim)
g (torch.Tensor): 遗忘门 log 值 (batch_size, seq_len, num_heads), exp(g) 为实际衰减系数
beta (torch.Tensor): 写入门 (batch_size, seq_len, num_heads), 控制写入强度
initial_state (Optional[torch.Tensor]): 初始循环状态 (batch_size, num_heads, head_k_dim, head_v_dim)
output_final_state (bool): 是否输出最终状态, 用于缓存
use_qk_l2norm_in_kernel (bool): 是否对 query/key 做 L2 归一化
Returns:
Tuple[torch.Tensor, Optional[torch.Tensor]]:
- 注意力输出 (batch_size, seq_len, num_heads, head_v_dim)
- 最终循环状态 (batch_size, num_heads, head_k_dim, head_v_dim), 若 output_final_state=False 则为 None
"""
initial_dtype = query.dtype
# 使用 L2 Norm
if use_qk_l2norm_in_kernel:
query = l2norm(query, dim=-1, eps=1e-6)
key = l2norm(key, dim=-1, eps=1e-6)
# 将 seq_len 维度与 num_heads 维度互换,并转换为 fp32
query, key, value, beta, g = [x.transpose(1, 2).contiguous().to(torch.float32) for x in (query, key, value, beta, g)]
# 变量准备,此时的 num_k_heads 已经经过 repeat 与 num_v_heads 相同,均使用 num_heads 表示
batch_size, num_heads, sequence_length, k_head_dim = key.shape
v_head_dim = value.shape[-1]
scale = 1 / (query.shape[-1] ** 0.5)
query = query * scale
# 初始化输出张量和循环状态
core_attn_out = torch.zeros(batch_size, num_heads, sequence_length, v_head_dim).to(value) # (batch_size, num_heads, seq_len, head_v_dim)
last_recurrent_state = (
torch.zeros(batch_size, num_heads, k_head_dim, v_head_dim).to(value) # (batch_size, num_heads, head_k_dim, head_v_dim)
if initial_state is None
else initial_state.to(value)
)
# 逐时间步计算状态和输出
for i in range(sequence_length):
q_t = query[:, :, i] # (batch_size, num_heads, head_k_dim)
k_t = key[:, :, i] # (batch_size, num_heads, head_k_dim)
v_t = value[:, :, i] # (batch_size, num_heads, head_v_dim)
g_t = g[:, :, i].exp().unsqueeze(-1).unsqueeze(-1) # (batch_size, num_heads, 1, 1)
beta_t = beta[:, :, i].unsqueeze(-1) # (batch_size, num_heads, 1)
# 这里的计算过程与经典公式相比,稍微进行了一点变换,具体见本人手撕 Qwen3-Next 的博客
last_recurrent_state = last_recurrent_state * g_t # 将 α 吸收进状态中,后续过程可以看作是 DeltaNet (batch_size, num_heads, head_k_dim, head_v_dim)
kv_mem = (last_recurrent_state * k_t.unsqueeze(-1)).sum(dim=-2) # 相当于S_{t-1}·k,得到 v_old (batch_size, num_heads, head_v_dim)
delta = (v_t - kv_mem) * beta_t # 得到 β(v - v_old) (batch_size, num_heads, head_v_dim)
last_recurrent_state = last_recurrent_state + k_t.unsqueeze(-1) * delta.unsqueeze(-2) # S_t = S_{t-1} + β(v - v_old)·k^T (batch_size, num_heads, head_k_dim, head_v_dim)
core_attn_out[:, :, i] = (last_recurrent_state * q_t.unsqueeze(-1)).sum(dim=-2) # S_t·q,得到最终输出 (batch_size, num_heads, head_v_dim)
if not output_final_state:
last_recurrent_state = None
core_attn_out = core_attn_out.transpose(1, 2).contiguous().to(initial_dtype) # (batch_size, seq_len, num_heads, head_v_dim)
return core_attn_out, last_recurrent_state
可见,代码的前半段基本与 chunkwise 相同,主要区别在于后半部分的循环。回顾一下 Gated DeltaNet 的逐步递推公式:
\(\begin{equation}
\mathbf{S}_t = \mathbf{S}_{t-1} (\alpha_t (\mathbf{I} - \beta_t k_t k_t^\top)) + \beta_t v_t k_t^\top \label{eq:gated_delta_net}
\end{equation}\)
首先吸收 $\alpha$,即 last_recurrent_state = last_recurrent_state * g_t,这样一来可以将接下来的步骤视为 DeltaNet,对于 DeltaNet,有:
\(\begin{equation}
\mathbf{S}_t = \mathbf{S}_{t-1} - \underbrace{({\color{red}{\mathbf{S}_{t-1} k_t} })}_{v_t^{\text{old} }} k_t^\top + \underbrace{(\beta_t v_t + (1 - \beta_t) \mathbf{S}_{t-1} k_t)}_{v_t^{\text{new} }} k_t^\top = \mathbf{S}_{t-1} (\mathbf{I} - \beta_t k_t k_t^\top) + \beta_t v_t k_t^\top
\end{equation}\)
即当前的 k 可以从旧状态中进行寻址,找到 v_old,即上式红色部分,代码实现即:
kv_mem = (last_recurrent_state * k_t.unsqueeze(-1)).sum(dim=-2)
而后,按照如下流程简化 DeltaNet 的计算: \(\begin{equation} \begin{aligned} \mathbf{S}_t &= \mathbf{S}_{t-1} - v_t^{\text{old} } k_t^\top + v_t^{\text{new} } k_t^\top \\ &= \mathbf{S}_{t-1} - v_t^{\text{old} } k_t^\top + \left[ \beta_t v_t + (1 - \beta_t) v_t^{\text{old} } \right] k_t^\top \\ &= \mathbf{S}_{t-1} - v_t^{\text{old} } k_t^\top + \left[ \beta_t (v_t - v_t^{\text{old} }) + v_t^{\text{old} } \right] k_t^\top \\ &= \mathbf{S}_{t-1} - v_t^{\text{old} } k_t^\top + \beta_t (v_t - v_t^{\text{old} }) k_t^\top + v_t^{\text{old} } k_t^\top \\ &= \mathbf{S}_{t-1} + \beta_t (v_t - v_t^{\text{old} }) k_t^\top \end{aligned} \end{equation}\)
因此代码中实现为:
# 得到 β(v - v_old) (batch_size, num_heads, head_v_dim)
delta = (v_t - kv_mem) * beta_t
# S_t = S_{t-1} + β(v - v_old)·k^T (batch_size, num_heads, head_k_dim, head_v_dim)
last_recurrent_state = last_recurrent_state + k_t.unsqueeze(-1) * delta.unsqueeze(-2)
跟新状态后可以得到输出:
# S_t·q,得到最终输出 (batch_size, num_heads, head_v_dim)
core_attn_out[:, :, i] = (last_recurrent_state * q_t.unsqueeze(-1)).sum(dim=-2)
最终经过形状变换并返回输出。
6. 输出调整
经过上述计算,最终进行输出门控和形状调整并得到输出,不再赘述:
# 记录原始形状
z_shape_og = z.shape # (batch_size, seq_len, num_v_heads, head_v_dim)
# 转换为 2D 张量
core_attn_out = core_attn_out.reshape(-1, core_attn_out.shape[-1]) # (batch_size * seq_len * num_v_heads, head_v_dim)
z = z.reshape(-1, z.shape[-1]) # (batch_size * seq_len * num_v_heads, head_v_dim)
core_attn_out = self.norm(core_attn_out, z) # RMSNorm + Gate
core_attn_out = core_attn_out.reshape(z_shape_og) # (batch_size, seq_len, num_v_heads, head_v_dim)
core_attn_out = core_attn_out.reshape(core_attn_out.shape[0], core_attn_out.shape[1], -1) # (batch_size, seq_len, value_dim)
output = self.out_proj(core_attn_out) # (batch_size, seq_len, hidden_size)
(二)Gated Attention
此部分参考 【论文解读】Gated Attention,其基本思想就是经过大量的对比实验,发现 gate 应用在标准注意力的输出投影前,可以有效提升性能。其代码实现基本与标准注意力一致,不同时加入了 qk norm 和输出门控,这里不再贴出代码。
(三)Cache
由于 Qwen3-Next 是混合架构,因此其 Cache 类的实现需要同时保存标准注意力的 kv cache 和线性注意力的 状态矩阵,此外,线性注意力还要保存前几个 conv_state。这里仅列出其初始化的部分,方便了解其缓存的内部结构:
class MiniQwen3NextDynamicCache:
"""
MiniQwen3Next 的动态缓存, 可以同时缓存标准注意力层的 kv cache 和线性注意力层的 conv_state 和 recurrent state
该缓存包含两组张量列表:
- key_cache 和 value_cache 用于标准注意力
- conv_states 和 recurrent_states 用于线性注意力
每组列表包含 num_layers 个张量,各张量的预期形状如下:
- 对于标准注意力层:
- key_cache 和 value_cache 的形状为 (batch_size, num_heads, seq_len, head_dim)
- conv_states 和 recurrent_states 的形状为 (batch_size, 0) (空张量)
- 对于线性注意力层:
- key_cache 和 value_cache 的形状为 (batch_size, 0) (空张量)
- conv_states 表示卷积状态,形状为 (batch_size, conv_dim, conv_kernel_size)
- recurrent_states 表示循环状态,形状为 (batch_size, num_heads, head_k_dim, head_v_dim)
"""
is_compileable = False # 显式声明无需编译
def __init__(self, config: MiniQwen3NextConfig):
super().__init__()
self.layer_types = config.layer_types
self.transformer_layers = [i for i in range(config.num_hidden_layers) if self.layer_types[i] == "full_attention"] # 标准注意力层索引
self.last_linear_layer = len(self.layer_types) - 1 - self.layer_types[::-1].index("linear_attention") # 找到最后一个线性注意力层的索引
# 全部初始化为 None
self.conv_states = [None for _ in range(config.num_hidden_layers)]
self.recurrent_states = [None for _ in range(config.num_hidden_layers)]
self.key_cache = [None for _ in range(config.num_hidden_layers)]
self.value_cache = [None for _ in range(config.num_hidden_layers)]
其具体方法的实现请参考仓库代码。
二、极致稀疏 MoE
在 mini_deepseekv3 中,我们已经介绍并实现了 MoE 架构,因此这里不过多介绍。其代码上基本原理类似,实现上有些许差异。需说明的是,本项目的目标仅是 100-200M 的小模型,其能力本身有限,因此在实现时不特意考虑 MoE 的激活比例。
另外,本项目修改了源码中的负载均衡函数,修改后的代码如下:
def load_balancing_loss_func(
gate_logits: list[dict] | None,
num_experts: int | None = None,
top_k: int | None = None,
attention_mask: torch.Tensor | None = None,
) -> torch.Tensor | int:
"""
计算负载均衡损失, 参考 Switch Transformer (https://huggingface.co/papers/2101.03961) 中的公式 (4)-(6)
Args:
gate_logits: 所有专家层的门控 logits, 每层的形状是 (batch_size * seq_len, num_experts)
num_experts: 专家数量
top_k: 选中的专家数量
attention_mask: 注意力掩码 (batch_size, seq_len)
Returns:
负载均衡辅助损失
"""
if not gate_logits:
return 0
compute_device = gate_logits[0]["router_logits"].device
# NOTE: transformers 中 Qwen3-Next 的负载均衡将每层的 logits 拼接成 (batch_size * seq_len * layers, num_experts) 的形状
# 个人认为这样的计算方式会导致负载均衡是基于整个模型的,而不是每层的,可能出现对某个专家 id,它在某层激活极高,而另一层几乎不激活,但在整个模型中却具有合适的 f_i,P_i,这是不合理的
# 因此这里我们分层计算 f_i 和 P_i,然后求和得到最终的损失
# 实际上,DeepSeekV3 的序列级辅助损失就是对此的进一步细分,在序列上计算 f_i 和 P_i
overall_loss = 0
for layer_gate in gate_logits:
layer_gate_logits = layer_gate["router_logits"].to(compute_device) # (batch_size * seq_len, num_experts)
# 计算每个专家的选中概率 (batch_size * seq_len, num_experts)
routing_weights = F.softmax(layer_gate_logits, dtype=torch.float, dim=-1)
# 获取选中的专家索引 (batch_size * seq_len, top_k)
_, selected_experts = torch.topk(routing_weights, top_k, dim=-1)
# 转换为 one-hot 向量 (batch_size * seq_len, top_k, num_experts)
expert_mask = F.one_hot(selected_experts, num_classes=num_experts)
if attention_mask is None: # 所有 token 选的专家都进行计算
# 计算每个专家作为 top 几的平均被选中次数 (top_k, num_experts) 即 f_i
# 若果再沿 top_k 维度求和,则是每个专家总的平均被选中次数,在最后的 torch.sum 中实现了这种求和
tokens_per_expert = torch.mean(expert_mask.float(), dim=0)
# 计算每个专家在所有 token 上的平均概率 (num_experts,) 即 P_i
router_prob_per_expert = torch.mean(routing_weights, dim=0)
else: # 仅计算关注序列的 token 选的专家
batch_size, sequence_length = attention_mask.shape
# 计算与 expert_mask 形状相同的 mask (batch_size * seq_len, top_k, num_experts)
expert_attention_mask = (
attention_mask[:, :, None, None]
.expand((batch_size, sequence_length, top_k, num_experts))
.reshape(-1, top_k, num_experts)
.to(compute_device)
)
# 计算 f_i,只计算有效 token
tokens_per_expert = torch.sum(expert_mask.float() * expert_attention_mask, dim=0) / torch.sum(expert_attention_mask, dim=0)
# 计算与 routing_weights 形状相同的 mask (batch_size * seq_len, num_experts)
router_per_expert_attention_mask = (
attention_mask[:, :, None]
.expand((batch_size, sequence_length, num_experts))
.reshape(-1, num_experts)
.to(compute_device)
)
# 计算 P_i,只计算有效 token
router_prob_per_expert = torch.sum(routing_weights * router_per_expert_attention_mask, dim=0) / torch.sum(router_per_expert_attention_mask, dim=0)
# 相当于完成了 top_k 方向的求和和 i=1 到 N 的求和
# 理想情况下,每个专家被选中的频率为 top_k / num_experts,每个专家被选中的概率为 1 / num_experts
# 所有专家的 f_i 和 P_i 的乘积之和为 ∑(f_i * P_i) = top_k / num_experts
# 乘以 num_experts / top_k 以统一尺度后,每层的理想 loss 则为 1
loss = torch.sum(tokens_per_expert * router_prob_per_expert.unsqueeze(0))
loss = loss * num_experts / top_k # 乘 N 以统一尺度
overall_loss += loss
return overall_loss / len(gate_logits) # 平均层数,将最终 aux_loss 归一化为 1,方便在不同设置下比较
其中,注释中已经进行了基本说明,即源代码的负载均衡损失函数是针对整个模型进行计算的,这可能导致整个模型的专家总数看上去是均衡的,但实际上各层的专家并不均衡,即某个 id 的专家在不同层的激活差异很大,但是在整个模型的激活却是接近平均的。修改后的损失函数,按照各层的来计算,这样就不会导致不同层专家激活差异过大。如下图所示:
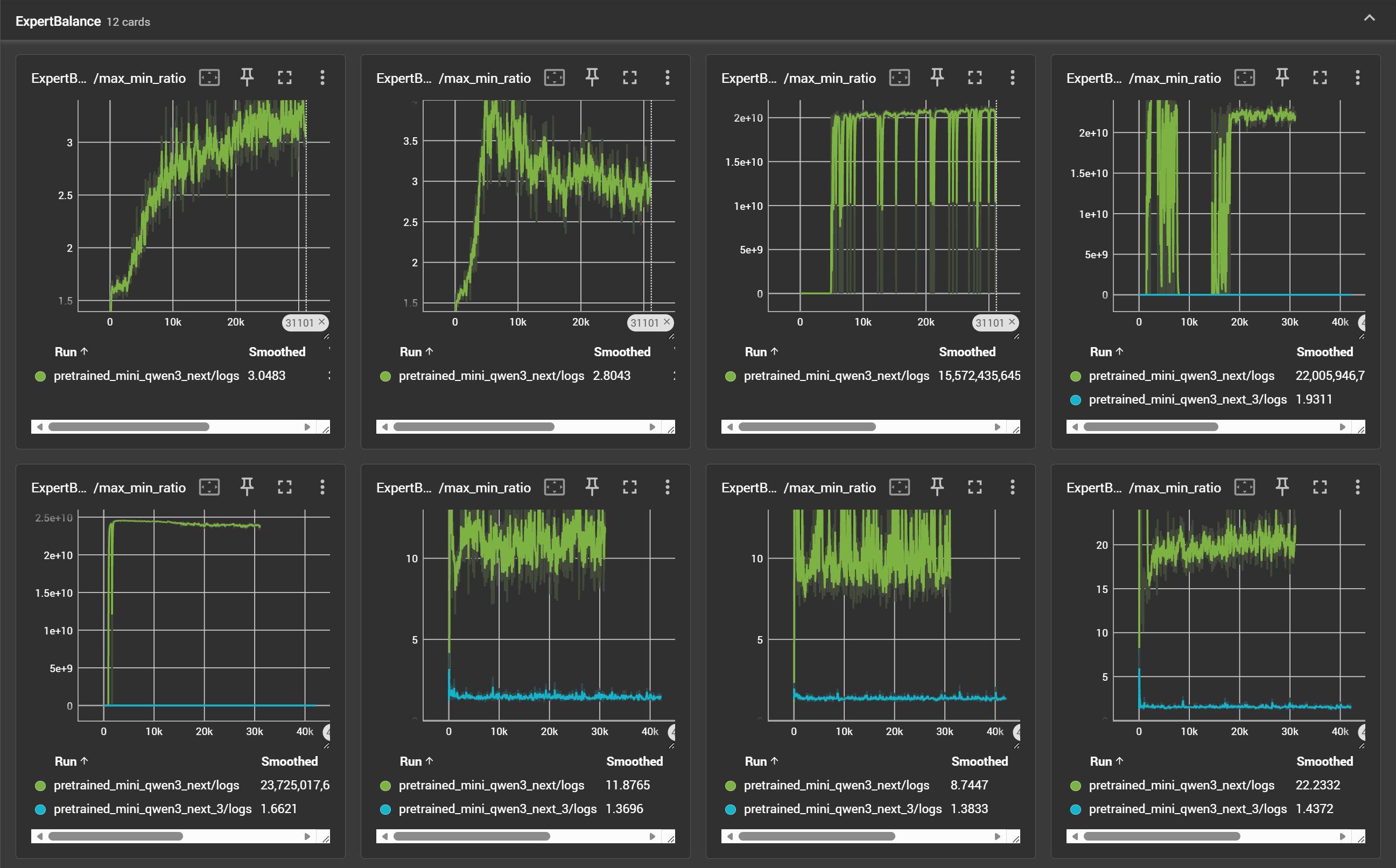
其中,曲线含义是每层的最大专家激活次数与最小专家激活次数的比值,理想的均衡情况下,此比值应当等于 1。绿色曲线代表源代码中的训练情况,蓝色曲线代表修改后的训练情况,可以看出,修改后每层的专家激活更加均衡。实际上,DeepSeekV3 中的序列级负载均衡,就是对此的进一步细化。此外,由于模型较小,为了使路由网络能够更好的学习,本项目把前三层 MoE 修改为普通 MLP。
当然,实际的 Qwen3-Next 应该使用了更复杂的训练策略,这里的修改仅供参考。
三、训练稳定性友好设计
这里重点介绍代码中使用的 Zero-Centered RMSNorm。RMSNorm 的核心是:用均方根做缩放,不减均值。Zero-Centered RMSNorm 在此基础上做了一个小改动:把可学习的缩放参数改成以 1 为中心的偏移参数。
给定输入向量 $x \in \mathbb{R}^d$,标准 RMSNorm 是: \(\begin{equation} \text{RMSNorm}(x) = \frac{x}{\text{rms}(x) + \epsilon} \odot g, \quad \text{where} \quad \text{rms}(x) = \sqrt{\frac{1}{d} \sum_{i=1}^{d} x_i^2} \end{equation}\) 其中,$g \in \mathbb{R}^d$ 是可学习的缩放参数 (gain),通常初始化为全 1。
Zero-Centered RMSNorm 把输出写成: \(\begin{equation} \text{ZC-RMSNorm}(x) = \frac{x}{\text{rms}(x) + \epsilon} \odot (1 + g) \end{equation}\) 这里的 $g$ 仍是可学习参数,但初始化为 0,使得一开始 $(1 + g) = 1$,这也是 zero-centered 的含义:学习到的缩放偏移 $g$ 以 0 为中心。官方博客是这样讲的:
在Qwen3中我们采用了QK-Norm,我们发现部分层的 norm weight 值会出现异常高的现象。为了缓解这一现象,进一步提高模型的稳定性,我们在Qwen3-Next中采用了 Zero-Centered RMSNorm,并在此基础上,对 norm weight 施加 weight decay,以避免权重无界增长。
通常不会对标准 RMSNorm 应用 weight decay ,因此 $g$ 可能会过大导致训练不稳定。使用 Zero-Centered 时,其初始化是等价的,但可以对其应用 weight decay ,此时会把 $g$ 往 0 拉,$(1+g)$ 会倾向于回到 1,避免了过度缩放。
其代码实现也很简单:
class ZeroCenteredRMSNorm(nn.Module):
"""
零中心均方根归一化 (Zero-Centered Root Mean Square Layer Normalization, Zero-Centered RMSNorm)
与 RMSNorm 不同的是, 初始化参数为 0, 缩放系数为 (1 + weight)
Args:
dim (int): 嵌入维度
eps (float): Epsilon 值用于确保数值稳定性, 默认为 1e-6
"""
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.zeros(dim)) # 初始化参数为 0
def _norm(self, x: torch.Tensor) -> torch.Tensor:
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Zero-Centered RMSNorm 前向传播, 在dim维度上进行归一化
Args:
x (torch.Tensor): 输入张量
Returns:
torch.Tensor: 归一化后的输出
"""
output = self._norm(x.float())
output = output * (1.0 + self.weight.float())
return output.type_as(x)
训练时,可以对其应用 weight decay:
# 对 ZeroCenteredRMSNorm 应用权重衰减
zero_centered_norm_params = set()
for _, m in model.named_modules():
if m.__class__.__name__ == "ZeroCenteredRMSNorm":
for p in m.parameters():
zero_centered_norm_params.add(p)
for name, param in param_dict.items():
if param in zero_centered_norm_params:
decay_params.append(param)
elif param.dim() < 2 or "bias" in name:
no_decay_params.append(param)
else:
decay_params.append(param)
此部分完整代码参考仓库的 train/utils.py。
四、Multi-Token Prediction
此部分 mini_qwen3_next 偷个懒,暂未实现 MTP,可以参考 mini_deepseekv3 中 MTP 的实现 【手撕系列】手撕DeepSeek-V3。不过,mini_deepseekv3 中的 MTP 也只是作为增强主干模型能力的辅助模块,训练后丢弃。后续有机会可以实现一下基于 MTP 的 Speculative Decoding。
总结
实现 Qwen3-Next 总的来说最核心的部分还是在于 Gated DeltaNet,尤其是其中的 chunkwise 递推部分,可以想象如果继续深入 flash linear attention,还会有大量的推导和优化可以学习,后续有机会再进一步深入。总之,注意到官方博客中最后提到:展望未来,我们将持续优化这一架构,开发 Qwen3.5,致力于实现更高的智能水平与生产力。可见这一架构还是值得持续跟进的。